











Budowanie niezawodnych systemów oprogramowania wymaga więcej niż tylko pisania kodu działającego poprawnie. Wymaga to jasnego zrozumienia, jak system zachowuje się w różnych warunkach. Diagramy maszyn stanów, często nazywane po prostu diagramami stanów, stanowią szkic tego zachowania. Wymieniają one różne stany, w których może znajdować się system, oraz zasady sterujące przejściami między nimi. Jednak wraz ze wzrostem złożoności systemów rośnie prawdopodobieństwo wystąpienia błędów logicznych. Debugowanie tych problemów wymaga strukturalnego podejścia, głębokiego zrozumienia logiki podstawowej oraz systematycznego eliminowania zmiennych.
Ten przewodnik przedstawia kluczowe strategie identyfikowania i rozwiązywania błędów logicznych w architekturach opartych na stanach. Zrozumienie anatomicznych cech przejść stanów oraz typowych pułapek pozwala inżynierom utrzymać integralność systemu bez opierania się na zgadywaniu.
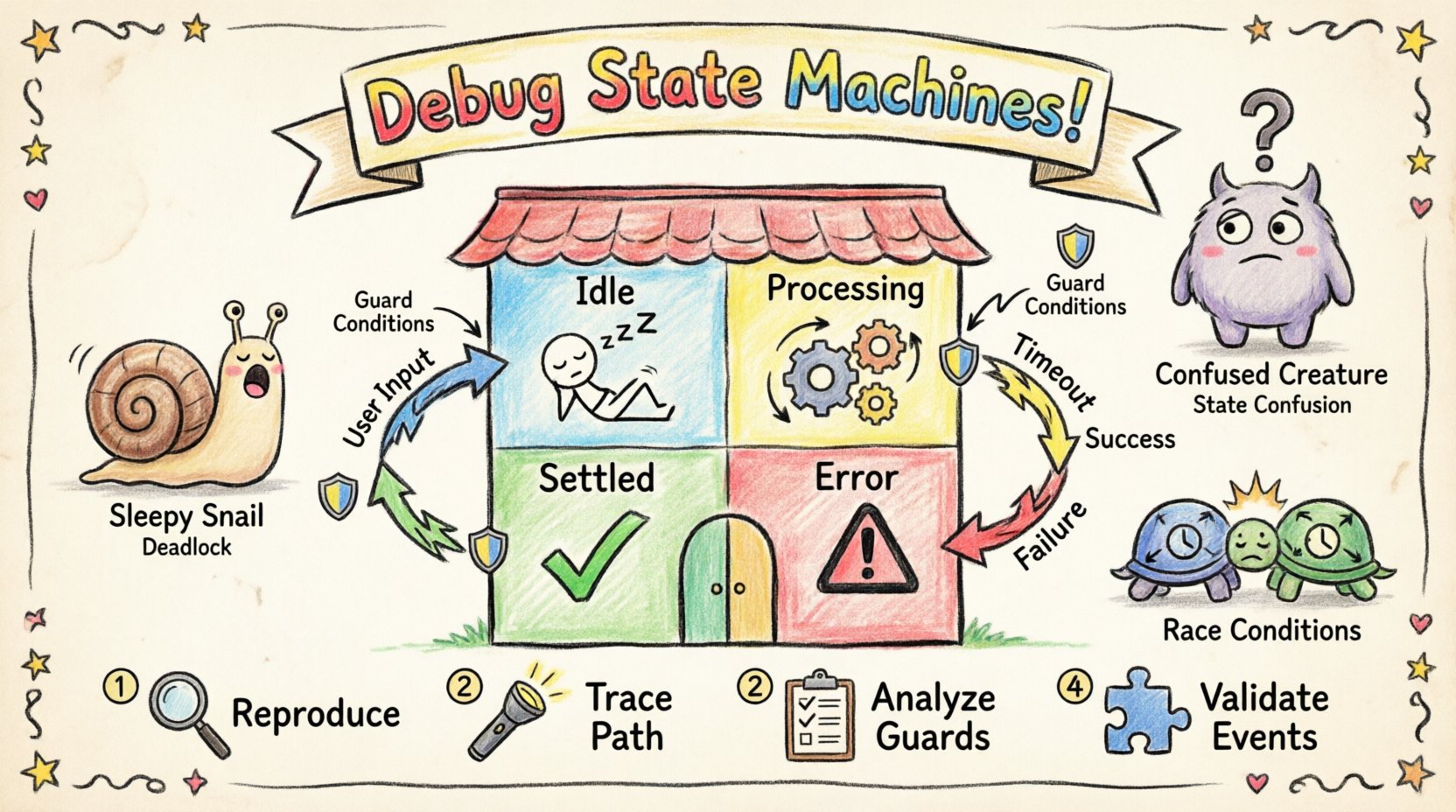
🔍 Zrozumienie anatomicznych cech maszyny stanów
Zanim zacznie się rozwiązywanie problemów, należy zrozumieć składniki, które napędzają maszynę stanów. Diagram stanów to nie tylko wizualne przedstawienie; jest to kontrakt logiczny definiujący cykl życia systemu. Każdy element spełnia określone zadanie w kontroli przepływu i danych.
- Stany: Odrębne tryby lub stany, w których system może się znajdować. Przykłady toNieaktywny, Przetwarzanie, lubBłąd.
- Przejścia: Ścieżki łączące stany. Przejście następuje, gdy określony zdarzenie wywołuje zmianę stanu z jednego na drugi.
- Zdarzenia: Sygnały lub działania, które wywołują przejścia. Mogą to być działania wewnętrzne lub zewnętrzne wejścia.
- Warunki (guards): Warunki logiczne oceniane podczas przejścia. Przejście następuje tylko wtedy, gdy warunek ma wartość true.
- Działania: Operacje wykonywane przy wejściu do stanu, wyjściu z niego lub podczas przejścia. Mogą to być logowanie, aktualizacja danych lub wywołanie zewnętrznych usług.
- Stany początkowy/końcowy: Punkt początkowy i punkt zakończenia cyklu życia.
Podczas debugowania bardzo ważne jest sprawdzenie, czy te składniki poprawnie współdziałają. Błąd logiczny często wynika z rozbieżności między oczekiwanym zachowaniem zdefiniowanym na diagramie a rzeczywistym zachowaniem w środowisku uruchomieniowym.
🚨 Powszechne błędy logiczne i ich objawy
Złożone systemy często cierpią na określone typy błędów logicznych. Wczesne rozpoznanie objawów może zaoszczędzić istotny czas podczas procesu debugowania. Poniższa tabela kategoryzuje typowe problemy, ich obserwowane objawy oraz najprawdopodobniejsze przyczyny.
| Typ błędu | Objaw | Przyczyna pierwotna |
|---|---|---|
| Fałszywe przejścia | System przechodzi do nieoczekiwanego stanu bez jasnego wyzwalacza. | Brakujące warunki ochronne lub nakładające się obsługiwacze zdarzeń. |
| Zamknięcia | System zatrzymuje się i nie reaguje na poprawne wejścia. | Brak wyjściowych przejść z określonego stanu dla niektórych zdarzeń. |
| Nieosiągalne stany | Niektóre stany nigdy nie są wejściowe podczas normalnej pracy. | Niepoprawne ścieżki wejścia lub logika pomijająca określone stany. |
| Zmęczenie stanów | System zachowuje się inaczej w tym samym stanie w zależności od historii. | Niepowodzenie w zresetowaniu kontekstu lub nieprawidłowe zarządzanie stanami historii. |
| Zarazem warunki wyścigu | Konfliktujące działania występują jednocześnie w stanach równoległych. | Brak synchronizacji między równoległymi podmaszynami. |
🧪 Metodologia krok po kroku debugowania
Rozwiązywanie problemów z maszyną stanów wymaga dyscyplinowanego podejścia. Nieplanowane naprawy często prowadzą do nowych błędów. Postępuj zgodnie z tym systematycznym podejściem, aby izolować i naprawiać błędy logiczne.
1. Odtwórz problem
Zanim spróbujesz naprawić problem, musisz wiarygodnie odtworzyć błąd. Jeśli problem jest przerywany, zapisz sekwencję zdarzeń prowadzących do awarii.
- Zidentyfikuj konkretne wejście lub zdarzenie, które wywołuje nieprawidłowe zachowanie.
- Zapisz bieżący stan systemu przed wystąpieniem zdarzenia.
- Zapisz stan, do którego system przechodzi po zdarzeniu.
- Sprawdź, czy problem występuje regularnie, czy tylko w określonych warunkach (np. konkretne wartości danych).
2. Śledź ścieżkę wykonania
Użyj mechanizmów rejestrowania, aby śledzić ścieżkę wykonania. Każde przejście powinno być zapisane wraz z odpowiednim kontekstem.
- Rejestrowanie wejścia/wyjścia: Rejestruj, gdy stan jest wejściowy i wyjściowy.
- Rejestrowanie przejść: Rejestruj zdarzenie, które wywołało przejście.
- Ocena warunków ochronnych: Rejestruj, czy warunki ochronne zostały spełnione czy nie oraz dlaczego.
- Rejestrowanie działań: Rejestruj, gdy działania są wykonywane i ich wynik.
Te dane tworzą chronologię zdarzeń. Porównaj tę chronologię z diagramem stanów. Szukaj rozbieżności, w których kod odchyla się od projektu.
3. Analiza warunków ochronnych
Warunki ochronne to częste źródła błędów logicznych. Przejście może wydawać się dostępne na diagramie, ale ukryty warunek może zapobiegać jego wyzwoleniu.
- Przejrzyj wszystkie warunki ochronne związane z problematycznym przejściem.
- Upewnij się, że zmienne używane w warunku ochronnym odpowiadają danym dostępnych w momencie zdarzenia.
- Sprawdź, czy ocena warunku ochronnego nie ma skutków ubocznych, które mogą nieoczekiwanie zmienić stan.
- Upewnij się, że warunki ochronne nie są zbyt restrykcyjne, blokując ważne przejścia.
4. Weryfikacja obsługi zdarzeń
Zdarzenia są katalizatorami zmian. Jeśli zdarzenie nie jest obsługiwane poprawnie, system może je zignorować lub obsłużyć w złym stanie.
- Sprawdź, czy nazwa zdarzenia dokładnie się zgadza między źródłem a maszyną stanów.
- Upewnij się, że zdarzenie jest wysyłane do poprawnej instancji maszyny stanów.
- Upewnij się, że zdarzenie nie jest zużywane przez stan nadrzędny, gdy powinien je obsłużyć stan potomny.
- Potwierdź, że kolejka zdarzeń przetwarza zdarzenia w oczekiwanej kolejności.
🔄 Obsługa współbieżności i stanów równoległych
Zaawansowane maszyny stanów często wykorzystują stany współbieżne. Pozwala to na jednoczesne działanie wielu niezależnych maszyn stanów w ramach stanu złożonego. Choć potężne, wprowadza to złożoność w zakresie synchronizacji i współdzielenia danych.
1. Punkty synchronizacji
W środowiskach współbieżnych przejścia muszą być zsynchronizowane, aby zapobiec warunkom wyścigu. Przejście w jednym stanie równoległym może zależeć od zakończenia przejścia w innym.
- Zdefiniuj jasne bariery synchronizacji, gdzie stany równoległe muszą się zsynchronizować.
- Użyj flag lub zmiennych stanu, aby wskazać gotowość gałęzi równoległych.
- Upewnij się, że stany końcowe w gałęziach równoległych są osiągnięte przed zakończeniem stanu złożonego.
2. Integralność współdzielonych danych
Stany równoległe często mają dostęp do zasobów współdzielonych. Jeśli dwa stany jednocześnie modyfikują te same dane, może dojść do ich uszkodzenia.
- Zaimplementuj mechanizmy blokowania podczas dostępu do współdzielonych zmiennych stanu.
- Używaj struktur danych niemutowalnych tam, gdzie to możliwe, aby zapobiec przypadkowej modyfikacji.
- Przeprowadź audyt wszystkich funkcji działań, aby ustalić, czy modyfikują one stan globalny lub współdzielony.
🛡️ Techniki weryfikacji i walidacji
Debugowanie jest reaktywne; weryfikacja jest proaktywna. Wprowadzanie strategii weryfikacji maszyny stanów przed wdrożeniem zmniejsza obciążenie związane z rozwiązywaniem problemów.
1. Analiza statyczna
Narzędzia analizy statycznej mogą skanować definicję diagramu stanów bez wykonywania kodu. Mogą identyfikować problemy strukturalne.
- Sprawdź stanu niedostępne.
- Zidentyfikuj przejścia, które nie mogą być wyzwolone przez żaden zdarzenie.
- Upewnij się, że wszystkie stany mają poprawne ścieżki wyjścia.
- Upewnij się, że wszystkie zdarzenia są obsługiwane (brak nieobsłużonych błędów zdarzeń).
2. Sprawdzanie modelu
Sprawdzanie modelu polega na matematycznym potwierdzeniu, że maszyna stanów spełnia określone właściwości. Jest to szczególnie przydatne dla systemów krytycznych pod względem bezpieczeństwa.
- Zdefiniuj właściwości, takie jak „system nigdy nie wchodzi w stan zawieszenia”.
- Uruchom algorytmy w celu weryfikacji tych właściwości względem grafu przejść stanów.
- Użyj tych narzędzi do weryfikacji skomplikowanych scenariuszy współbieżności.
3. Testy jednostkowe dla maszyn stanów
Każdy stan i przejście powinny być testowane niezależnie, gdzie to możliwe.
- Napisz testy, które umieszczają system w określonym stanie i wywołują określone zdarzenie.
- Załącz, że system przechodzi do poprawnego następnego stanu.
- Załącz, że wywoływane są oczekiwane działania.
- Testuj warunki graniczne, takie jak wywołanie zdarzenia w stanie, w którym nie powinno być dozwolone.
📝 Dokumentacja dla przyszłej konserwacji
Maszyna stanów, która jest trudna do zrozumienia, jest trudna do debugowania. Jasna dokumentacja zapewnia, że przyszli inżynierowie mogą skutecznie rozwiązywać problemy bez odwrotnej analizy logiki.
- Komentarze w kodzie: Dodaj komentarze w tekście kodu wyjaśniające złożone przejścia lub nieoczywiste warunki strażnika.
- Utrzymuj diagramy: Zachowaj diagramy wizualne stanów zsynchronizowane z kodem. Używany diagram przestarzały jest obciążeniem.
- Dokumentuj przypadki brzegowe: Zapisz znane ograniczenia lub specyficzne scenariusze, które maszyna obsługuje inaczej.
- Kontrola wersji: Traktuj definicje stanów jako kod. Używaj kontroli wersji do śledzenia zmian w logice w czasie.
⚙️ Przykład z rzeczywistego świata: Przepływ przetwarzania płatności
Rozważ system przetwarzania płatności. Maszyna stanów zarządza cyklem życia transakcji:Zainicjowany, Zatwierdzony, Zrealizowany, lub Niepowodzenie.
Wyobraź sobie sytuację, w której transakcja wchodzi w stan Zrealizowany ale baza danych wskazuje, że nadal jest Zatwierdzony. Jest to klasyczny błąd niezgodności stanu.
- Diagnoza: Przejście z Zatwierdzony do Zrealizowany zostało wyzwolone, ale logika aktualizacji stanu nie powiodła się w zapisaniu zmiany w magazynie trwałym.
- Skutki: Użytkownik widzi sukces, ale backend oczekuje zarezerwowania środków.
- Rozwiązanie: Zaimplementuj otoczenie transakcji, które zapewnia, że aktualizacja stanu i zatwierdzenie bazy danych zachodzą atomowo.
- Zapobieganie: Dodaj zadanie reconciliacji, które okresowo sprawdza stan maszyny stanów względem stanu bazy danych.
🔧 Zaawansowane narzędzia do rozwiązywania problemów
Choć ręczne śledzenie jest skuteczne, pewne narzędzia mogą przyspieszyć proces debugowania.
- Interaktywne wizualizatory stanów: Narzędzia umożliwiające krok po kroku przeglądanie stanów wizualnie w czasie rzeczywistym.
- Agregatory dzienników: Centralizowane systemy rejestrowania, które pozwalają filtrować według identyfikatora stanu lub typu zdarzenia.
- Protokoły debugowania: Interfejsy umożliwiające zewnętrznym systemom pobieranie bieżącego stanu maszyny bez jej ponownego uruchamiania.
- Środowiska symulacji:Sandboxy, w których możesz odtwarzać sekwencje zdarzeń w celu bezpiecznego odtworzenia błędów.
🧠 Obciążenie kognitywne i złożoność stanów
Wraz ze wzrostem liczby stanów, obciążenie kognitywne potrzebne do utrzymania logiki rośnie wykładniczo. Jest to znane jako problem eksplozji stanów.
- Modularyzuj:Podziel duże maszyny stanów na mniejsze, łatwiejsze do zarządzania podmaszyny.
- Abstrahuj:Użyj stanów złożonych, aby ukryć złożoność przed logiką wyższego poziomu.
- Ogranicz:Ścisłe ogranicz liczbę stanów współbieżnych, aby zmniejszyć narzut synchronizacji.
- Refaktoryzuj:Regularnie przeglądarkuj diagram stanów w celu identyfikacji nadmiarowych lub nakładających się stanów.
🛑 Obsługa nieoczekiwanych danych wejściowych
Nieporuszalne systemy muszą obsługiwać dane wejściowe, które nie są zdefiniowane w diagramie stanów. Czasem nazywa się to „Stanem błędu”.
- Przejścia domyślne:Zdefiniuj przejście ogólne dla zdarzeń występujących w nieoczekiwanych stanach.
- Rejestrowanie:Rejestruj nieoczekiwane zdarzenia o wysokim poziomie ważności, aby ostrzec programistów.
- Odzyskiwanie:Upewnij się, że system może odzyskać się z stanu błędu, zamiast awarii.
- Powiadomienie:Powiadom użytkownika lub system nadzoru, gdy wystąpi nieoczekiwane zdarzenie.
📊 Metryki zdrowia maszyny stanów
Aby utrzymać zdrowy system, śledź konkretne metryki związane z maszyną stanów.
- Częstotliwość przejść:Jak często występują konkretne przejścia. Nagłe zmiany mogą wskazywać na błąd.
- Czas trwania stanu:Jak długo system pozostaje w konkretnym stanie. Długie okresy mogą wskazywać na zawieszenie.
- Wskaźnik błędów: Procent zdarzeń kończących się przejściami błędów.
- Liczba zamknięć: Liczba razy, gdy system wchodzi w stan bez wyjściowych przejść.
🚀 Wnioski dotyczące integralności systemu
Zachowanie integralności maszyny stanów to ciągły proces. Wymaga on czujności, jasnej dokumentacji oraz głębokiego zrozumienia przepływu logiki. Przestrzegając metodologii przedstawionych powyżej, inżynierowie mogą skutecznie debugować błędy logiczne i zapewnić przewidywalne działanie złożonych systemów.
Pamiętaj, że celem nie jest tylko usunięcie błędu w chwili obecnej, ale poprawa ogólnej odporności architektury. Dobrze zaprojektowana maszyna stanów jest samodokumentującą się i odporna na zmiany. Inwestuj czas w fazie projektowania, aby zmniejszyć koszty rozwiązywania problemów w przyszłości.
Stosuj te zasady spójnie. Regularnie przeglądaj swoje schematy. Przeprowadzaj szczegółowe testy przejść. Dzięki dyscyplinie możesz zarządzać złożonością i dostarczać stabilny, niezawodny oprogramowanie.