











Systemy rozproszone bardzo mocno opierają się na przepływie informacji między izolowanymi składnikami. Budując mikroserwisy, architektura nie polega tylko na rozdzieleniu kodu; polega na koordynowaniu tego, jak dane poruszają się przez sieć. Zrozumienie logiki przepływu danych jest kluczowe dla utrzymania integralności systemu, jego wydajności i niezawodności. Bez jasnej mapy, gdzie dane powstają, gdzie się przekształcają i gdzie się kończą, systemy stają się przezroczyste i trudne do diagnozowania problemów.
Ten przewodnik bada metodologię mapowania tych przepływów. Przyjrzymy się komponentom strukturalnym, logice ruchu danych oraz wzorcom sterującym komunikacją między usługami. Celem jest stworzenie przejrzystej architektury, w której każdy przepływ danych jest zarejestrowany.
Zrozumienie architektury 🏗️
Architektura mikroserwisów rozkłada aplikację monolityczną na mniejsze, niezależne jednostki. Każda jednostka obsługuje określoną możliwość biznesową. Jednak ta niezależność wprowadza złożoność w zakresie zarządzania stanem i komunikacji. Dane nie istnieją w próżni; poruszają się.
Gdy mapujesz te usługi, w rzeczywistości rysujesz szkic nerwowej systemu. Musisz zidentyfikować producentów danych i ich odbiorców. Musisz zrozumieć protokoły używane do przesyłania danych. Czy usługi komunikują się bezpośrednio przez HTTP? Czy używają kolejki komunikatów? Czy mają dostęp do wspólnej bazy danych?
Jasność w tej dziedzinie zapobiega silnemu powiązaniu. Jeśli usługa A zależy od usługi B, aby działać, ta zależność musi być jasno wyrażona na mapie. Ukryte zależności prowadzą do zjawiska kaskadowych awarii. Wizualizując przepływ, możesz wykryć węzły zatrzasku zanim wpłyną na wydajność w środowisku produkcyjnym.
Główne czynniki mapowania
- Obserwability:Nie możesz debugować tego, czego nie widzisz. Jasna mapa pomaga śledzić żądania w rozproszonym środowisku.
- Bezpieczeństwo:Zrozumienie przepływu danych pozwala na stosowanie szyfrowania i kontroli dostępu na odpowiednich granicach.
- Wydajność:Identyfikacja ścieżek o wysokim opóźnieniu pomaga zoptymalizować wywołania sieciowe i zapytania do bazy danych.
- Zgodność:Przepisy często wymagają wiedzy o tym, gdzie znajduje się wrażliwa data i jak się porusza.
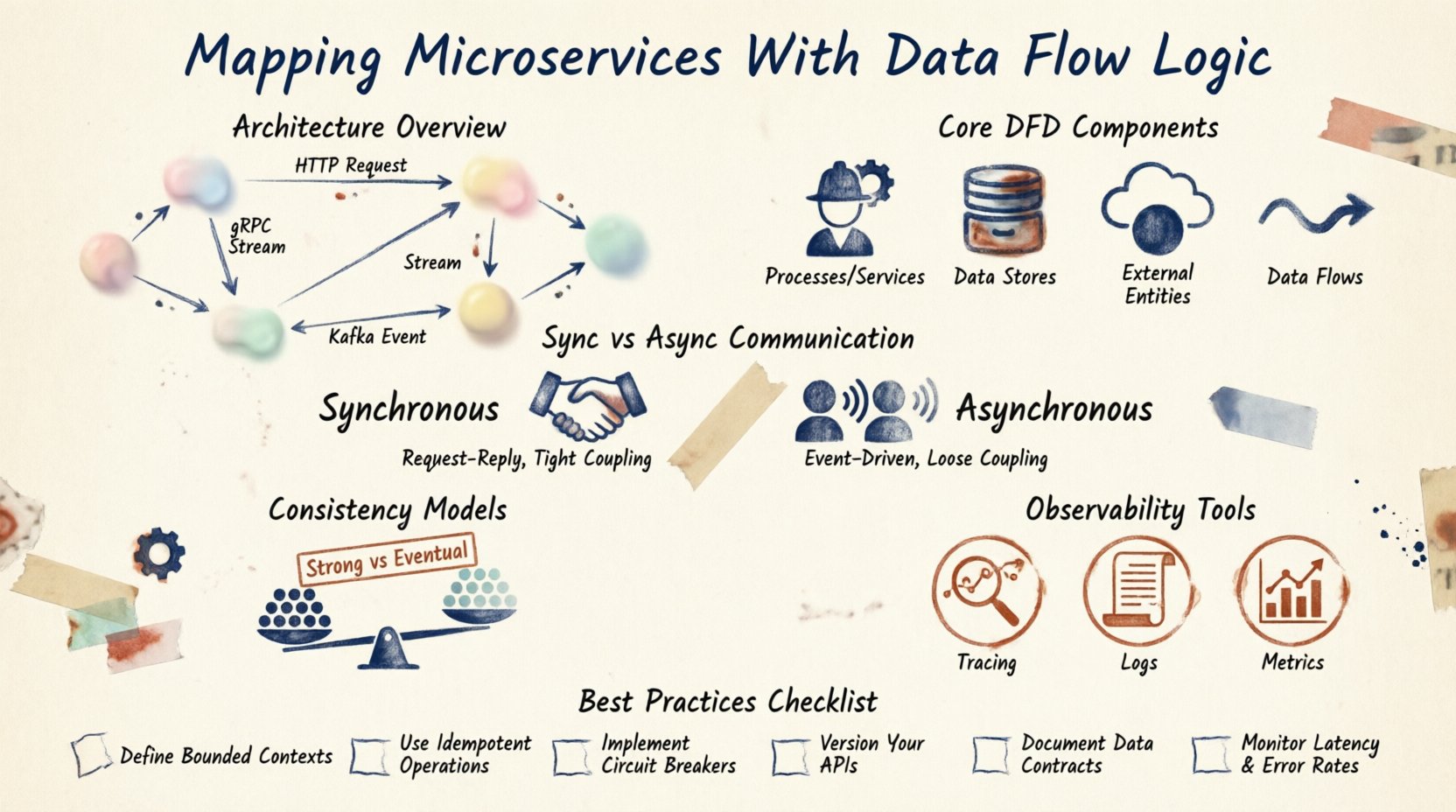
Kluczowe komponenty diagramów przepływu danych 📊
Diagram przepływu danych (DFD) zapewnia standardowy sposób przedstawiania tych interakcji. W kontekście mikroserwisów komponenty są nieco inne niż w tradycyjnych DFD z inżynierii oprogramowania.
1. Procesy (usługi)
Są to aktywne elementy. Każdy mikroserwis reprezentuje proces, który przekształca dane wejściowe w dane wyjściowe. Na przykład usługa Zamówień otrzymuje dane o zamówieniu i przekształca je w rezerwację towaru.
2. Magazyny danych
Dane nie zawsze pozostają w pamięci. Często trwają w bazach danych, pamięciach podręcznych lub magazynach obiektów. W środowisku mikroserwisów usługi zwykle mają prywatne magazyny danych. Zapewnia to luźne powiązanie. Jeśli zmieni się schemat bazy danych, dostosować musi tylko usługa właścicielska.
3. Zewnętrzne jednostki
Są to akcje poza systemem. Mogą to być płatności zewnętrzne, aplikacja mobilna lub użytkownik. Inicjują żądania lub otrzymują powiadomienia. Mapowanie tych granic jest kluczowe dla projektowania bramki API.
4. Przepływy danych
Są to strzałki łączące komponenty. Reprezentują ruch informacji. Każdy przepływ powinien mieć etykietę opisującą przesyłane dane. Czy to ładunek JSON? Czy plik binarny? Czy powiadomienie zdarzenia?
Krok po kroku proces mapowania 🗺️
Tworzenie mapy to systematyczne ćwiczenie. Wymaga ono rozkładania systemu warstwa po warstwie. Oto logiczny sposób tworzenia tych diagramów.
- Zidentyfikuj granice: Zdefiniuj, co znajduje się wewnątrz systemu, a co poza nim. To ustala zakres Twojego diagramu.
- Wypisz usługi: Wypisz każdą usługę mikroserwisową uczestniczącą w analizowanym procesie biznesowym.
- Zdefiniuj punkty wejścia danych: Gdzie dane wchodzą do systemu? Czy to punkt końcowy interfejsu API? Zadanie harmonogramu? Konsument kolejki komunikatów?
- Śledź ścieżkę: Śledź pojedynczy fragment danych od wejścia do wyjścia. Zanotuj każdą usługę, z którą się styka.
- Zidentyfikuj przechowywanie: Zaznacz, gdzie dane są odczytywane lub zapisywane w każdym kroku.
- Weryfikuj logikę: Przejrzyj mapę wraz z zespołem deweloperskim, aby upewnić się, że odpowiada rzeczywistej implementacji.
Wzorce komunikacji 📡
Sposób, w jaki usługi komunikują się ze sobą, decyduje o logice przepływu. Istnieją dwa główne tryby: synchroniczny i asynchroniczny.
Komunikacja synchroniczna
Usługa A wywołuje usługę B i czeka na odpowiedź. Często implementowana za pomocą REST lub gRPC. Daje natychmiastową odpowiedź, ale tworzy silne powiązanie. Jeśli usługa B jest wolna, usługa A zawiesza się.
Komunikacja asynchroniczna
Usługa A wysyła komunikat i kontynuuje pracę. Usługa B pobiera go, gdy jest gotowa. Używa brokerów komunikatów lub strumieni zdarzeń. Poprawia odporność, ale utrudnia śledzenie stanu.
| Aspekt | Synchroniczny | Asynchroniczny |
|---|---|---|
| Opóźnienie | Wyższe (blokujące) | Niższe (nieblokujące) |
| Zależność | Silna | Słaba |
| Złożoność | Łatwe do śledzenia | Wymaga źródła zdarzeń |
| Obsługa błędów | Powtórz natychmiast | Kolejki listów martwych |
Modele spójności 🤝
W systemie rozproszonym spójność danych jest istotnym zagadnieniem. Nie możesz polegać na jednym transakcji obejmującej wiele baz danych. Musisz wybrać model spójności.
Silna spójność
Każdy odczyt otrzymuje najnowsze zapisy. Jest to trudne do osiągnięcia między mikroserwisami bez blokowania. Często wymaga mechanizmów rozproszonego blokowania.
Spójność ostateczna
Dane będą spójne po pewnym czasie. Aktualizacje rozprzestrzeniają się asynchronicznie. Jest to standard dla większości mikroserwisów. Pozwala na wysoką dostępność, ale wymaga od aplikacji obsługiwania tymczasowych niezgodności danych.
Obserwowalność i śledzenie 🔍
Gdy mapa została narysowana, potrzebujesz narzędzi do jej monitorowania. Śledzenie rozproszone pozwala śledzić identyfikator żądania przez każdy serwis. Jest to kluczowe dla debugowania.
Dzienniki powinny być skorelowane. Jeśli żądanie nie powiedzie się, dzienniki z bramki, serwisu zamówień i serwisu płatności muszą być ze sobą powiązane. To połączenie jest cyfrowym podwójnikiem Twojego diagramu przepływu danych.
Metryki są również częścią przepływu. Powinieneś śledzić objętość wiadomości, opóźnienia wywołań i stopy błędów. Te metryki potwierdzają zdrowie ścieżek danych, które zaprojektowałeś.
Najlepsze praktyki utrzymania 🛠️
Diagram jest użyteczny tylko wtedy, gdy pozostaje dokładny. Systemy się rozwijają, a mapa musi się rozwijać razem z nimi.
- Automatyzacja generowania: Tam gdzie to możliwe, generuj diagramy z kodu lub infrastruktury jako kodu. Zmniejsza to błędy ręczne.
- Kontrola wersji: Przechowuj diagramy w tym samym repozytorium co kod. Przeglądaj je podczas żądań zmian.
- Regularne audyty: Zaprojektuj przeglądy kwartalne, aby upewnić się, że mapa odpowiada działającemu systemowi.
- Dokumentuj protokoły: Jasną definicję formatów danych. Używaj schematów, aby zapewnić strukturę między serwisami.
Wyzwania w przepływach rozproszonych ⚠️
Mapowanie tych systemów nie jest bez trudności. Sieci zawodzą. Serwisy restartują się. Dane giną.
Opóźnienia sieciowe: Fizyczna odległość między serwisami może wpływać na wydajność. Musisz to uwzględnić w logice czasowej.
Fragmentacja danych: Dane są rozproszone na wielu magazynach. Odtworzenie pełnego obrazu jednostki wymaga połączenia danych z różnych źródeł. To dodaje złożoności zapytaniom.
Orkiestracja vs. Choreografia: Musisz zdecydować, kto kontroluje przepływ. Orkiestracja używa centralnego koordynatora. Choreografia opiera się na zdarzeniach. Oba mają kompromisy pod kątem widoczności i kontroli.
Zabezpieczenie projektu na przyszłość 🔮
Technologia się zmienia. Protokoły ewoluują. Twoja mapa powinna być wystarczająco abstrakcyjna, aby przetrwać te zmiany.
Skup się na logice biznesowej, a nie szczegółach implementacji. Opisz, co oznaczają dane, a nie tylko jak są zakodowane. Ta abstrakcja pozwala zmieniać technologie pod spodem bez ponownego pisania całego architektury.
Zastanów się nad skalowalnością. Czy przepływ może obsłużyć dziesięć razy większą ilość obciążeń? Czy mapa pokazuje, gdzie mogą wystąpić węzły zatyczki? Projektuj z myślą o wzroście od samego początku.
Ostateczne rozważania nad logiką danych
Mapowanie mikroserwisów z wykorzystaniem logiki przepływu danych to podstawowa umiejętność dla architektów. Przenosi rozmowę z abstrakcyjnego kodu na konkretny przepływ. Poprzez wizualizację przepływu zespoły mogą podejmować lepsze decyzje dotyczące odporności, bezpieczeństwa i wydajności.
Wymaga to dyscypliny, aby utrzymać mapy aktualne. Wymaga współpracy, aby zapewnić, że wszyscy rozumieją ścieżki. Ale rezultatem jest system łatwiejszy do budowania, łatwiejszy do debugowania i łatwiejszy do skalowania. Dane płyną jasno, a system pozostaje stabilny pod ciśnieniem.
Zainwestuj czas w te diagramy. Są dokumentacją dla życiodajnej krwi systemu. Gdy zgaszą się światła na serwerze produkcyjnym, to właśnie te mapy będą kierować odbudową.