











Podczas modelowania złożonych systemów kluczowym celem jest jasność. Diagramy przepływu danych (DFD) są podstawowym narzędziem do wizualizacji ruchu informacji w systemie. W tym kontekście dwa symbole dominują obraz: Proces oraz Magazyn danych. Choć często wzajemnie się oddziałują, reprezentują fundamentalnie różne koncepcje dotyczące przekształcania i trwałego przechowywania danych. Zrozumienie tej różnicy jest kluczowe dla dokładnej analizy i projektowania systemu.
Ten przewodnik bada role funkcjonalne, reprezentacje wizualne oraz implikacje logiczne tych elementów. Oddzielając działanie od przechowywania, analitycy mogą tworzyć diagramy, które jednoznacznie przekazują zachowanie systemu.
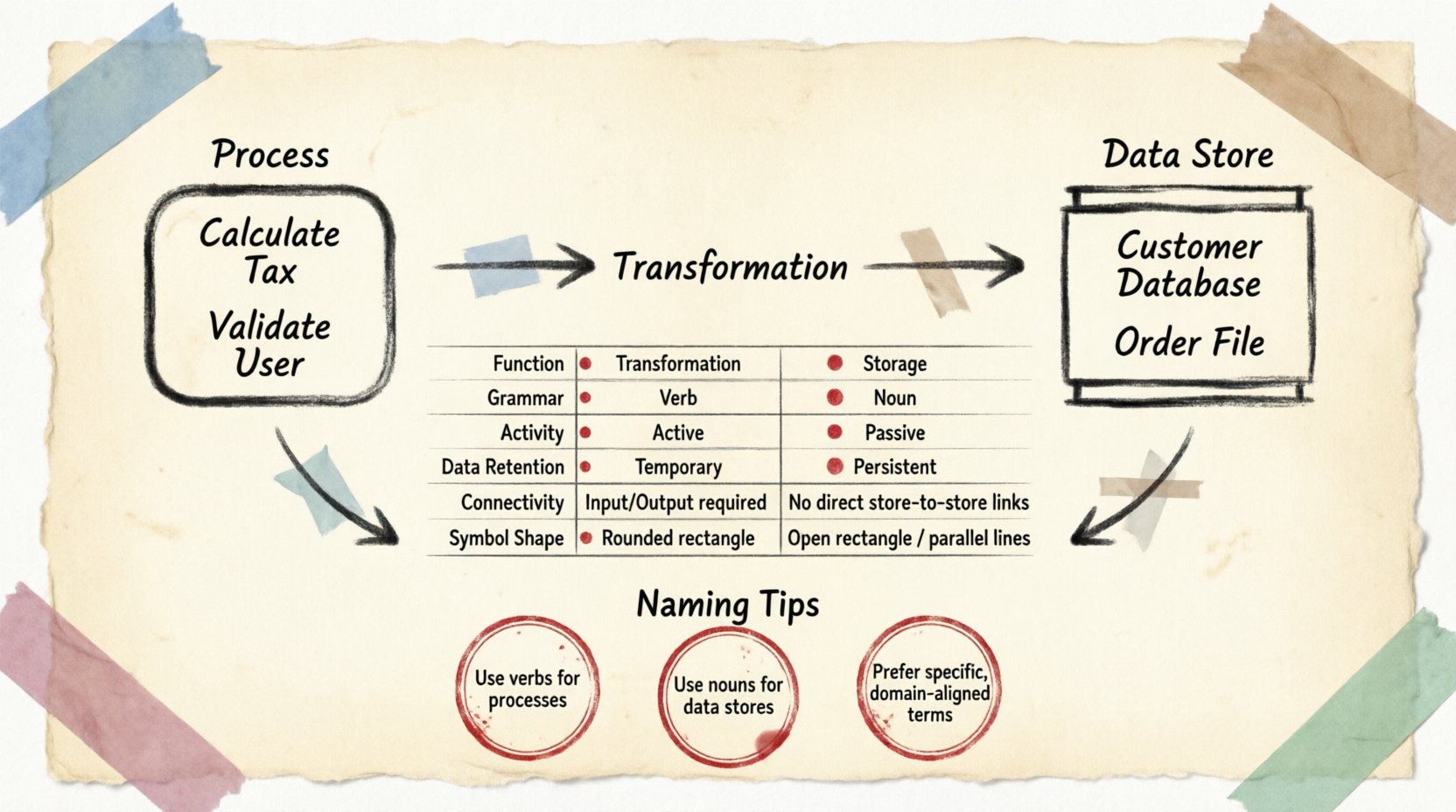
🔄 Definiowanie procesu
Proces reprezentuje jednostkę pracy lub przekształcenia. Jest to miejsce, w którym dane zmieniają formę, są obliczane lub filtrowane. Traktuj proces jak pudełko czarne. Wiesz, co wchodzi i co wychodzi, ale mechanizm wewnętrzny jest określony przez logikę przekształcenia, a nie przez przechowywanie tej informacji.
🔹 Kluczowe cechy
- Przekształcenie: Główną funkcją jest modyfikacja danych. Dane wejściowe wchodzą, stosuje się zasady lub logikę, a dane wyjściowe opuszczają proces.
- Charakter czasowy: Procesy są aktywne wyłącznie wtedy, gdy są wyzwolone. Nie przechowują danych między wykonaniami.
- Kierunkowość: Dane przepływają do i z procesu. Proces bez danych wejściowych lub wyjściowych jest logicznie niepoprawny w kontekście DFD.
- Nazewnictwo czasownikowe: Procesy są zwykle oznaczane czasownikami lub frazami czasownikowymi (np. Oblicz podatek, Weryfikuj użytkownika, Generuj raport).
🔹 Koncepcja pudełka czarnego
W modelowaniu najwyższego poziomu proces jest pudełkiem czarnym. Skupia się na tym, co dzieje się z danymi, a nie na tym, jak to się dzieje technicznie. Na przykład proces o nazwie „Przetwarzanie zamówienia” pobiera dane o zamówieniu i tworzy rekord transakcji. Nie określa, czy obliczenia są wykonywane w pamięci, na dysku czy za pomocą zdalnego interfejsu API. Ta abstrakcja pozwala stakeholderom skupiać się na logice biznesowej, a nie na implementacji technicznej.
Jednak w miarę jak diagramy rozkładają się na niższe poziomy, logika wewnętrzna staje się bardziej szczegółowa. Nawet wtedy proces nadal pozostaje silnikiem aktywnego przekształcenia. Pobiera dane wejściowe, wykonuje pracę i generuje dane wyjściowe. Nie pełni roli zbiornika przechowywania tych informacji.co dzieje się z danymi, a nie jak dzieje się technicznie. Na przykład proces o nazwie „Przetwarzanie zamówienia” pobiera dane o zamówieniu i tworzy rekord transakcji. Nie określa, czy obliczenia są wykonywane w pamięci, na dysku czy za pomocą zdalnego interfejsu API. Ta abstrakcja pozwala stakeholderom skupiać się na logice biznesowej, a nie na implementacji technicznej.
Jednak w miarę jak diagramy rozkładają się na niższe poziomy, logika wewnętrzna staje się bardziej szczegółowa. Nawet wtedy proces nadal pozostaje silnikiem aktywnego przekształcenia. Pobiera dane wejściowe, wykonuje pracę i generuje dane wyjściowe. Nie pełni roli zbiornika przechowywania tych informacji.
🗄️ Definiowanie magazynu danych
Magazyn danych reprezentuje repozytorium, w którym przechowywane są informacje. W przeciwieństwie do procesu, magazyn danych nie przekształca danych. Czeka. Przechowuje dane w trwałym stanie, aż proces je pobierze lub aż proces umieści je tam.
🔹 Kluczowe cechy
- Trwałość: Dane pozostają w magazynie nawet wtedy, gdy nie działają żadne procesy. To jest kluczowa różnica w stosunku do buforów pamięci lub zmiennych tymczasowych.
- Pasywna natura:Magazyny danych nie inicjują działań. Wymagają procesu, który odczytuje z nich lub zapisuje do nich.
- Nazewnictwo rzeczownikowe: Magazyny są zwykle oznaczane rzeczownikami (np. Baza danych klientów, Plik zamówień, Dziennik inwentarza).
- Otwarte: Przepływy danych mogą wchodzić do magazynu i z niego wychodzić. Jednak magazyn nie może być bezpośrednio połączony z innym magazynem. Dane muszą przepływać przez proces, aby przenieść się między repozytoriami.
🔹 Pojęcie repozytorium
Wyobraź sobie bibliotekę. Książki to dane. Półki to magazyny danych. Bibliotekarz to proces. Bibliotekarz nie tworzy książek; organizuje je. Półki same nie przemieszczają książek; trzymają je na miejscu. Gdy czytelnik prosi o książkę, bibliotekarz ją odbiera (operacja odczytu). Gdy przychodzi nowa książka, bibliotekarz kładzie ją na półkę (operacja zapisu).
W architekturze systemu magazyn danych może reprezentować tabelę bazy danych, plik tekstowy, kolejkę lub chmurny kontener. Symbol DFD abstrahuje technologię. Niezależnie czy chodzi o tabelę SQL czy prosty plik tekstowy, rola logiczna jest taka sama: to miejsce, gdzie przechowywane są informacje.
⚡ Interakcja i przepływ danych
Relacja między procesem a magazynem danych regulowana jest ściśle zasadami przepływu danych. Strzałki w DFD reprezentują ruch danych. Te strzałki określają kierunek przekazu informacji.
🔹 Cykl odczytu-zapisu
Gdy proces potrzebuje informacji, rysuje strzałkę od magazynu danych do procesu. Oznacza to operację odczytu. Proces wyodrębnia dane do użycia w logice przekształceń. Z kolei, gdy proces generuje nowe informacje, rysuje strzałkę od procesu do magazynu danych. Oznacza to operację zapisu. Dane są teraz przechowywane do późniejszego użytku.
Kluczowe jest to, że przepływ danych nie może łączyć bezpośrednio dwa magazyny danych. Informacje nie mogą przechodzić z jednego repozytorium do drugiego bez przetworzenia. Ta zasada zapewnia, że przemieszczanie danych zawsze towarzyszy jakikolwiek poziom logiki lub kontroli, nawet jeśli ta logika to prosty przypis.
🔹 Jednostki zewnętrzne
Jednostki zewnętrzne (źródła lub ujścia) interagują z procesami, a nie bezpośrednio z magazynami danych. Jednostka zewnętrzna może być użytkownikiem, interfejsem API zewnętrznej usługi lub innym systemem. Wysyła dane do procesu lub odbiera dane od procesu. Proces następnie decyduje, czy dane te mają być przechowywane w repozytorium, czy usunięte.
📋 Tabela porównawcza
Aby podsumować różnice strukturalne, rozważ następującą analizę cech.
| Cecha | Proces | Magazyn danych |
|---|---|---|
| Funkcja | Przekształcenie / Działanie | Przechowywanie / Pamięć |
| Gramatyka | Czasownik (np. Aktualizuj) | Rzeczownik (np. Tabela Użytkowników) |
| Aktywność | Aktywne (działa po wyzwoleniu) | Pasywne (czeka aż zostanie odwołane) |
| Zachowanie danych | Tymczasowe (podczas wykonywania) | Trwałe (długoterminowe) |
| Łączność | Łączy się z Jednostkami, Magazynami i Innymi Procesami | Łączy się wyłącznie z Procesami |
| Kształt symbolu | Okrągły prostokąt lub okrąg | Otwarty prostokąt lub równoległe linie |
🧩 Zasady nazewnictwa
Spójność w nazewnictwie zapobiega zamieszaniu podczas przeglądania i implementacji. Niejasność często pojawia się, gdy ten sam termin jest używany zarówno dla przechowywania, jak i działania.
🔹 Nazewnictwo procesu
Nazwy powinny opisywać działanie wykonywane na danych. Unikaj ogólnych nazw takich jak „Zrób to” lub „Obsłuż”. Zamiast tego używaj szczegółowych opisów. Na przykład „Weryfikuj dane logowania” jest lepsze niż „Sprawdź logowanie”. Ta jasność pomaga programistom natychmiast zrozumieć oczekiwane wymagania dotyczące danych wejściowych i wyjściowych.
🔹 Nazewnictwo magazynu danych
Nazwy powinny odzwierciedlać zawartość przechowywaną wewnątrz. Używaj liczb mnogiej rzeczowników lub jasnych identyfikatorów. „Orders” oznacza zbiór rekordów zamówień. „Order” może sugerować pojedynczy egzemplarz transakcji. Choć kontekst ma znaczenie, liczba mnoga ogólnie wskazuje na repozytorium zawierające wiele rekordów.
Podczas nadawania nazw magazynom danych należy wziąć pod uwagę zakres. Magazyn o nazwie „Database” jest zbyt ogólny. Nazwy takie jak „Customer Database” lub „Transaction Log” zapewniają potrzebny kontekst. Ta szczegółowość ułatwia mapowanie schematu na struktury fizyczne przechowywania danych w przyszłości.
🧪 Rozkładanie i poziomy
Diagramy przepływu danych (DFD) są hierarchiczne. Diagram najwyższego poziomu (Diagram kontekstowy) przedstawia system jako pojedynczy proces. Podczas rozkładania go na niższe poziomy różnica między procesem a magazynem staje się bardziej istotna.
🔹 Poziom 0 vs. Poziom 1
W Diagramie kontekstowym cały system jest jednym procesem. Na poziomie 0 ten proces jest podzielony na główne podprocesy. Magazyny danych są tu wprowadzane, aby pokazać, gdzie znajdują się główne składniki danych. Na poziomie 1 i wyższych procesy są dalej dopasowywane.
Podczas rozkładania upewnij się, że magazyny danych nie są niepotrzebnie powielane. Jeśli magazyn istnieje na poziomie 0, powinien zazwyczaj istnieć również na poziomie 1, chyba że konkretny podproces wymaga tymczasowego bufora (który byłby innym magazynem). Spójność na różnych poziomach zapewnia śledzenie.
🔹 Zrównoważenie
Kluczowym zasadą w rozkładaniu jest „Zrównoważenie”. Wejścia i wyjścia procesu nadrzędnego muszą odpowiadać wejściom i wyjściom procesów potomnych na diagramie niższego poziomu. Magazyny danych również muszą być zgodne. Jeśli magazyn pojawia się na diagramie nadrzędnym, diagram potomny musi poprawnie uwzględnić przepływ danych. Jeśli proces jest podzielony, przepływ danych do magazynu musi być zachowany po podziale.
⚠️ Błędy logiczne do uniknięcia
Niektóre błędy strukturalne mogą unieważnić schemat. Wczesne rozpoznanie tych błędów oszczędza czas w trakcie fazy rozwoju.
- Nieistniejące przepływy danych: Strzałka wychodząca z procesu bez przepływu danych wejściowych jest niemożliwa. Proces nie może generować danych wyjściowych z niczego. Każdy wyjście musi pochodzić z danych wejściowych lub zapisanych danych.
- Bezpośrednie połączenia magazynów: Jak wspomniano, magazyn nie może połączyć się z innym magazynem. Dane muszą przechodzić przez proces. Zapewnia to, że wszystkie przepływy danych są celowe i przetwarzane.
- Niezwiązane procesy: Proces, który nie ma żadnych przepływów danych wejściowych ani wyjściowych, jest izolowany. Nie współdziała z systemem i nie ma żadnego znaczenia w DFD.
- Pomylenie jednostek i magazynów: Jednostki zewnętrzne znajdują się poza granicą systemu. Magazyny danych znajdują się wewnątrz. Nie umieszczaj symbolu jednostki zewnętrznej wewnątrz granicy systemu, jakby była bazą danych.
🛠️ Implikacje implementacyjne
Różnica między procesem a magazynem wpływa na sposób budowy systemu. Procesy odpowiadają funkcjom, metodom lub mikroserwisom. Magazyny danych odpowiadają tabelom, plikom lub magazynom obiektów.
🔹 Projektowanie bazy danych
Podczas projektowania bazy danych magazyny danych w DFD stają się szablonem schematu. Atrybuty w strzałkach przepływu danych definiują kolumny. Relacje między magazynami (pośredniczone przez procesy) definiują klucze obce lub połączenia transakcyjne.
🔹 Automatyzacja przepływu pracy
Dla silników przepływu pracy procesy reprezentują kroki w potoku. Magazyny danych reprezentują stan przepływu pracy. Proces może zaktualizować stan w magazynie, aby oznaczyć zadanie jako zakończone. Zrozumienie pasywnego charakteru magazynu zapewnia, że silnik przepływu pracy czeka na odpowiedni stan przed kontynuacją.
🔍 Standardy wizualnej reprezentacji
Różne metodyki używają nieco innych symboli, ale logika pozostaje spójna.
- DeMarco i Yourdon: Używa zaokrąglonych prostokątów do procesów i otwartych prostokątów do magazynów danych.
- Gane i Sarson: Używa zaokrąglonych prostokątów do procesów i równoległych linii do magazynów danych.
Niezależnie od wybranej notacji, znaczenie semantyczne jest identyczne. Proces działa; magazyn przechowuje. Spójność w dokumentacji projektu jest ważniejsza niż przestrzeganie konkretnego standardu, pod warunkiem że zespół rozumie wybraną konwencję.
🎯 Podsumowanie ról
Tworzenie solidnego modelu systemu wymaga dyscypliny w przypisywaniu ról. Proces to aktor. Wykonuje pracę. Magazyn danych to scenariusz. Przechowuje rekwizyty. Bez aktora scena jest pusta. Bez sceny aktor nie ma gdzie umieścić swoich wyników.
Utrzymując jasne rozróżnienie między przekształceniem a przechowywaniem, analitycy tworzą schematy, które są nie tylko wizualnie atrakcyjne, ale także logicznie poprawne. Te schematy działają jako umowa między stakeholderami biznesowymi a zespołami technicznymi. Definiują granice odpowiedzialności i przepływ wartości.
Podczas przeglądu DFD zadaj sobie dwa pytania dla każdego symbolu: „Czy to wykonuje pracę?” (Proces) czy „Czy to przechowuje informacje?” (Magazyn). Jeśli odpowiedź jest niejasna, dopasuj etykietę lub połączenie. Jasność jest ostatecznym celem modelowania systemu.
Przestrzeganie tych zasad zapewnia, że ostateczna architektura będzie łatwa w utrzymaniu, skalowalna i zrozumiała. Różnica jest prosta, ale jej wpływ na integralność systemu jest głęboki.