











Dans le paysage des systèmes distribués modernes, la complexité n’est pas une erreur ; c’est une caractéristique de l’échelle. À mesure que les organisations grandissent, les architectures monolithiques se fragmentent en microservices. Ce changement offre de l’agilité et de la résilience, mais introduit un défi majeur : comprendre comment ces unités indépendantes communiquent entre elles. Sans une carte claire des flux de communication, les équipes naviguent dans un labyrinthe de dépendances, ce qui entraîne des cycles de débogage lents, des effets secondaires involontaires et des déploiements fragiles.
Ce guide explore une approche concrète pour cartographier les communications complexes entre microservices. Nous passerons au-delà de la théorie abstraite pour examiner les mécanismes d’interaction entre services, les méthodes pour documenter ces relations, et les stratégies pour maintenir une clarté croissante au fil de l’évolution du système. L’objectif n’est pas de créer un document statique, mais d’établir une compréhension vivante de votre architecture distribuée.
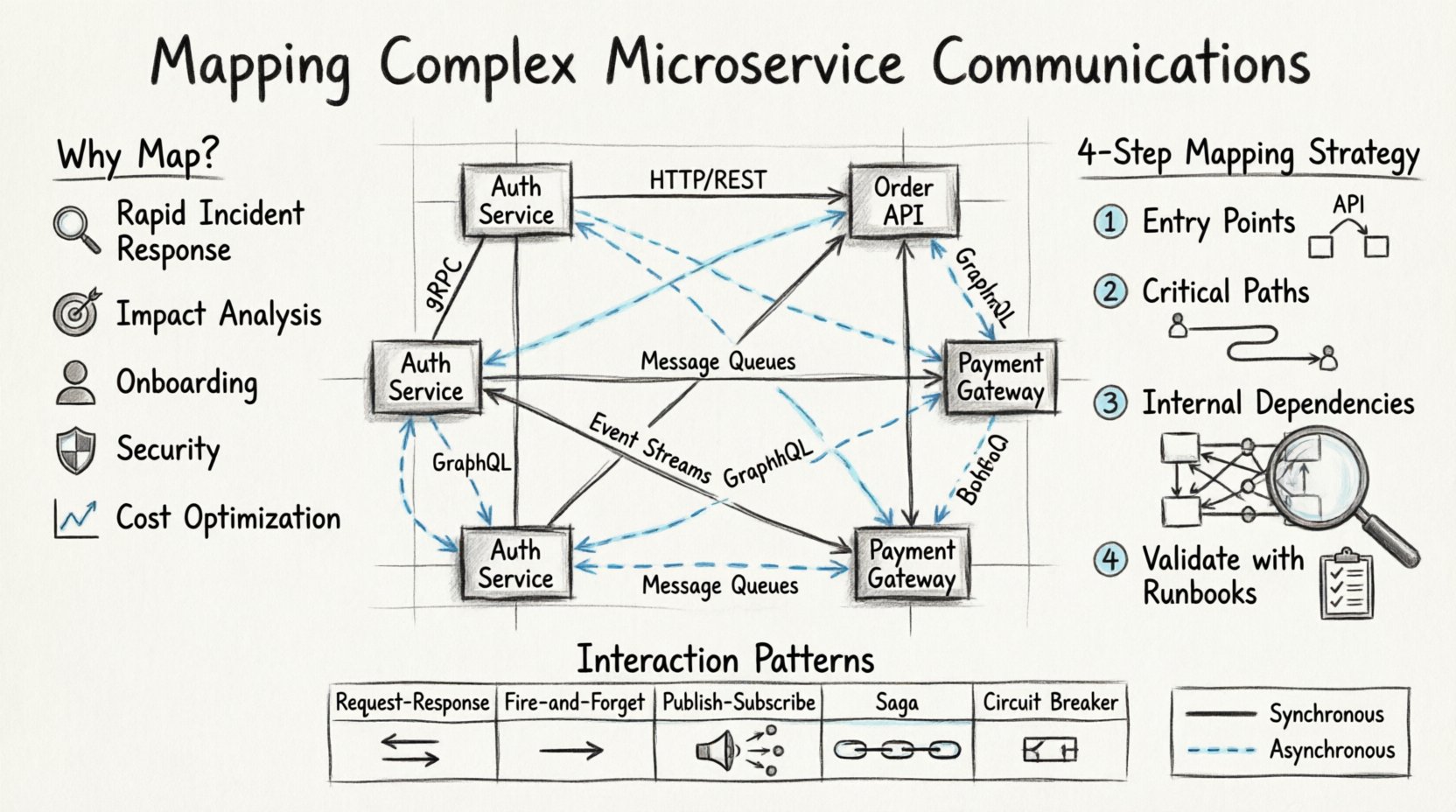
Pourquoi la visibilité est-elle importante dans les systèmes distribués 🧠
Lorsqu’un système est composé de dizaines ou de centaines de services, le nombre de chemins d’interaction potentiels croît de manière exponentielle. Une seule requête provenant d’un client peut traverser cinq services différents, déclencher deux tâches en arrière-plan et mettre à jour trois bases de données avant que la réponse ne soit retournée. Sans une représentation visuelle ou documentée de ce parcours, les ingénieurs s’appuient sur des connaissances fragmentées.
Voici les raisons fondamentales pour lesquelles cartographier les communications est essentiel :
- Réponse rapide aux incidents : Lorsque la latence augmente ou des erreurs surviennent, connaître le flux exact des données permet aux ingénieurs d’isoler rapidement le point de défaillance.
- Analyse des impacts : Avant de déployer un changement sur un service spécifique, vous devez savoir quels autres services dépendent de son contrat API actuel.
- Efficacité de l’intégration : Les nouveaux membres de l’équipe peuvent comprendre l’architecture du système sans avoir à suivre le code à travers chaque dépôt.
- Conformité en matière de sécurité : Comprendre le flux des données est essentiel pour identifier où les informations sensibles sont transmises et s’assurer qu’elles sont correctement chiffrées.
- Optimisation des coûts : Identifier les appels redondants ou les transferts de données inefficaces aide à réduire les dépenses d’infrastructure.
Toutefois, créer une carte ne consiste pas seulement à dessiner des boîtes et des lignes. Il s’agit de capturer la logique, les protocoles et les contraintes qui régissent le flux d’information.
Définir le périmètre de la communication 🚧
Avant de dessiner un seul diagramme, il est nécessaire de définir ce qui constitue un événement de communication. Dans les architectures de microservices, les interactions se divisent généralement en deux catégories principales : synchrones et asynchrones. Faire la distinction entre ces deux types est la première étape d’une cartographie précise.
Communication synchrone
Les interactions synchrones ont lieu lorsque l’appelant attend une réponse immédiate. Il s’agit du modèle classique de requête-réponse présent dans la plupart des applications web.
- HTTP/REST : Le protocole le plus courant. Un client envoie une requête et bloque jusqu’à ce que le serveur réponde.
- gRPC : Souvent utilisé pour la communication interne entre services en raison de ses performances et de son typage fort.
- GraphQL : Permet aux clients de demander des structures de données spécifiques, modifiant ainsi la manière dont les services exposent leurs points d’entrée.
Cartographier ces flux exige de documenter les points d’entrée, les charges attendues et les stratégies de gestion des erreurs. Si le Service A appelle le Service B, attend-il 5 secondes ? Que se passe-t-il si le Service B est indisponible ? Ces détails sont essentiels pour une carte complète.
Communication asynchrone
Les interactions asynchrones déconnectent l’expéditeur du destinataire. L’expéditeur envoie un message et continue le traitement sans attendre de réponse directe.
- Files de messages :Les services publient des messages dans une file d’attente, et les consommateurs les récupèrent lorsqu’ils sont prêts.
- Flux d’événements :Les services émettent des événements vers un journal ou un flux, que d’autres services souscrivent pour traitement.
- Travaux en arrière-plan :Tâches déclenchées par un événement mais exécutées ultérieurement.
Les flux asynchrones sont plus difficiles à représenter car la connexion est implicite. Il n’existe pas de lien direct entre l’expéditeur et le destinataire à l’exécution ; ils partagent un canal commun. La documentation de ces flux nécessite la liste des sujets, des schémas de messages et de la logique d’abonnement.
Schémas d’interaction et leurs implications 🔄
Comprendre le schéma d’interaction permet d’évaluer la fiabilité et la complexité du système. Ci-dessous se trouve une comparaison des schémas courants utilisés dans les architectures distribuées.
| Schéma | Direction | Fiabilité | Cas d’utilisation |
|---|---|---|---|
| Demande-Réponse | Synchrones | Élevée (nécessite des réessais) | APIs orientées utilisateur, besoins immédiats de données |
| Envoyer et oublier | Asynchrones | Moyenne (dépend de la file d’attente) | Journalisation, notifications, analyse |
| Publication-Abonnement | Asynchrones | Élevée (avec des files durables) | Changements d’état, événements interdomaines |
| Schéma Saga | Hybride | Élevée (transactions compensatoires) | Processus métier complexes à plusieurs étapes |
| Disjoncteur | Protecteur | Empêche les défaillances en chaîne | Empêche le surcharge des services en aval |
Lors de la cartographie de votre système, vous devez annoter chaque interaction entre services avec le modèle utilisé. Par exemple, un service appelant une base de données est synchrone. Un service envoyant un courriel de confirmation de commande est asynchrone. Un service orchestrant un flux de paiement utilisant plusieurs services pourrait utiliser le modèle Saga.
Une stratégie de cartographie étape par étape 🛠️
Comment passer d’une base de code chaotique à un diagramme clair ? Tenter de cartographier tout d’un coup conduit souvent à l’épuisement et à des données incomplètes. Une approche progressive donne de meilleurs résultats.
1. Identifier les points d’entrée
Commencez à la périphérie. Documentez la passerelle API ou le chargeur d’équilibre. Quelles requêtes externes entrent dans le système ? Quels protocoles utilisent-elles ? Cela définit la frontière de votre diagramme.
- Listez tous les points d’entrée publics.
- Identifiez les mécanismes d’authentification.
- Cartographiez les règles de routage qui dirigent le trafic vers les services internes.
2. Suivre les chemins critiques
Ne cherchez pas à cartographier chaque fonction individuelle. Concentrez-vous sur les flux métier critiques. Pour une plateforme de commerce électronique, il s’agirait du processus de paiement. Pour un réseau social, cela pourrait être la génération du fil d’actualité ou la livraison des notifications.
- Suivez une requête utilisateur unique du début à la fin.
- Notez chaque service touché au fil du chemin.
- Enregistrez les données échangées entre chaque étape.
3. Documenter les dépendances internes
Une fois les chemins critiques cartographiés, examinez l’intérieur. Comment les services communiquent-ils entre eux en dehors des flux principaux des utilisateurs ? Cela inclut les vérifications de santé, la récupération de configuration et les tâches de traitement par lots.
- Vérifiez les registres de services pour les pairs connus.
- Examinez les fichiers de configuration pour les noms de file d’attente ou les abonnements aux sujets.
- Examinez les manifestes d’orchestration de conteneurs pour les proxies sidecar.
4. Valider avec les runbooks
La documentation devient souvent obsolète. La meilleure méthode de validation consiste à utiliser la carte lors d’un incident. Si vous comptez sur un diagramme pour corriger un bug et que les étapes ne correspondent pas à la réalité, la carte doit être mise à jour. Traitez le diagramme comme une source de vérité qui doit être testée.
Gestion des flux asynchrones et des flux d’événements 📬
La communication asynchrone est là où nombre d’efforts de cartographie échouent. Puisqu’il n’y a pas de poignée de main directe, le couplage est masqué. Pour cartographier cela efficacement, vous devez examiner le niveau d’infrastructure.
Centralisation des connaissances sur les événements
Les événements sont souvent définis dans des registres de schémas ou des dépôts de documentation. Créer un index central de tous les événements vous permet de voir quels services publient et quels services s’abonnent.
- Schémas d’événements : Définissent la structure des données envoyées. Si le schéma change, le consommateur doit le savoir.
- Propriété du sujet : Qui est responsable du maintien du broker de messages ? Qui est responsable des consommateurs ?
- Surveillance du backlog : Un retard élevé dans une file d’attente indique un goulot d’étranglement de traitement, ce qui doit être noté dans l’état du système.
Visualisation du flux
Dans un diagramme, les flux asynchrones doivent avoir l’air différent des flux synchrones. Utilisez des lignes pointillées pour représenter les files de messages et des lignes pleines pour les appels directs. Étiquetez les lignes pointillées avec le nom de l’événement et le sujet.
Considérez le scénario où le service A publie un OrderCreated événement. Le service B et le service C s’abonnent tous deux à cet événement. Le service B traite le paiement, tandis que le service C met à jour l’inventaire. Sans carte, il est facile d’oublier l’existence du service C ou qu’il dépend du même événement que le service B.
Gestion des changements et de l’évolution 🌱
Une carte statique est une carte inutile. Les services évoluent, les API se cassent, et l’infrastructure change. L’objectif est de créer un processus où la carte se met à jour naturellement au fur et à mesure des modifications du code.
Découverte automatisée
Bien que la documentation manuelle soit précieuse, elle est sujette à l’écart. Là où c’est possible, utilisez des outils de découverte automatisée pour générer les données sous-jacentes de vos diagrammes. Les systèmes de traçage peuvent enregistrer les appels entre services et les exporter sous forme de graphes de dépendances.
- Intégrez les données de traçage dans le pipeline de documentation.
- Définissez des alertes pour les nouvelles dépendances qui apparaissent de manière inattendue.
- Utilisez l’analyse de code pour identifier les déclarations d’importation qui indiquent des dépendances potentielles.
Contrôle de version pour les diagrammes
Traitez les diagrammes d’architecture comme du code. Stockez-les dans le même dépôt que le code de l’application. Exigez que toute demande de fusion modifiant une interface de service inclue une mise à jour correspondante du diagramme.
- Utilisez un système de contrôle de version pour suivre les modifications au fil du temps.
- Revoyez les modifications des diagrammes dans les processus de revue de code.
- Gardez les versions historiques pour comprendre comment l’architecture a évolué.
Péchés courants dans la cartographie 🚫
Même avec une stratégie solide, les équipes tombent souvent dans des pièges qui réduisent l’utilité de la carte.
Dépendances circulaires
Lorsque le service A appelle le service B, et que le service B appelle le service A, vous créez une boucle. Cela rend le système fragile et difficile à déboguer. La cartographie doit mettre en évidence ces boucles afin qu’elles puissent être refactorisées.
- Identifiez les cycles dans le graphe de dépendances.
- Refactorisez pour briser le cycle en utilisant des événements ou des interfaces partagées.
- Documentez la raison du cycle si celui-ci ne peut pas être supprimé immédiatement.
Couplage caché
Les services pourraient partager une base de données ou un système de fichiers sans appels d’API explicites. Il s’agit d’un couplage serré déguisé en couplage lâche. Il doit être documenté clairement, car cela affecte les stratégies de déploiement.
- Vérifiez les montages de stockage partagés.
- Vérifiez les chaînes de connexion à la base de données pour les schémas partagés.
- Documentez explicitement les ressources partagées dans l’architecture.
Surconception du diagramme
Essayer de cartographier chaque appel de fonction conduit à un diagramme trop complexe à lire. Concentrez-vous sur les flux de haut niveau et les chemins critiques. Les détails peuvent être stockés dans les commentaires du code ou dans la documentation de l’API.
- Utilisez des niveaux d’abstraction. De haut niveau pour la direction, de bas niveau pour les ingénieurs.
- Liez la documentation détaillée de l’API aux nœuds du diagramme de haut niveau.
- Supprimez la logique interne inutile du diagramme.
L’élément humain des diagrammes 👥
La technologie n’est que la moitié du défi. L’autre moitié réside dans la capacité de l’équipe à comprendre et à utiliser la carte. Un diagramme que personne ne lit est pire qu’aucun diagramme du tout.
Standardisation de la notation
Assurez-vous que tous les membres de l’équipe comprennent les symboles utilisés. Si vous utilisez une couleur spécifique pour les flux asynchrones, chacun doit savoir que cette couleur représente ce protocole. La cohérence réduit la charge cognitive.
- Créez une légende pour vos diagrammes.
- Convenez de conventions de nommage pour les services.
- Définissez des icônes standard pour les bases de données, les files d’attente et les systèmes externes.
Accessibilité et distribution
Où est stocké le diagramme ? Si c’est enfoui dans un dossier personnel de documents, il est inaccessibles. Stockez-le dans un emplacement central, recherchable, accessible à tous les ingénieurs.
- Hébergez les diagrammes sur le wiki interne ou le site de documentation.
- Assurez-vous que les diagrammes sont correctement rendus dans les visualisateurs de markdown.
- Liez les diagrammes à partir des fichiers README des services.
Encouragement des mises à jour
Faites de la mise à jour de la carte une partie de la définition de « terminé ». Si un développeur modifie le code mais oublie la carte, le travail est incomplet. Ce changement culturel garantit que la documentation reste pertinente.
- Incluez les mises à jour du diagramme dans la liste de vérification des demandes de fusion.
- Félicitez les membres de l’équipe qui maintiennent la documentation à jour.
- Effectuez régulièrement des audits des cartes par rapport au système en cours d’exécution.
Débogage à l’aide de la carte 🐞
Le test ultime d’une carte de communication est son utilité lors d’un incident. Lorsque le système est lent ou défaillant, la carte devient un outil de diagnostic.
- Suivez la requête :Utilisez la carte pour identifier quel service de la chaîne est susceptible d’être le goulot d’étranglement.
- Vérifiez l’état de santé :Vérifiez si les dépendances cartographiées sont en cours d’exécution.
- Analyser les journaux : Recherchez les erreurs dans les services identifiés par la carte.
- Valider la configuration : Assurez-vous que la configuration correspond à la carte (par exemple, noms de files d’attente, URLs des points de terminaison).
Si la carte est précise, elle réduit considérablement le temps moyen de résolution (MTTR). Les ingénieurs peuvent éviter les suppositions et se concentrer sur le nœud spécifique qui nécessite une attention.
Maintenir la clarté au fil du temps ⏳
À mesure que le système grandit, la carte s’agrandira. Pour éviter qu’elle ne devienne un réseau embrouillé, vous devez gérer sa complexité.
- Vues en couches : Créez des diagrammes différents pour des publics variés. Des vues haut niveau pour les dirigeants, des vues détaillées pour les ingénieurs.
- Propriété des services : Attribuez la propriété de diagrammes spécifiques à des équipes spécifiques. Cela garantit qu’une personne est responsable de leur exactitude.
- Revue régulière : Programmez des revues trimestrielles de l’architecture pour supprimer le code mort et mettre à jour les flux.
- Boucles de retour : Permettez aux ingénieurs de proposer des corrections aux diagrammes lorsqu’ils rencontrent des incohérences en production.
En traitant la carte comme un artefact vivant, vous vous assurez qu’elle reste un atout précieux plutôt qu’un vestige historique. La complexité des microservices est inévitable, mais le chaos qui l’entoure est facultatif. Avec une approche disciplinée de la cartographie, vous pouvez naviguer dans le paysage distribué avec confiance et clarté.