











Dans les systèmes distribués modernes, la fiabilité d’un service backend dépend souvent de la manière dont il gère les requêtes concurrentes et les ressources partagées. L’un des problèmes les plus persistants et difficiles à reproduire dans ce domaine est le blocage. Un blocage se produit lorsque deux ou plusieurs processus ne peuvent pas progresser parce que chacun attend que l’autre libère une ressource. Ce état de blocage permanent peut paralyser l’ensemble du système, entraînant des incohérences de données, une indisponibilité du service et une frustration des utilisateurs. Pour atténuer ces risques, les architectes et les ingénieurs doivent aller au-delà des simples revues de code et adopter une approche visuelle de la conception du système. Les diagrammes de communication offrent une méthode structurée pour cartographier les interactions, identifier les points de contention potentiels et imposer des modèles de résilience avant même la rédaction du code.
Ce guide explore les mécanismes des blocages au sein des environnements backend et démontre comment les diagrammes de communication peuvent servir d’outil préventif. En visualisant le flux de contrôle et l’acquisition des ressources, les équipes peuvent repérer les dépendances circulaires et mettre en œuvre des stratégies pour les rompre. Nous aborderons les fondements théoriques, les techniques pratiques de visualisation et les modèles architecturaux spécifiques qui contribuent à un système résilient.
Comprendre les mécanismes d’un blocage 🛑
Avant d’aborder la prévention, il est nécessaire de comprendre les conditions qui entraînent un blocage. En informatique, un blocage n’est pas un événement aléatoire ; il résulte d’un ensemble spécifique de conditions se produisant simultanément. Ces conditions sont souvent appelées conditions de Coffman. Pour qu’un blocage existe, les quatre conditions suivantes doivent être simultanément remplies :
- Exclusion mutuelle : Au moins une ressource doit être détenue dans un mode non partageable. Un seul processus peut utiliser la ressource à tout moment donné.
- Détention et attente : Un processus doit détenir au moins une ressource tout en attendant d’acquérir d’autres ressources détenues par d’autres processus.
- Pas de préemption : Les ressources ne peuvent pas être retirées de force à un processus. Elles doivent être libérées volontairement par le processus qui les détient.
- Attente circulaire : Un ensemble de processus existe tel que P1 attend P2, P2 attend P3, et ainsi de suite, jusqu’à ce que Pn attende P1.
Dans une application monothread, les blocages sont rares. Cependant, dans les systèmes backend traitant des milliers de requêtes concurrentes, ces conditions sont faciles à satisfaire. Par exemple, si le Service A détient un verrou sur la ressource X et attend la ressource Y, tandis que le Service B détient la ressource Y et attend la ressource X, une attente circulaire se forme. Sans préemption ou un ordonnancement soigneux, le système se fige.
Le rôle des diagrammes de communication 📊
Les diagrammes de communication sont un type de diagramme du langage de modélisation unifié (UML). Alors que les diagrammes de séquence se concentrent sur le déroulement temporel des messages, les diagrammes de communication mettent l’accent sur l’organisation structurelle des objets et les liens entre eux. Dans le contexte de la résilience du backend, cette vision structurelle est cruciale. Elle permet aux concepteurs de voirquiparle à qui et quellesles ressources échangées, plutôt que simplement l’ordre dans lequel les messages arrivent.
Lors de la conception d’une architecture de microservices ou d’un backend monolithique complexe, les diagrammes de communication aident à répondre à des questions critiques :
- Quels services nécessitent un accès exclusif à la même table de base de données ?
- Y a-t-il des dépendances bidirectionnelles entre deux unités de traitement ?
- Une chaîne de requêtes revient-elle au point d’origine avant sa finalisation ?
- Quelle est la profondeur maximale du verrouillage imbriqué des ressources ?
En cartographiant ces interactions dès la phase de conception, les équipes peuvent identifier des scénarios de blocage potentiels qui pourraient rester invisibles lors d’une revue purement centrée sur le code. Le diagramme agit comme un contrat d’interaction, rendant explicites les hypothèses implicites.
Cartographier les dépendances des ressources 🗺️
Pour utiliser efficacement les diagrammes de communication afin d’éviter les blocages, le diagramme doit représenter les ressources, et non seulement le flux de données. Les diagrammes d’interaction standards montrent souvent des appels entre services. Toutefois, pour analyser les verrous, nous devons annoter les liens avec des identifiants de ressources. Cela exige un niveau d’abstraction légèrement plus élevé, où les nœuds représentent des processus ou des threads, et les liens représentent des ressources partagées ou des canaux de communication.
Étapes pour créer un diagramme conscient des blocages
- Identifier les ressources critiques :Listez toutes les états partagés, tels que des lignes de base de données, des descripteurs de fichiers ou des tampons mémoire. Attribuez-leur des identifiants uniques.
- Définir la propriété :Déterminez quel service ou quel thread contrôle actuellement quelle ressource. Indiquez-le sur le diagramme.
- Suivre les chemins d’acquisition :Tracez des flèches indiquant la demande d’une ressource. Étiquetez la flèche avec le nom de la ressource.
- Mettre en évidence les états d’attente :Utilisez une notation spécifique pour indiquer quand un processus est bloqué en attente d’une ressource.
- Analyser les cycles :Recherchez des boucles fermées sur le diagramme où le Processus A attend le Processus B, qui attend à son tour le Processus A.
Identification des motifs d’attente circulaire 🔁
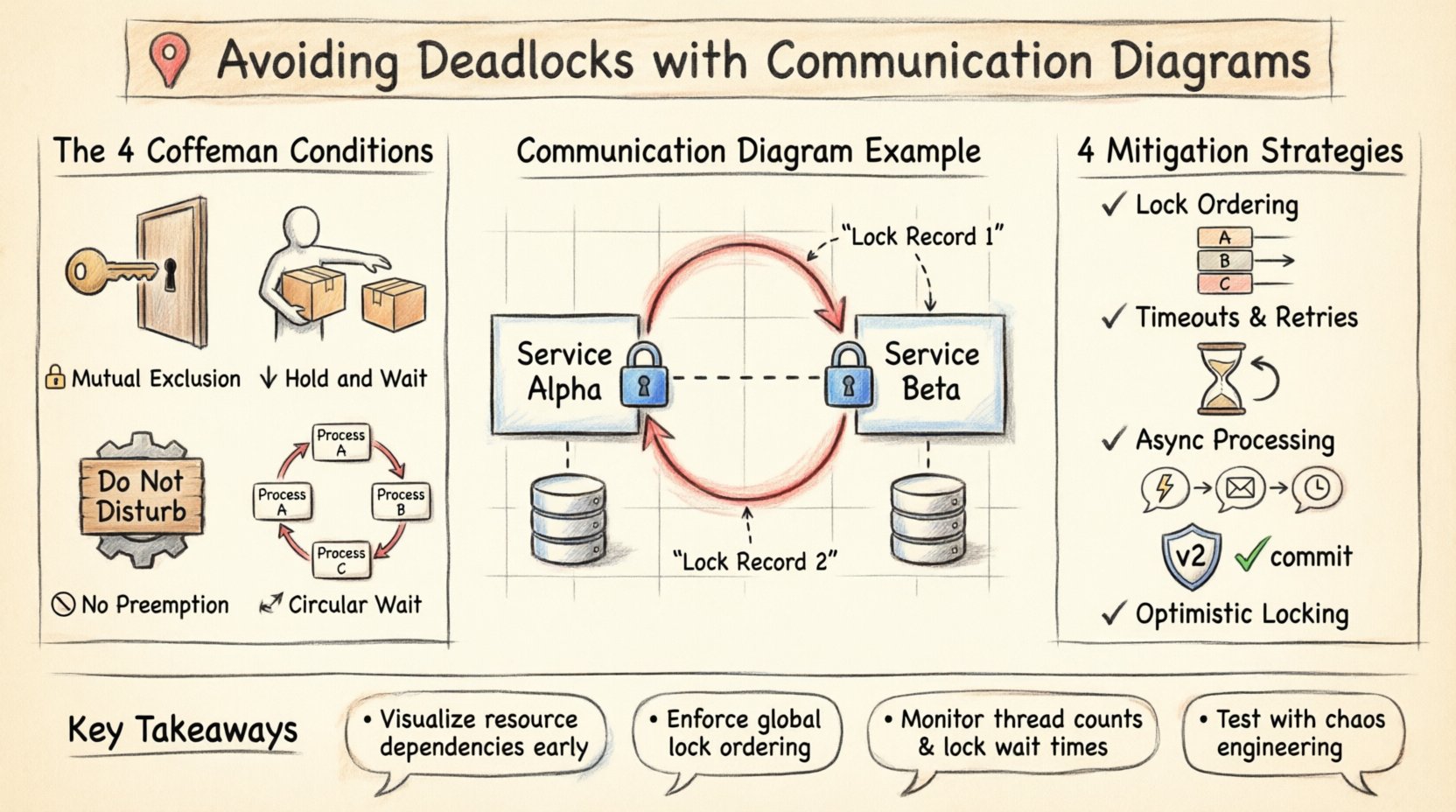
Le motif le plus dangereux dans la conception de système est la dépendance circulaire. Sur un diagramme de communication, cela apparaît sous la forme d’une boucle fermée d’interactions. Considérez un scénario impliquant deux services, le Service Alpha et le Service Beta.
- Le Service Alpha lance une transaction et verrouille l’enregistrement 1.
- Le Service Alpha demande un verrou sur l’enregistrement 2 au Service Beta.
- Le Service Beta détient déjà un verrou sur l’enregistrement 2, mais doit mettre à jour l’enregistrement 1, qui est détenu par Alpha.
Sur une représentation visuelle, cette boucle est immédiatement évidente. Le diagramme montre Alpha pointant vers Beta, et Beta pointant à nouveau vers Alpha, chacun exigeant la ressource détenue par l’autre. Sans diagramme, cette logique ne serait détectée qu’en cas de panne en production ou lors d’un test de charge complexe.
Scénarios courants conduisant à la circularité
- Propagation des transactions :Lorsqu’une transaction distribuée exige que plusieurs services s’engagent dans un ordre spécifique, mais que cet ordre n’est pas respecté.
- Appels imbriqués :Une fonction appelle une autre fonction qui finit par appeler la fonction d’origine, créant ainsi une chaîne de verrous récursive.
- Cache partagé :Plusieurs services tentant de mettre à jour la même entrée mise en cache simultanément, sans mécanisme de verrouillage distribué.
- Clés étrangères de base de données :Mises à jour sur des tables liées qui exigent des verrous sur les deux tables, où l’ordre des mises à jour diffère entre les services.
Techniques stratégiques de mitigation 🛠️
Dès qu’un diagramme de communication révèle un blocage potentiel, des modifications architecturales spécifiques sont nécessaires. Il n’existe pas de solution unique applicable à tous les systèmes, mais plusieurs stratégies éprouvées existent pour briser les conditions de Coffman.
1. Ordre des verrous
Il s’agit de la méthode la plus efficace pour prévenir l’attente circulaire. Le système doit imposer un ordre global des ressources. Si chaque processus demande les ressources dans le même ordre (par exemple, la ressource A avant la ressource B), une boucle ne peut pas se former. Sur un diagramme de communication, cela signifie s’assurer que toutes les liaisons demandant la ressource X sont établies avant que n’importe quelle liaison ne demande la ressource Y.
2. Délais d’attente et nouvelles tentatives
Même avec un ordre, une contention est possible. Mettre en place un délai d’attente lors de l’acquisition d’une ressource garantit qu’un processus ne reste pas bloqué indéfiniment. Si un verrou ne peut pas être obtenu dans un délai spécifié, le processus libère ses ressources actuelles et réessaie. Cela empêche le système de se figer de manière permanente, bien qu’il puisse introduire une latence.
3. Traitement asynchrone
Passer des requêtes synchrones à des architectures événementielles asynchrones peut réduire la contention. Au lieu d’attendre la libération d’un verrou, un service publie un événement et continue son traitement. Lorsque la ressource devient disponible, un consommateur gère la mise à jour. Cela découple le moment d’utilisation des ressources.
4. Verrouillage optimiste
Plutôt que d’acquérir un verrou avant de lire ou de modifier des données, le système vérifie les conflits au moment du commit. Si un autre processus a modifié les données depuis la lecture, la transaction échoue et doit être réessayée. Cela réduit le temps de détention des verrous, minimisant ainsi l’intervalle de risque de blocage.
Comparaison des stratégies de prévention
| Stratégie | Empêche la condition | Complexité | Impact sur les performances |
|---|---|---|---|
| Ordre des verrous | Attente circulaire | Élevée | Faible |
| Délais d’attente | Détention et attente (indirectement) | Faible | Moyen (nouvelles tentatives) |
| Verrouillage optimiste | Exclusion mutuelle (à long terme) | Moyen | Variable |
| Flux asynchrone | Détention et attente | Élevée | Faible |
Étapes de mise en œuvre pour une analyse basée sur des diagrammes
Pour intégrer cette approche à votre flux de développement, suivez ces étapes :
- Effectuez une revue de conception : Avant d’écrire du code, créez le diagramme de communication pour les nouvelles fonctionnalités. Concentrez-vous sur les chemins d’accès aux données.
- Annotez l’utilisation des ressources :Marquez chaque écriture dans la base de données, mise à jour du cache ou opération sur fichier sur le diagramme.
- Exécutez un algorithme de détection de cycles :Si vous utilisez des outils automatisés, appliquez des algorithmes de graphes pour détecter les cycles dans le graphe de dépendances dérivé du diagramme.
- Refactorisez pour l’indépendance :Si un cycle est détecté, refactorisez le code pour rompre la dépendance. Cela pourrait impliquer l’introduction d’un service médiateur ou le changement du modèle de données.
- Validez avec des tests de charge :Simulez une forte concurrence pour vous assurer que les motifs d’interblocage ne se manifestent pas sous charge.
Surveillance et observabilité 🧪
Même avec une conception soigneuse, les conditions d’exécution peuvent évoluer. Les outils de surveillance doivent être configurés pour détecter les signes d’interblocage. Les métriques clés incluent :
- Nombre de threads :Une augmentation soudaine du nombre de threads bloqués peut indiquer une contention de ressources.
- Temps d’attente pour les verrous :Si le temps moyen d’acquisition d’un verrou augmente significativement, la contention augmente.
- Annulations de transactions :Un taux élevé d’annulations de transactions dues à un timeout ou à un conflit suggère que les stratégies de verrouillage sont trop agressives.
- Journaux de détection d’interblocage :Certains moteurs de base de données et systèmes d’exploitation journalisent les événements d’interblocage. Ces journaux doivent être intégrés au système central de journalisation.
Étude de cas : flux d’interaction entre services
Prenons un backend générique de commerce électronique gérant les commandes et les stocks. Le service A gère les commandes, et le service B gère les stocks.
Scénario :Le service A crée une commande et verrouille l’ID de commande. Il appelle ensuite le service B pour réserver les stocks. Le service B verrouille l’ID de stock. Pour mettre à jour l’état de la commande, le service B doit envoyer un rappel au service A, ce qui nécessite de verrouiller à nouveau l’ID de commande.
L’interblocage :Si le service A détient l’ID de commande et attend que le service B libère l’ID de stock, mais que le service B ne peut pas terminer sans que le service A libère l’ID de commande (via le rappel), un interblocage se produit. Il s’agit d’un scénario de verrouillage imbriqué.
La solution :En utilisant un diagramme de communication, cette boucle devient visible. La solution consiste à rompre la dépendance. Le service B devrait mettre à jour les stocks de manière asynchrone ou utiliser un identifiant de transaction séparé qui n’exige pas de réverrouiller l’ID de commande détenue par le service A. Le diagramme montrerait alors un flux unidirectionnel de A vers B, sans chemin de retour nécessitant le verrou d’origine.
Considérations sur le verrouillage distribué
Dans les environnements distribués, les verrous sont souvent gérés par des services externes plutôt que par l’application elle-même. Cela introduit une latence réseau et le risque de défaillances partielles. Les diagrammes de communication doivent tenir compte du lien réseau comme point potentiel de défaillance. Si le lien entre le service A et le gestionnaire de verrous échoue, le service A pourrait penser qu’il détient le verrou alors qu’un autre service le détient.
Pour y remédier, le diagramme doit inclure un nœud « Gestionnaire de verrous ». Les interactions avec ce nœud doivent être idempotentes et limitées dans le temps. La conception doit garantir qu’en cas de crash d’un service, le verrou est automatiquement libéré après expiration de la durée de bail. Cela empêche la condition « détenir et attendre » de persister indéfiniment.
Tests de résilience
Les diagrammes de conception sont théoriques. Des tests dans le monde réel sont nécessaires pour valider la résilience. Cela inclut :
- Ingénierie du chaos : Introduire intentionnellement une latence ou des défaillances dans les liens réseau indiqués sur le diagramme pour vérifier si le système se rétablit ou bloque.
- Tests de charge : Exécuter des requêtes concurrentes correspondant aux modèles identifiés sur le diagramme pour vérifier que l’ordre des verrous fonctionne sous charge.
- Analyse statique : Utiliser des outils pour analyser la base de code afin de détecter d’éventuelles violations de l’ordre des verrous correspondant à la logique du diagramme.
Conclusion
Éviter les blocages n’est pas simplement un exercice de codage ; c’est un défi de conception système. En utilisant des diagrammes de communication, les équipes peuvent visualiser le réseau complexe des dépendances de ressources qui entraînent des blocages du système. Cette approche déplace le focus du débogage réactif vers une prévention proactive. Comprendre les quatre conditions d’un blocage, cartographier les chemins d’acquisition des ressources, et imposer un ordre strict ou des modèles asynchrones sont des étapes essentielles pour construire une infrastructure backend résiliente. Bien qu’aucun système ne soit à l’abri des problèmes de concurrence, une approche visuelle structurée réduit considérablement le risque et la complexité de la gestion des ressources partagées. L’application cohérente de ces principes garantit que les services restent réactifs et que les données restent cohérentes, même sous forte charge et en cas de défaillance.