










Budowanie odpornych systemów oprogramowania wymaga więcej niż tylko pisania kodu funkcjonalnego. Wymaga to strukturalnego podejścia do zarządzania cyklem życia danych i procesów. Maszyna stanów to podstawowy narzędzie do tego, zapewniające jasny schemat, jak system przechodzi z jednego stanu do drugiego. Gdy integruje się diagramy stanów z trwałym przechowywaniem danych i zewnętrznymi usługami, złożoność znacznie rośnie. Ten przewodnik bada wzorce techniczne wymagane do skutecznego połączenia logiki stanów z operacjami bazy danych i interakcjami z interfejsami API.
Maszyny stanów to nie tylko konstrukcje teoretyczne; są to praktyczne realizacje, które określają przepływ danych. Niezależnie od zarządzania przetwarzaniem zamówień, onboardowaniem użytkowników czy automatyzacją przepływów pracy, integralność stanu jest kluczowa. Integracja tej logiki z bazami danych zapewnia trwałość zmian stanów. Łączenie z interfejsami API pozwala systemowi reagować na zewnętrzne sygnały. Niniejszy dokument szczegółowo opisuje rozważania architektoniczne, wzorce implementacji oraz strategie ograniczania ryzyka w tej integracji.
Zrozumienie architektury głównej 🧩
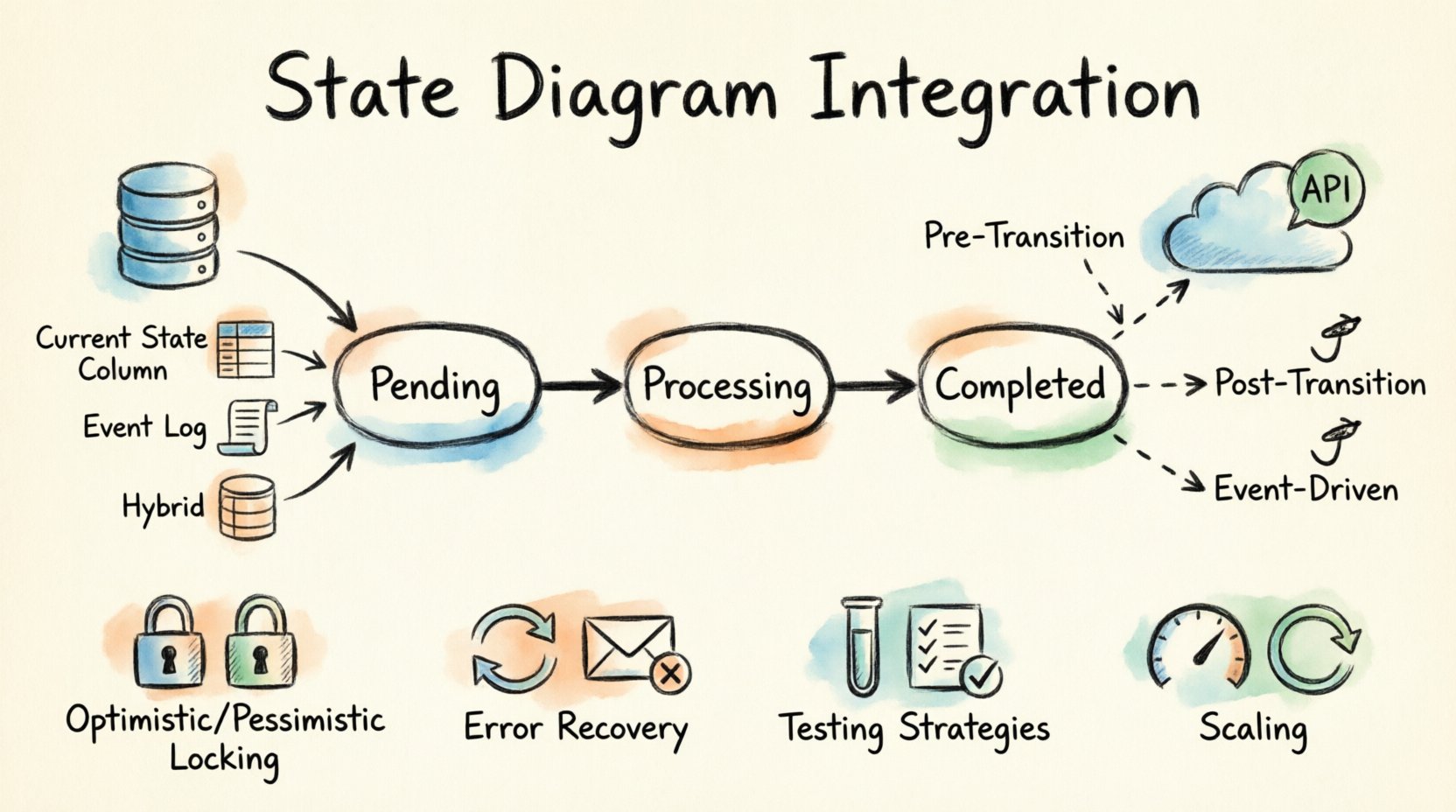
Zanim przejdziemy do trwałości i logiki sieciowej, konieczne jest zdefiniowanie zaangażowanych komponentów. Maszyna stanów składa się z trzech podstawowych elementów: stanów, przejść i zdarzeń. Zrozumienie, jak te elementy oddziałują z systemami zewnętrznymi, stanowi podstawę integracji.
- Stany: Odpowiadają stanowi jednostki w konkretnym momencie. Przykłady toOczekujące, Przetwarzanie, lubZakończone.
- Przejścia: Przejście z jednego stanu do drugiego wywołane zdarzeniem. Tutaj stosuje się logikę.
- Zdarzenia: Sygnały wywołujące przejście. Mogą pochodzić z działań wewnętrznych systemu lub wywołań interfejsów API zewnętrznych.
Podczas integracji stan musi być widoczny dla bazy danych, a przejścia muszą być w stanie wywoływać wywołania interfejsów API. Tworzy to łańcuch zależności, w którym baza danych przechowuje prawdę, a interfejs API obsługuje skutki uboczne.
Strategie trwałości bazy danych 🗄️
Trwałość to proces przechowywania bieżącego stanu, aby przetrwał restart systemu lub jego awarię. Sposób przechowywania stanu wpływa na wydajność, spójność i możliwości odzyskiwania. Istnieje kilka wzorców mapowania węzłów diagramu stanów na wiersze bazy danych.
Przechowywanie bieżącego stanu
Najczęściej stosowanym podejściem jest przechowywanie identyfikatora bieżącego stanu w dedykowanej kolumnie w tabeli głównej rekordów. Pozwala to na szybkie pobieranie bez przeszukiwania dzienników.
- Realizacja: Dodaj kolumnę
statuslubstate_codedo głównej tabeli encji. - Zalety:Szybka wydajność odczytu podczas sprawdzania bieżącego statusu.
- Ryzyko:Jeśli logika stanu jest złożona, pojedyncza kolumna może nie uwzględnić całego niezbędnego kontekstu.
Przechowywanie dziennika zdarzeń
W niektórych architekturach stan aktualny nie jest przechowywany bezpośrednio. Zamiast tego, sekwencja zdarzeń jest przechowywana w dzienniku. Stan aktualny jest wyprowadzany poprzez ponowne odtworzenie zdarzeń.
- Wdrożenie:Dołącz zdarzenie do tabeli za każdym razem, gdy występuje przejście.
- Zalety:Pełny ślad audytowy oraz możliwość odtworzenia historii.
- Ryzyko:Obliczanie stanu aktualnego wymaga przetworzenia całego dziennika, co może być wolniejsze.
Porównanie modeli przechowywania danych
| Model | Wydajność odczytu | Złożoność zapisu | Możliwość audytu |
|---|---|---|---|
| Kolumna stanu aktualnego | Wysoka | Niska | Niska |
| Dziennik zdarzeń | Średnia (wymaga ponownego odtworzenia) | Średnia | Wysoka |
| Hybrydowy | Wysoka | Średnia | Średnia |
Model hybrydowy jest często preferowany. Przechowuje stan aktualny do szybkiego dostępu, jednocześnie utrzymując dziennik zdarzeń do audytu. Zapewnia to, że system wie, gdzie się znajduje teraz, ale także wie, jak do tego doszło.
Ograniczenia i integralność bazy danych
Zapewnienie integralności danych jest kluczowe. Baza danych powinna wymuszać zasady zapobiegające nieprawidłowym przejściom stanów. Choć logika aplikacji jest głównym strażnikiem, ograniczenia bazy danych stanowią sieć bezpieczeństwa.
- Sprawdź ograniczenia: Zdefiniuj poprawne wartości dla kolumny stanu.
- Klucze obce: Połącz dzienniki stanu z głównym obiektem, aby zapewnić integralność referencyjną.
- Transakcje: Zawijaj aktualizacje stanu i powiązane zmiany danych w jednej transakcji, aby zapewnić atomowość.
Integracja z API i zewnętrzną logiką 🔗
Przejścia stanu często wymagają działania. Gdy system przechodzi z Oczekujące do Przetwarzanie, może być konieczne wysłanie powiadomienia, naliczenie opłaty lub aktualizacja systemu inwentarzowego. Te działania są obsługiwane za pomocą interfejsów API.
Wyzwalanie wywołań zewnętrznych
Wywołania interfejsu API powinny być wyzwalane na podstawie logiki przejścia. Zapewnia to, że efekty uboczne występują tylko wtedy, gdy zmiana stanu jest poprawna.
- Wtyczki przed przejściem: Sprawdź warunki zewnętrzne przed zezwoleniem na zmianę stanu.
- Wtyczki po przejściu: Wykonaj logikę po pomyślnej zatwierdzeniu stanu.
- Wtyczki oparte na zdarzeniach: Nasłuchuj zdarzeń zmiany stanu i reaguj asynchronicznie.
Obsługa niepowodzeń interfejsu API
Wywołania sieciowe są niepewne. Jeśli wywołanie interfejsu API nie powiedzie się podczas przejścia stanu, system musi zdecydować, jak postępować. Pozostawienie stanu w niejasnej pozycji może spowodować uszkodzenie danych.
- Transakcje kompensacyjne: Jeśli działanie nie powiedzie się, wywołaj cofnięcie lub określony stan, aby oznaczyć niepowodzenie (np. Niepowodzenie lub Ponów).
- Logika ponownych prób: Zaimplementuj wykładnicze opóźnienie dla błędów tymczasowych.
- Idempotentność: Upewnij się, że ponowne wywołanie wywołania interfejsu API nie powoduje powstawania duplikatów rekordów ani opłat.
Wzorce żądań
| Wzorzec | Przypadek użycia | Złożoność |
|---|---|---|
| Synchroniczny | Wymagana natychmiastowa odpowiedź | Niska |
| Asynchroniczny | Długotrwałe zadania | Średnia |
| Wystrzel i zapomnij | Powiadomienia | Niska |
Wywołania synchroniczne blokują przejście stanu do momentu odpowiedzi interfejsu API. Jest to proste, ale może prowadzić do wygaśnięcia czasu oczekiwania. Wywołania asynchroniczne pozwalają natychmiast zaktualizować stan, a pracownik przetwarza zewnętrzne żądanie później. Pozwala to rozdzielić logikę stanu od opóźnień spowodowanych zależnościami zewnętrznymi.
Zrównoleglenie i warunki wyścigu 🔄
Gdy wiele procesów jednocześnie próbuje zmienić stan tej samej jednostki, mogą wystąpić warunki wyścigu. Jest to powszechne w systemach rozproszonych, gdzie żądania przychodzą przez różne punkty końcowe interfejsu API.
Optymistyczne blokowanie
Optymistyczne blokowanie zakłada, że konflikty są rzadkie. Używa numeru wersji lub znacznika czasu do wykrywania zmian.
- Logika: Odczytaj bieżącą wersję. Zaktualizuj rekord nowym stanem i zwiększonym numerem wersji.
- Konflikt: Jeśli aktualizacja nie wpływa na żadne wiersze, inny proces zmodyfikował rekord. Transakcja jest cofnięta.
- Zalety: Wysoka przepustowość dla systemów o niskim poziomie zawieszeń.
Pesymistyczne blokowanie
Pesymistyczne blokowanie zakłada, że konflikty są prawdopodobne. Blokuje rekord przed jego odczytaniem.
- Logika: Uzyskaj wyłączny blok na wierszu. Wykonaj aktualizację. Zwolnij blokadę.
- Konflikt: Inne procesy czekają, aż blokada zostanie zwolniona.
- Zalety: Gwarantuje kolejność operacji.
- Ryzyko: Może prowadzić do zakleszczeń, jeśli nie jest odpowiednio zarządzane.
Zarządzanie stanem oparte na kolejce
Aby całkowicie uniknąć problemów współbieżności, przekieruj wszystkie żądania zmiany stanu przez jedną kolejkę.
- Wdrożenie: Wszystkie żądania interfejsu API dodają zdarzenie do kolejki komunikatów.
- Przetwarzanie: Jeden pracownik przetwarza zdarzenia sekwencyjnie dla określonego identyfikatora jednostki.
- Zalety: Eliminuje warunki wyścigu zgodnie z projektem.
Obsługa błędów i odzyskiwanie 🛡️
Błędy są nieuniknione. Warstwa integracji musi je obsługiwać, nie pozostawiając maszyny stanów w uszkodzonym stanie.
Granice transakcji
Zdefiniuj, gdzie transakcja zaczyna się i kończy. Powszechnym błędem jest zatwierdzanie stanu bazy danych przed powodzeniem wywołania interfejsu API. Powoduje to stan, w którym baza danych mówi „Zakończone”, ale zewnętrzny serwis nigdy nie otrzymał żądania.Zakończone, ale zewnętrzny serwis nigdy nie otrzymał żądania.
- Zatwierdzenie dwufazowe: Upewnij się, że baza danych i zewnętrzny serwis zgadzają się co do wyniku.
- Spójność ostateczna: Przyjmij, że spójność może być opóźniona, ale upewnij się, że istnieje mechanizm do jej naprawy.
Kolejki listów martwych
Jeśli wywołanie interfejsu API nie powiedzie się wielokrotnie, przenieś zdarzenie do kolejki listów martwych. Zapobiega to niekończącemu się obrotowi w pętli ponownych prób.
- Powiadomienia: Powiadamiaj inżynierów, gdy elementy trafiają do kolejki listów martwych.
- Wmieszanie ręczne: Pozwól operatorom ponowić próbę lub odrzucić nieudane zdarzenia.
Testowanie i weryfikacja 🧪
Testowanie maszyn stanów jest złożone, ponieważ liczba możliwych ścieżek rośnie wykładniczo. Solidna strategia testowa obejmuje logikę, punkty integracji oraz scenariusze awarii.
Testy jednostkowe logiki stanów
Przetestuj maszynę stanów niezależnie od bazy danych i interfejsu API.
- Wejście/Wyjście:Przekaż zdarzenie i zweryfikuj wynikowy stan.
- Nieprawidłowe przejścia:Upewnij się, że nieprawidłowe zdarzenia są odrzucane.
- Pokrycie kodu:Dąż do 100% pokrycia reguł przejść stanów.
Testy integracyjne
Przetestuj przepływ z mockami bazy danych i interfejsu API.
- Schemat bazy danych:Zweryfikuj, czy aktualizacje stanu odpowiadają schematowi.
- Mocki interfejsu API:Symuluj odpowiedzi interfejsu API (powodzenie, błąd, przekroczenie czasu) w celu testowania obsługi błędów.
- Od końca do końca:Uruchom pełny przepływ pracy od początku do końca w środowisku testowym.
Testy mutacji
Zamierzone uszkodzenie kodu, aby sprawdzić, czy testy wykryją błąd.
- Zmiany logiki:Usuń przejście stanu i zweryfikuj, że test nie powiedzie się.
- Zmiany danych:Zmień stan bazy danych i zweryfikuj, że system go odrzuci.
Skalowanie i wydajność 🚀
W miarę wzrostu systemu maszyna stanów musi obsługiwać większy obciążenie bez pogorszenia wydajności.
Buforowanie stanu
Odczytywanie stanu z bazy danych przy każdym żądaniu może być powolne. Bufory w pamięci mogą zmniejszyć opóźnienie.
- Strategia:Buforuj bieżący stan dla określonego identyfikatora jednostki.
- Anulowanie: Upewnij się, że pamięć podręczna jest anulowana natychmiast po zmianie stanu.
- Spójność: Zaakceptuj tymczasowe niezgodności, jeśli współczynnik trafień pamięci podręcznej jest wysoki.
Fragmentacja bazy danych
Jeśli liczba encji jest duża, podziel bazę danych na wiele fragmentów na podstawie identyfikatora encji.
- Zalety: Rozdziela obciążenie na wielu serwerach.
- Wyzwanie: Złożone zapytania obejmujące fragmenty stają się trudne.
Utrzymanie i wersjonowanie 📝
Maszyny stanów się rozwijają. Dodawane są nowe stany, a stare są wycofywane. Zarządzanie tym rozwojem jest kluczowe dla długoterminowej stabilności.
Wersjonowanie logiki stanu
Przechowuj wersję logiki maszyny stanów razem z danymi stanu.
- Zgodność: Upewnij się, że starsze dane mogą być odczytane przez nowe wersje.
- Migracja: Napisz skrypty aktualizujące istniejące rekordy do nowego schematu.
Strategia wycofania
Gdy usuwasz stan, nie usuwaj go od razu.
- Oznacz jako przestarzały: Dodaj flagę wskazującą, że stan jest przestarzały.
- Zablokuj przejścia: Zapobiegaj nowym przejściom do stanu przestarzałego.
- Oczyszczanie: Usuń definicję stanu dopiero po tym, jak wszystkie dane zostaną przeprowadzone.
Dokumentacja
Utrzymuj wizualny diagram zgodny z kodem. Pomaga to nowym programistom zrozumieć system.
- Narzędzia do tworzenia diagramów: Używaj narzędzi, które mogą generować diagramy z kodu lub konfiguracji.
- Dzienniki zmian: Dokumentuj każdą zmianę w diagramie stanów w historii wersji.
Zagadnienia bezpieczeństwa 🔐
Przejścia stanów często wiążą się z danymi poufnymi. Bezpieczeństwo musi być zintegrowane na warstwie integracji.
- Autoryzacja: Upewnij się, że użytkownik żądający zmiany stanu ma uprawnienia do tej konkretnej transakcji.
- Weryfikacja danych: Oczyszczaj wszystkie dane wejściowe przed przetworzeniem zmiany stanu.
- Rejestrowanie: Rejestruj zmiany stanów w celu audytu bezpieczeństwa, ale upewnij się, że dane poufne są ukrywane.
Podsumowanie najlepszych praktyk
- Przechowuj bieżący stan w bazie danych dla szybkiego dostępu.
- Rejestruj wszystkie zdarzenia w celu audytu i odtworzenia.
- Używaj transakcji, aby zapewnić atomowość między aktualizacjami stanu a wywołaniami interfejsu API.
- Zaimplementuj logikę ponownych prób z wykładniczym odstawieniem dla niepowodzeń interfejsu API.
- Używaj blokady optymistycznej do efektywnego obsługi równoległych aktualizacji.
- Testuj wszystkie przejścia stanów, w tym nieprawidłowe.
- Wersjonuj logikę stanów, aby zarządzać ich ewolucją w czasie.
Śledząc te wzorce, programiści mogą tworzyć maszyny stanów odpornych, skalowalnych i łatwych w utrzymaniu. Integracja między logiką stanów, bazami danych i interfejsami API stanowi fundament niezawodnych procesów biznesowych. Poprawny projekt na tym poziomie zapobiega uszkodzeniu danych i zapewnia przewidywalne zachowanie systemu pod obciążeniem.