











In der Landschaft moderner verteilter Systeme ist Komplexität kein Fehler; sie ist eine Eigenschaft der Skalierung. Wenn Organisationen wachsen, zerbrechen monolithische Architekturen in Microservices. Dieser Wandel bietet Agilität und Resilienz, bringt aber auch eine erhebliche Herausforderung mit sich: das Verständnis dafür, wie diese unabhängigen Einheiten miteinander kommunizieren. Ohne eine klare Karte der Kommunikationsflüsse navigieren Teams durch ein Labyrinth von Abhängigkeiten, was zu langen Debugging-Zyklen, unerwünschten Nebenwirkungen und instabilen Bereitstellungen führt.
Diese Anleitung untersucht einen praktischen Ansatz zur Abbildung komplexer Microservice-Kommunikationen. Wir werden über abstrakte Theorien hinausgehen, um die Mechanismen der Dienstinteraktion, die Methoden zur Dokumentation dieser Beziehungen und die Strategien zur Aufrechterhaltung der Klarheit im Verlauf der Systementwicklung zu untersuchen. Das Ziel ist nicht, ein statisches Dokument zu erstellen, sondern ein lebendiges Verständnis Ihrer verteilten Architektur aufzubauen.
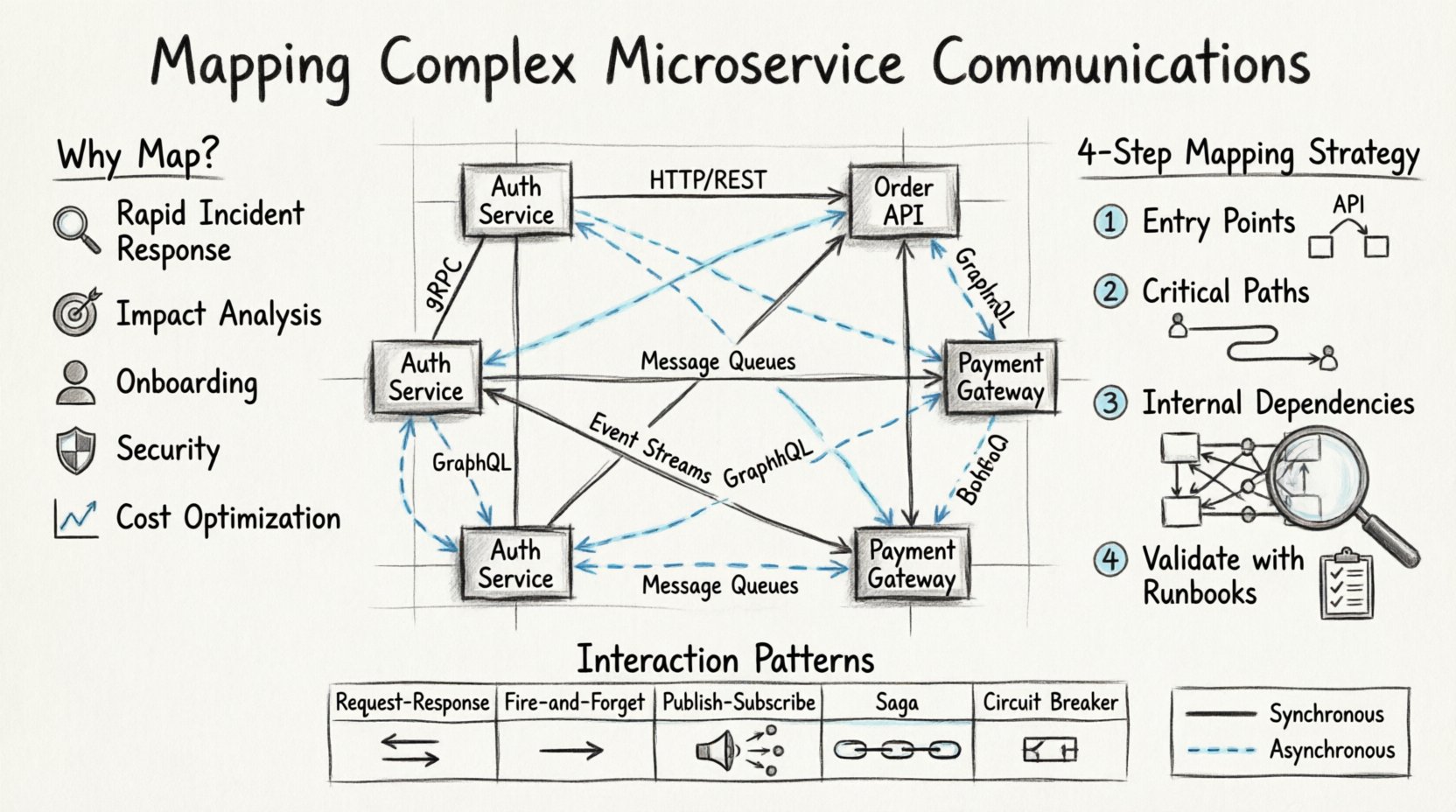
Warum Sichtbarkeit in verteilten Systemen wichtig ist 🧠
Wenn ein System aus Dutzenden oder Hunderten von Diensten besteht, wächst die Anzahl möglicher Interaktionspfade exponentiell. Eine einzelne Anfrage von einem Client kann fünf verschiedene Dienste durchlaufen, zwei Hintergrundaufgaben auslösen und drei Datenbanken aktualisieren, bevor eine Antwort zurückgegeben wird. Ohne eine visuelle oder dokumentierte Darstellung dieses Pfades verlassen sich Ingenieure auf fragmentiertes Wissen.
Hier sind die zentralen Gründe, warum die Abbildung der Kommunikation entscheidend ist:
- Schnelle Reaktion auf Störungen: Wenn Latenzspitzen oder Fehler auftreten, ermöglicht das Wissen um den genauen Datenfluss, den Fehlerort schnell zu isolieren.
- Auswirkungsanalyse: Bevor eine Änderung an einem bestimmten Dienst bereitgestellt wird, müssen Sie wissen, welche anderen Dienste von seinem aktuellen API-Vertrag abhängen.
- Effizienz bei der Einarbeitung: Neue Teammitglieder können die Systemarchitektur verstehen, ohne den Code durch jedes Repository verfolgen zu müssen.
- Sicherheitskonformität: Das Verständnis des Datenflusses ist entscheidend, um festzustellen, wo sensible Informationen übertragen werden, und sicherzustellen, dass sie angemessen verschlüsselt werden.
- Kostenoptimierung: Die Identifizierung überflüssiger Aufrufe oder ineffizienter Datenübertragungen hilft, die Infrastrukturkosten zu senken.
Allerdings geht es beim Erstellen einer Karte nicht nur darum, Kästchen und Linien zu zeichnen. Es geht darum, die Logik, die Protokolle und die Beschränkungen zu erfassen, die den Informationsfluss steuern.
Abgrenzung des Kommunikationsumfangs 🚧
Bevor ein einziger Diagramm gezeichnet wird, ist es notwendig zu definieren, was einen Kommunikationsereignis ausmacht. In Microservice-Architekturen fallen Interaktionen in der Regel in zwei Hauptkategorien: synchron und asynchron. Die Unterscheidung zwischen diesen ist der erste Schritt bei der genauen Abbildung.
Synchroner Kommunikationsfluss
Synchronen Interaktionen treten auf, wenn der Aufrufer auf eine sofortige Antwort wartet. Dies ist das traditionelle Anfrage-Antwort-Modell, das in den meisten Webanwendungen zu finden ist.
- HTTP/REST: Das am häufigsten verwendete Protokoll. Ein Client sendet eine Anfrage und blockiert, bis der Server antwortet.
- gRPC: Häufig für interne Dienst-zu-Dienst-Kommunikation aufgrund seiner Leistungsfähigkeit und starken Typisierung verwendet.
- GraphQL: Erlaubt Clients, spezifische Datenstrukturen anzufordern, was die Art und Weise verändert, wie Dienste ihre Endpunkte verfügbar machen.
Die Abbildung dieser Flüsse erfordert die Dokumentation der Endpunkte, der erwarteten Nutzlasten und der Fehlerbehandlungsstrategien. Wenn Dienst A Dienst B aufruft, wartet er dann 5 Sekunden? Was geschieht, wenn Dienst B nicht erreichbar ist? Diese Details sind entscheidend für eine vollständige Karte.
Asynchroner Kommunikationsfluss
Asynchrone Interaktionen entkoppeln den Absender vom Empfänger. Der Absender initiiert eine Nachricht und setzt die Verarbeitung fort, ohne auf eine direkte Antwort zu warten.
- Nachrichtenwarteschlangen:Dienste veröffentlichen Nachrichten in einer Warteschlange, und Verbraucher nehmen sie auf, wenn sie bereit sind.
- Ereignisströme:Dienste senden Ereignisse an ein Protokoll oder einen Strom, zu dem andere Dienste sich für die Verarbeitung anmelden.
- Hintergrundaufgaben:Aufgaben, die durch ein Ereignis ausgelöst werden, aber später ausgeführt werden.
Asynchrone Abläufe sind schwerer zu dokumentieren, da die Verbindung implizit ist. Es gibt keine direkte Verbindung zwischen Absender und Empfänger zur Laufzeit; sie teilen sich einen gemeinsamen Kanal. Die Dokumentation erfordert die Auflistung der Themen, der Nachrichtenschemata und der Abonnementlogik.
Interaktionsmuster und ihre Auswirkungen 🔄
Das Verständnis des Interaktionsmusters hilft, die Zuverlässigkeit und Komplexität des Systems zu bestimmen. Unten finden Sie einen Vergleich gängiger Muster, die in verteilten Architekturen verwendet werden.
| Muster | Richtung | Zuverlässigkeit | Anwendungsfall |
|---|---|---|---|
| Anfrage-Antwort | Synchron | Hoch (erfordert Wiederholungen) | Benutzerorientierte APIs, sofortige Datenbedürfnisse |
| Feuern und Vergessen | Asynchron | Mittel (hängt von der Warteschlange ab) | Protokollierung, Benachrichtigungen, Analytik |
| Veröffentlichen-Abonnieren | Asynchron | Hoch (mit dauerhaften Warteschlangen) | Zustandsänderungen, überdomänenhafte Ereignisse |
| Saga-Muster | Hybrid | Hoch (durch Kompensationstransaktionen) | Komplexe mehrstufige Geschäftsprozesse |
| Schaltkreisunterbrecher | Schützend | Verhindert Kettenreaktionen | Verhindert Überlastung nachgeschalteter Dienste |
Beim Abbilden Ihres Systems sollten Sie jede Dienstinteraktion mit dem verwendeten Muster dokumentieren. Zum Beispiel ist ein Dienst, der eine Datenbank aufruft, synchron. Ein Dienst, der eine Bestellbestätigungs-E-Mail sendet, ist asynchron. Ein Dienst, der einen Checkout-Fluss mit mehreren Diensten orchestriert, könnte das Saga-Muster verwenden.
Eine schrittweise Abbildungsstrategie 🛠️
Wie gelangen Sie von einer chaotischen Codebasis zu einem klaren Diagramm? Das Versuch, alles auf einmal abzubilden, führt oft zu Überforderung und unvollständigen Daten. Ein schrittweiser Ansatz erzielt bessere Ergebnisse.
1. Identifizieren Sie die Eingangspunkte
Beginnen Sie am Rand. Dokumentieren Sie den API-Gateway oder den Lastverteiler. Welche externen Anfragen betreten das System? Welche Protokolle verwenden sie? Dies definiert die Grenze Ihres Diagramms.
- Listen Sie alle öffentlichen Endpunkte auf.
- Identifizieren Sie die Authentifizierungsmechanismen.
- Zeichnen Sie die Routing-Regeln auf, die den Datenverkehr zu internen Diensten leiten.
2. Verfolgen Sie die kritischen Pfade
Versuchen Sie nicht, jede einzelne Funktion abzubilden. Konzentrieren Sie sich auf die kritischen Geschäftsabläufe. Bei einer E-Commerce-Plattform wäre dies der Zahlungsprozess. Bei einem sozialen Netzwerk könnte es die Erzeugung des Feeds oder die Zustellung von Benachrichtigungen sein.
- Verfolgen Sie eine einzelne Benutzeranfrage von Anfang bis Ende.
- Notieren Sie jeden Dienst, der im Verlauf berührt wird.
- Notieren Sie die Daten, die zwischen jedem Schritt übertragen werden.
3. Dokumentieren Sie interne Abhängigkeiten
Sobald die kritischen Pfade abgebildet sind, schauen Sie nach innen. Wie kommunizieren Dienste miteinander außerhalb der Hauptbenutzerflüsse? Dazu gehören Gesundheitsprüfungen, Abruf von Konfigurationen und Batch-Verarbeitungsaufgaben.
- Prüfen Sie Dienstregistrierungen auf bekannte Nachbarn.
- Überprüfen Sie Konfigurationsdateien auf Warteschlangennamen oder Themenabonnements.
- Untersuchen Sie Manifeste zur Container-Orchestrierung auf Sidecar-Proxys.
4. Validierung mit Runbooks
Dokumentation wird oft veraltet. Die beste Validierungsmethode ist die Nutzung des Diagramms während eines Vorfalls. Wenn Sie sich auf ein Diagramm verlassen, um einen Fehler zu beheben, und die Schritte stimmen nicht mit der Realität überein, muss das Diagramm aktualisiert werden. Behandeln Sie das Diagramm als Quelle der Wahrheit, die getestet werden muss.
Umgang mit asynchronen Abläufen und Ereignisströmen 📬
Asynchrone Kommunikation ist der Bereich, in dem viele Abbildungsversuche scheitern. Da es keinen direkten Handshake gibt, ist die Kopplung versteckt. Um dies effektiv abzubilden, müssen Sie die Infrastruktur-Ebene betrachten.
Zentralisierung des Ereigniswissens
Ereignisse werden oft in Schema-Registern oder Dokumentations-Repositories definiert. Die Erstellung eines zentralen Indexes aller Ereignisse ermöglicht es Ihnen, zu erkennen, welche Dienste veröffentlichen und welche abonnieren.
- Ereignisschemata: Definieren die Struktur der übertragenen Daten. Wenn sich das Schema ändert, muss der Empfänger davon wissen.
- Themenbesitz: Wer ist für die Wartung des Nachrichtenbrokers verantwortlich? Wer ist für die Verbraucher verantwortlich?
- Backlog-Überwachung: Ein hoher Verzögerungszeitraum in einer Warteschlange deutet auf eine Verarbeitungsbremse hin, die im Systemstatus vermerkt werden sollte.
Visualisierung des Flows
In einer Darstellung sollten asynchrone Abläufe anders aussehen als synchrone. Verwenden Sie gestrichelte Linien zur Darstellung von Nachrichtenwarteschlangen und durchgezogene Linien für direkte Aufrufe. Beschriften Sie die gestrichelten Linien mit dem Ereignisnamen und dem Thema.
Berücksichtigen Sie die Situation, in der Service A ein BestellErstelltEreignis. Service B und Service C melden sich beide dafür an. Service B verarbeitet die Zahlung, während Service C das Lager aktualisiert. Ohne eine Karte ist es leicht, zu vergessen, dass Service C existiert oder dass er vom selben Ereignis abhängt wie Service B.
Verwaltung von Änderungen und Evolution 🌱
Eine statische Karte ist eine nutzlose Karte. Dienste entwickeln sich weiter, APIs brechen ab und die Infrastruktur ändert sich. Ziel ist es, einen Prozess zu schaffen, bei dem die Karte sich natürlich ändert, wenn sich der Code ändert.
Automatisierte Entdeckung
Während manuelle Dokumentation wertvoll ist, neigt sie zur Abweichung. Wo immer möglich, sollten automatisierte Entdeckungstools verwendet werden, um die zugrundeliegenden Daten für Ihre Diagramme zu generieren. Verfolgungssysteme können Dienst-zu-Dienst-Aufrufe aufzeichnen und als Abhängigkeitsgraphen exportieren.
- Integrieren Sie Verfolgungsdaten in die Dokumentationspipeline.
- Stellen Sie Warnungen für neue Abhängigkeiten ein, die unerwartet auftreten.
- Verwenden Sie Codeanalyse, um Importanweisungen zu identifizieren, die potenzielle Abhängigkeiten anzeigen.
Versionskontrolle für Diagramme
Behandeln Sie Architekturdiagramme wie Code. Speichern Sie sie im selben Repository wie den Anwendungscode. Fordern Sie an, dass jeder Pull Request, der eine Dienst-Schnittstelle ändert, eine entsprechende Aktualisierung des Diagramms enthält.
- Verwenden Sie ein Versionskontrollsystem, um Änderungen im Zeitverlauf zu verfolgen.
- Überprüfen Sie Diagrammänderungen in den Code-Review-Prozessen.
- Behalten Sie historische Versionen bei, um zu verstehen, wie sich die Architektur verändert hat.
Häufige Fehler bei der Erstellung von Karten 🚫
Selbst mit einer soliden Strategie geraten Teams oft in Fallen, die die Nützlichkeit der Karte verringern.
Zirkuläre Abhängigkeiten
Wenn Service A Service B aufruft und Service B Service A aufruft, entsteht eine Schleife. Dies macht das System anfällig und schwer zu debuggen. Die Abbildung sollte diese Schleifen hervorheben, damit sie refaktorisiert werden können.
- Identifizieren Sie Zyklen im Abhängigkeitsgraphen.
- Refaktorisieren Sie, um den Zyklus mithilfe von Ereignissen oder gemeinsamen Schnittstellen zu brechen.
- Dokumentieren Sie den Grund für den Zyklus, falls er nicht sofort entfernt werden kann.
Versteckte Kopplung
Dienste könnten eine Datenbank oder ein Dateisystem ohne explizite API-Aufrufe teilen. Dies ist enge Kopplung, die als lose Kopplung getarnt ist. Sie muss klar dokumentiert werden, da sie die Bereitstellungsstrategien beeinflusst.
- Überprüfen Sie auf gemeinsam genutzte Speicher-Mounts.
- Überprüfen Sie die Datenbankverbindungszeichenfolgen auf gemeinsame Schemas.
- Dokumentieren Sie gemeinsam genutzte Ressourcen explizit in der Architektur.
Überkonzipieren des Diagramms
Versuchen, jeden einzelnen Funktionsaufruf abzubilden, führt zu einem Diagramm, das zu komplex zum Lesen ist. Konzentrieren Sie sich auf die groben Abläufe und die kritischen Pfade. Details können in Codekommentaren oder in der API-Dokumentation gespeichert werden.
- Verwenden Sie Abstraktionsebenen. Hohe Ebene für Management, niedrige Ebene für Ingenieure.
- Verknüpfen Sie detaillierte API-Dokumentationen mit den Knoten des Diagramms auf hoher Ebene.
- Entfernen Sie unnötige interne Logik aus der Karte.
Der menschliche Faktor bei Diagrammen 👥
Die Technologie ist nur die Hälfte der Herausforderung. Die andere Hälfte ist die Fähigkeit des Teams, die Karte zu verstehen und zu nutzen. Ein Diagramm, das niemand liest, ist schlimmer als gar kein Diagramm.
Standardisierung der Notation
Stellen Sie sicher, dass jedes Teammitglied die verwendeten Symbole versteht. Wenn Sie eine bestimmte Farbe für asynchrone Abläufe verwenden, muss jedes Teammitglied wissen, dass diese Farbe dieses Protokoll darstellt. Konsistenz verringert die kognitive Belastung.
- Erstellen Sie eine Legende für Ihre Diagramme.
- Einigen Sie sich auf Namenskonventionen für Dienste.
- Definieren Sie Standard-Symbole für Datenbanken, Warteschlangen und externe Systeme.
Zugänglichkeit und Verteilung
Wo ist das Diagramm gespeichert? Wenn es in einem persönlichen Dokumentenordner vergraben ist, ist es nicht zugänglich. Speichern Sie es an einem zentralen, durchsuchbaren Ort, der für alle Ingenieure zugänglich ist.
- Stellen Sie Diagramme auf der internen Wiki- oder Dokumentationsseite bereit.
- Stellen Sie sicher, dass die Diagramme in Markdown-Betrachtern korrekt dargestellt werden.
- Verknüpfen Sie die Diagramme mit den Service-README-Dateien.
Förderung von Aktualisierungen
Machen Sie das Aktualisieren der Karte zum Teil der Definition von „Fertiggestellt“. Wenn ein Entwickler den Code ändert, aber die Karte vergisst, ist die Arbeit unvollständig. Diese kulturelle Veränderung sorgt dafür, dass die Dokumentation aktuell bleibt.
- Fügen Sie Aktualisierungen des Diagramms in die Pull-Request-Checkliste ein.
- Bewerten Sie Teammitglieder, die die Dokumentation aktuell halten.
- Führen Sie regelmäßig Audits der Karten im Vergleich zum laufenden System durch.
Debuggen mit der Karte 🐞
Der ultimative Test für eine Kommunikationskarte ist ihre Nützlichkeit während eines Vorfalls. Wenn das System langsam ist oder ausgefallen ist, wird die Karte zu einem Diagnosewerkzeug.
- Verfolgen Sie die Anfrage:Verwenden Sie die Karte, um zu identifizieren, welcher Dienst in der Kette wahrscheinlich der Engpass ist.
- Prüfen Sie den Gesundheitszustand:Stellen Sie sicher, dass die abgebildeten Abhängigkeiten aktiv und laufend sind.
- Protokolle analysieren:Suchen Sie nach Fehlern in den durch die Karte identifizierten Diensten.
- Konfiguration überprüfen:Stellen Sie sicher, dass die Konfiguration mit der Karte übereinstimmt (z. B. Warteschlangennamen, Endpunkt-URLs).
Wenn die Karte genau ist, verringert sie die durchschnittliche Zeit bis zur Behebung (MTTR) erheblich. Ingenieure können das Raten umgehen und sich auf den spezifischen Knoten konzentrieren, der Aufmerksamkeit bedarf.
Klarheit im Laufe der Zeit erhalten ⏳
Wenn das System skaliert, wird die Karte wachsen. Um zu verhindern, dass sie zu einem verwirrenden Netzwerk wird, müssen Sie ihre Komplexität managen.
- Schichtierte Ansichten:Erstellen Sie verschiedene Diagramme für unterschiedliche Zielgruppen. Hochschichtige für Führungskräfte, detaillierte für Ingenieure.
- Dienstliche Verantwortung:Weisen Sie bestimmten Diagrammen bestimmte Teams zu. Dadurch ist sichergestellt, dass jemand für die Genauigkeit verantwortlich ist.
- Regelmäßige Überprüfungen:Planen Sie vierteljährliche Überprüfungen der Architektur, um toten Code zu entfernen und Abläufe zu aktualisieren.
- Feedback-Schleifen:Erlauben Sie Ingenieuren, Korrekturen an den Diagrammen vorzuschlagen, wenn sie in der Produktion Abweichungen feststellen.
Indem Sie die Karte als lebendiges Artefakt behandeln, stellen Sie sicher, dass sie eine wertvolle Ressource bleibt und keine historische Reliquie wird. Die Komplexität von Mikrodiensten ist unvermeidlich, doch das Chaos um sie herum ist freiwillig. Mit einer disziplinierten Herangehensweise an die Karten erstellung können Sie die verteilte Landschaft mit Vertrauen und Klarheit bewältigen.