










La construction de systèmes logiciels robustes exige plus que la rédaction de code fonctionnel. Elle exige une approche structurée pour gérer le cycle de vie des données et des processus. Une machine à états est un outil fondamental à cet effet, offrant une carte claire de la manière dont un système passe d’un état à un autre. Lorsqu’on intègre des diagrammes d’états avec un stockage persistant et des services externes, la complexité augmente considérablement. Ce guide explore les modèles techniques nécessaires pour connecter efficacement la logique d’état aux opérations de base de données et aux interactions d’API.
Les machines à états ne sont pas simplement des constructions théoriques ; elles sont des implémentations pratiques qui dictent le flux des données. Que ce soit pour gérer le traitement des commandes, l’inscription des utilisateurs ou l’automatisation des workflows, l’intégrité de l’état est primordiale. Intégrer cette logique avec des bases de données garantit que les changements d’état sont durables. Se connecter aux API permet au système de réagir aux déclencheurs externes. Ce document détaille les considérations architecturales, les modèles d’implémentation et les stratégies de mitigation des risques pour cette intégration.
Comprendre l’architecture fondamentale 🧩
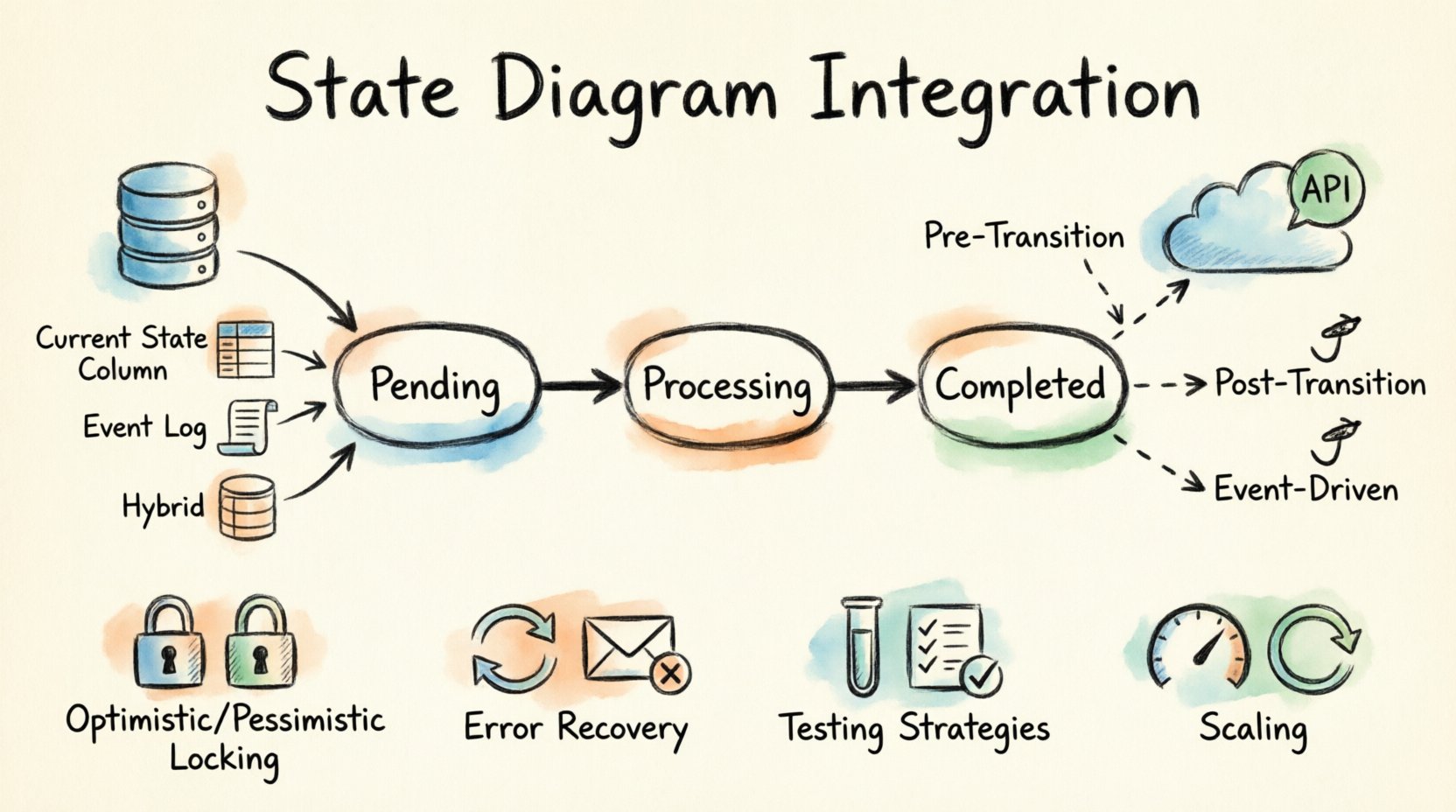
Avant de plonger dans la persistance et la logique réseau, il est essentiel de définir les composants impliqués. Une machine à états se compose de trois éléments principaux : les états, les transitions et les événements. Comprendre comment ces éléments interagissent avec les systèmes externes forme la base de l’intégration.
- États : Représentent l’état de l’entité à un moment donné. Des exemples incluent En attente, En cours de traitement, ou Terminé.
- Transitions : Le passage d’un état à un autre déclenché par un événement. C’est ici que la logique est appliquée.
- Événements : Des signaux qui déclenchent une transition. Ils peuvent provenir d’actions internes du système ou d’appels d’API externes.
Lors de l’intégration, l’état doit être visible pour la base de données, et les transitions doivent être capables d’appeler des API. Cela crée une chaîne de dépendances où la base de données détient la vérité, et l’API gère les effets secondaires.
Stratégies de persistance de base de données 🗄️
La persistance est le processus de stockage de l’état actuel afin qu’il survive à un redémarrage ou à une panne du système. La manière dont vous stockez l’état influence les performances, la cohérence et les capacités de récupération. Il existe plusieurs modèles pour mapper les nœuds du diagramme d’états aux lignes de la base de données.
Stockage de l’état actuel
L’approche la plus courante consiste à stocker l’identifiant de l’état actuel dans une colonne dédiée au sein de la table principale des enregistrements. Cela permet une récupération rapide sans avoir à scanner les journaux.
- Implémentation : Ajouter une colonne
statutoucode_etatà la table principale des entités. - Avantage : Performances de lecture rapides pour vérifier l’état actuel.
- Risque : Si la logique d’état est complexe, une seule colonne ne peut pas capturer tout le contexte nécessaire.
Stockage du journal des événements
Dans certaines architectures, l’état actuel n’est pas stocké directement. À la place, la séquence des événements est stockée dans un journal. L’état actuel est déduit en rejouant les événements.
- Implémentation : Ajouter un événement à une table chaque fois qu’une transition a lieu.
- Avantage : Traçabilité complète et capacité à reconstruire l’historique.
- Risque : Le calcul de l’état actuel nécessite le traitement de tout le journal, ce qui peut être plus lent.
Comparaison des modèles de stockage
| Modèle | Performance de lecture | Complexité d’écriture | Capacité de contrôle |
|---|---|---|---|
| Colonne d’état actuel | Élevée | Faible | Faible |
| Journal des événements | Moyenne (nécessite un rejeu) | Moyenne | Élevée |
| Hybride | Élevée | Moyenne | Moyenne |
Le modèle hybride est souvent préféré. Il stocke l’état actuel pour un accès rapide tout en maintenant un journal des événements pour le contrôle. Cela garantit que le système sait où il se trouve actuellement, mais aussi comment il y est arrivé.
Contraintes et intégrité de la base de données
Assurer l’intégrité des données est crucial. La base de données doit appliquer des règles qui empêchent les transitions d’état non valides. Bien que la logique d’application soit le principal garde-fou, les contraintes de base de données fournissent une sécurité supplémentaire.
- Vérifier les contraintes : Définir des valeurs valides pour la colonne d’état.
- Clés étrangères : Lier les journaux d’état à l’entité principale pour garantir l’intégrité référentielle.
- Transactions : Envelopper les mises à jour d’état et les modifications de données associées dans une seule transaction pour garantir l’atomicité.
Intégration de l’API et de la logique externe 🔗
Les transitions d’état nécessitent souvent une action. Lorsqu’un système passe de En attente à En cours de traitement, il peut être nécessaire d’envoyer une notification, de facturer un paiement ou de mettre à jour un système de gestion des stocks. Ces actions sont gérées via des API.
Déclenchement d’appels externes
Les appels API doivent être déclenchés en fonction de la logique de transition. Cela garantit que les effets secondaires ne se produisent que lorsque le changement d’état est valide.
- Hooks pré-transition : Valider les conditions externes avant d’autoriser le changement d’état.
- Hooks post-transition : Exécuter la logique après que l’état a été correctement validé.
- Hooks pilotés par événements : Écouter les événements de changement d’état et réagir de manière asynchrone.
Gestion des échecs d’API
Les appels réseau sont peu fiables. Si un appel API échoue pendant une transition d’état, le système doit décider de la suite à donner. Laisser l’état dans une position ambiguë peut entraîner une corruption des données.
- Transactions compensatoires : Si une action échoue, déclencher un retour arrière ou un état spécifique pour marquer l’échec (par exemple, Échec ou Réessayer).
- Logique de réessai : Mettre en œuvre un délai exponentiel pour les erreurs temporaires.
- Idempotence : Assurez-vous que la répétition d’un appel d’API ne crée pas de doublons de dossiers ou de frais.
Schémas de requête
| Schéma | Cas d’utilisation | Complexité |
|---|---|---|
| Synchronisé | Retour immédiat requis | Faible |
| Asynchrone | Tâches longues | Moyen |
| Envoyer et oublier | Notifications | Faible |
Les appels synchrones bloquent la transition d’état jusqu’à ce que l’API réponde. C’est simple, mais cela peut entraîner des délais d’attente. Les appels asynchrones permettent à l’état de se mettre à jour immédiatement, tandis qu’un travailleur traitera ultérieurement la requête externe. Cela déconnecte la logique d’état de la latence liée à la dépendance externe.
Concurrence et conditions de course 🔄
Lorsque plusieurs processus tentent de modifier l’état de la même entité simultanément, des conditions de course peuvent survenir. C’est fréquent dans les systèmes distribués où les requêtes arrivent via des points d’entrée API différents.
Verrouillage optimiste
Le verrouillage optimiste suppose que les conflits sont rares. Il utilise un numéro de version ou une horodatage pour détecter les modifications.
- Logique : Lisez la version actuelle. Mettez à jour l’enregistrement avec l’état nouveau et la version incrémentée.
- Conflit : Si la mise à jour n’affecte aucune ligne, un autre processus a modifié l’enregistrement. La transaction est annulée.
- Avantage : Haut débit pour les systèmes à faible contention.
Verrouillage pessimiste
Le verrouillage pessimiste suppose que les conflits sont probables. Il verrouille l’enregistrement avant de le lire.
- Logique : Acquérir un verrou exclusif sur la ligne. Effectuer la mise à jour. Libérer le verrou.
- Conflit : D’autres processus attendent que le verrou soit libéré.
- Avantage :Garantit l’ordre des opérations.
- Risque :Peut entraîner des blocages si ce n’est pas géré avec soin.
Gestion d’état basée sur une file d’attente
Pour éviter entièrement les problèmes de concurrence, acheminez toutes les demandes de modification d’état à travers une seule file d’attente.
- Implémentation :Toutes les requêtes API poussent un événement dans une file de messages.
- Traitement :Un seul worker traite les événements séquentiellement pour un ID d’entité spécifique.
- Avantage :Élimine les conditions de course par conception.
Gestion des erreurs et récupération 🛡️
Les erreurs sont inévitables. La couche d’intégration doit les gérer sans laisser la machine à états dans un état corrompu.
Frontières de transaction
Définissez où la transaction commence et se termine. Une erreur courante consiste à valider l’état de la base de données avant que l’appel API n’ait réussi. Cela laisse le système dans un état où la base de données indique «Terminé», mais le service externe n’a jamais reçu la requête.
- Commit en deux phases :Assurez-vous que la base de données et le service externe sont d’accord sur le résultat.
- Consistance éventuelle :Acceptez que la cohérence puisse être retardée, mais assurez-vous d’avoir un mécanisme pour la corriger.
Files de lettres mortes
Si un appel API échoue plusieurs fois, déplacez l’événement vers une file de lettres mortes. Cela empêche le système de tourner indéfiniment dans une boucle de réessai.
- Alerte :Avertir les ingénieurs lorsque des éléments entrent dans la file de lettres mortes.
- Intervention manuelle :Permettre aux opérateurs de réessayer ou de supprimer les événements échoués.
Tests et validation 🧪
Tester des machines à états est complexe car le nombre de chemins possibles croît de manière exponentielle. Une stratégie de test solide couvre la logique, les points d’intégration et les scénarios d’échec.
Tests unitaires de la logique d’état
Testez la machine à états de manière isolée par rapport à la base de données et à l’API.
- Entrée / Sortie :Fournissez un événement et vérifiez l’état résultant.
- Transitions non valides :Assurez-vous que les événements non valides sont rejetés.
- Couverture du code :Viser une couverture à 100 % des règles de transition d’état.
Tests d’intégration
Testez le flux avec des mocks de base de données et d’API.
- Schéma de base de données :Vérifiez que les mises à jour d’état correspondent au schéma.
- Mocks d’API :Simulez les réponses de l’API (succès, échec, délai d’attente) pour tester la gestion des erreurs.
- Du début à la fin :Exécutez le flux complet du début à la fin dans un environnement de test.
Tests de mutation
Casser intentionnellement le code pour voir si les tests détectent l’erreur.
- Modifications de logique :Supprimez une transition d’état et vérifiez que le test échoue.
- Modifications de données :Modifiez l’état de la base de données et vérifiez que le système le rejette.
Mise à l’échelle et performance 🚀
À mesure que le système grandit, la machine à états doit gérer une charge plus importante sans dégradation des performances.
Mise en cache de l’état
Lire l’état depuis la base de données à chaque requête peut être lent. Les caches en mémoire peuvent réduire la latence.
- Stratégie :Mettez en cache l’état actuel pour un ID d’entité spécifique.
- Invalider : Assurez-vous que le cache est invalidé immédiatement après un changement d’état.
- Consistance : Acceptez des incohérences temporaires si le taux de réussite du cache est élevé.
Fractionnement de la base de données
Si le nombre d’entités est important, divisez la base de données en plusieurs fragments basés sur l’ID d’entité.
- Avantage :Répartit la charge sur plusieurs serveurs.
- Défi :Les requêtes complexes qui s’étendent sur plusieurs fragments deviennent difficiles.
Maintenance et versioning 📝
Les machines à états évoluent. De nouveaux états sont ajoutés, et d’anciens sont dépréciés. Gérer cette évolution est crucial pour la stabilité à long terme.
Versionner la logique d’état
Stockez la version de la logique de la machine à états aux côtés des données d’état.
- Compatibilité : Assurez-vous que les anciennes données peuvent être lues par les nouvelles versions.
- Migration : Écrivez des scripts pour mettre à jour les enregistrements existants vers le nouveau schéma.
Stratégie de dépréciation
Lors de la suppression d’un état, ne le supprimez pas immédiatement.
- Marquer comme obsolète : Ajoutez un indicateur pour indiquer que l’état est obsolète.
- Bloquer les transitions : Empêchez les nouvelles transitions vers l’état déprécié.
- Nettoyage : Supprimez la définition de l’état uniquement après que toutes les données aient été migrées.
Documentation
Maintenez un diagramme visuel qui correspond au code. Cela aide les nouveaux développeurs à comprendre le système.
- Outils de diagramme : Utilisez des outils capables de générer des diagrammes à partir du code ou de la configuration.
- Journal des modifications :Documentez chaque modification du diagramme d’état dans l’historique des versions.
Considérations de sécurité 🔐
Les transitions d’état impliquent souvent des données sensibles. La sécurité doit être intégrée au niveau de la couche d’intégration.
- Autorisation :Vérifiez que l’utilisateur demandant le changement d’état dispose des autorisations nécessaires pour cette transition spécifique.
- Validation des données :Nettoyez toutes les données d’entrée avant de traiter le changement d’état.
- Journalisation :Enregistrez les changements d’état pour une vérification de sécurité, mais assurez-vous que les données sensibles sont masquées.
Résumé des meilleures pratiques
- Stockez l’état actuel dans la base de données pour un accès rapide.
- Enregistrez tous les événements pour assurer la traçabilité et la reconstruction.
- Utilisez des transactions pour garantir l’atomicité entre les mises à jour d’état et les appels d’API.
- Implémentez une logique de réessai avec backoff exponentiel en cas d’échec d’API.
- Utilisez le verrouillage optimiste pour gérer efficacement les mises à jour concurrentes.
- Testez toutes les transitions d’état, y compris les transitions invalides.
- Versionnez votre logique d’état pour gérer son évolution au fil du temps.
En suivant ces modèles, les développeurs peuvent concevoir des machines à états résilientes, évolutives et maintenables. L’intégration entre la logique d’état, les bases de données et les API constitue le fondement des processus métier fiables. Une conception appropriée à ce niveau prévient la corruption des données et garantit que le système se comporte de manière prévisible sous charge.