











В ландшафте современных распределенных систем сложность — это не ошибка, а особенность масштабирования. По мере роста организаций монолитные архитектуры распадаются на микросервисы. Этот переход обеспечивает гибкость и устойчивость, но порождает серьезную проблему: понимание того, как эти независимые компоненты общаются между собой. Без четкой карты потоков коммуникаций команды бродят по лабиринту зависимостей, что приводит к медленным циклам отладки, непредвиденным последствиям и хрупким развертываниям.
В этом руководстве рассматривается практический подход к картированию сложных коммуникаций микросервисов. Мы выйдем за рамки абстрактной теории и рассмотрим механику взаимодействия сервисов, методы документирования этих связей и стратегии поддержания ясности по мере эволюции системы. Цель — не создание статического документа, а формирование живого понимания вашей распределенной архитектуры.
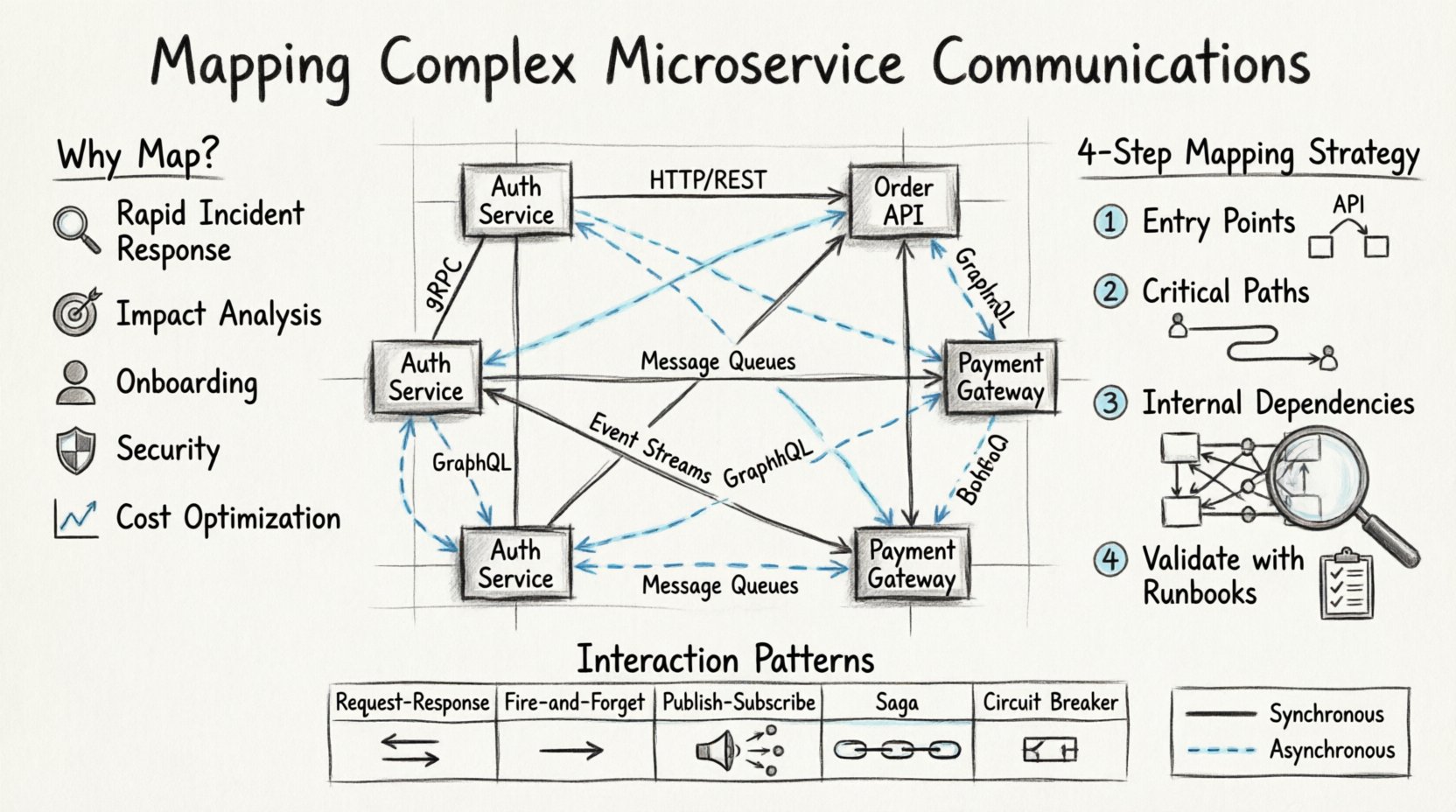
Почему видимость важна в распределенных системах 🧠
Когда система состоит из десятков или сотен сервисов, количество возможных путей взаимодействия растет экспоненциально. Один запрос от клиента может пройти через пять разных сервисов, запустить две фоновые задачи и обновить три базы данных, прежде чем вернуть ответ. Без визуального или документированного представления этого пути инженеры полагаются на фрагментарные знания.
Вот основные причины, по которым картирование коммуникаций является критически важным:
- Быстрое реагирование на инциденты: Когда наблюдается резкий рост задержек или возникают ошибки, знание точного потока данных позволяет инженерам быстро локализовать точку отказа.
- Анализ последствий: Перед развертыванием изменений в конкретном сервисе необходимо знать, какие другие сервисы зависят от его текущего API-договора.
- Эффективность наставничества: Новые члены команды могут понять архитектуру системы, не прибегая к поиску кода в каждом репозитории.
- Соответствие требованиям безопасности: Понимание потока данных критически важно для выявления мест передачи конфиденциальной информации и обеспечения соответствующего шифрования.
- Оптимизация затрат: Выявление избыточных вызовов или неэффективных передач данных помогает снизить расходы на инфраструктуру.
Однако создание карты — это не просто рисование прямоугольников и линий. Речь идет о фиксации логики, протоколов и ограничений, определяющих поток информации.
Определение границ коммуникации 🚧
Прежде чем рисовать первый диаграмму, необходимо определить, что считается событием коммуникации. В архитектурах микросервисов взаимодействия обычно делятся на две основные категории: синхронные и асинхронные. Различение между ними — первый шаг к точному картированию.
Синхронная коммуникация
Синхронные взаимодействия происходят, когда вызывающий ожидает немедленного ответа. Это традиционная модель запрос-ответ, используемая в большинстве веб-приложений.
- HTTP/REST: Наиболее распространенный протокол. Клиент отправляет запрос и блокируется до получения ответа от сервера.
- gRPC: Часто используется для внутреннего взаимодействия сервисов из-за высокой производительности и строгой типизации.
- GraphQL: Позволяет клиентам запрашивать конкретные структуры данных, изменяя способ, которым сервисы предоставляют свои конечные точки.
Картирование этих потоков требует документирования конечных точек, ожидаемых нагрузок и стратегий обработки ошибок. Если сервис А вызывает сервис Б, он ждет 5 секунд? Что происходит, если сервис Б недоступен? Эти детали критически важны для полной карты.
Асинхронная коммуникация
Асинхронные взаимодействия разъединяют отправителя и получателя. Отправитель инициирует сообщение и продолжает обработку, не дожидаясь прямого ответа.
- Очереди сообщений:Сервисы публикуют сообщения в очередь, а потребители получают их, когда готовы.
- Потоки событий:Сервисы генерируют события в журнал или поток, к которому другие сервисы подключаются для обработки.
- Фоновые задания:Задачи, запускаемые событием, но выполняемые позже.
Асинхронные потоки сложнее отображать, потому что связь является неявной. Время выполнения нет прямой линии между отправителем и получателем; они используют общий канал. Для документирования этих процессов необходимо перечислить темы, схемы сообщений и логику подписки.
Паттерны взаимодействия и их последствия 🔄
Понимание паттерна взаимодействия помогает определить надежность и сложность системы. Ниже приведено сравнение распространенных паттернов, используемых в распределенных архитектурах.
| Паттерн | Направление | Надежность | Сценарий использования |
|---|---|---|---|
| Запрос-ответ | Синхронный | Высокая (требует повторных попыток) | API для пользователей, немедленные потребности в данных |
| Отправить и забыть | Асинхронный | Средняя (зависит от очереди) | Журналирование, уведомления, аналитика |
| Публикация-подписка | Асинхронный | Высокая (с устойчивыми очередями) | Изменения состояния, междоменные события |
| Паттерн Саги | Гибридный | Высокая (компенсирующие транзакции) | Сложные многоэтапные бизнес-процессы |
| Прерыватель цепи | Защитный | Предотвращает цепную реакцию сбоев | Предотвращение перегрузки сервисов нижнего уровня |
При составлении карты вашей системы вы должны помечать каждый взаимодействие между сервисами используемым шаблоном. Например, сервис, вызывающий базу данных, работает синхронно. Сервис, отправляющий электронное письмо с подтверждением заказа, работает асинхронно. Сервис, координирующий процесс оформления заказа с использованием нескольких сервисов, может использовать шаблон «Сага».
Пошаговая стратегия составления карты 🛠️
Как перейти от хаотичного кода к четкой схеме? Попытка одновременно отобразить всё часто приводит к выгоранию и неполным данным. Поэтапный подход дает лучшие результаты.
1. Определите точки входа
Начните с края. Зафиксируйте API-шлюз или балансировщик нагрузки. Какие внешние запросы поступают в систему? Какие протоколы они используют? Это определяет границы вашей схемы.
- Перечислите все публичные конечные точки.
- Определите механизмы аутентификации.
- Создайте карту правил маршрутизации, направляющих трафик на внутренние сервисы.
2. Проделайте критические пути
Не пытайтесь отобразить каждую отдельную функцию. Сосредоточьтесь на критических бизнес-процессах. Для платформы электронной коммерции это будет процесс оформления заказа. Для социальной сети это может быть генерация ленты новостей или доставка уведомлений.
- Следуйте за одним пользовательским запросом от начала до конца.
- Запишите каждый сервис, с которым взаимодействовал запрос на протяжении всего пути.
- Запишите данные, передаваемые между каждым этапом.
3. Зафиксируйте внутренние зависимости
Как только критические пути будут отображены, обратитесь внутрь. Как сервисы общаются между собой вне основных пользовательских потоков? Это включает проверки работоспособности, получение конфигураций и пакетные задания обработки.
- Проверьте реестры сервисов на наличие известных узлов.
- Просмотрите файлы конфигурации на наличие имен очередей или подписок на темы.
- Проверьте манифесты оркестрации контейнеров на наличие прокси-сервисов-спутников.
4. Проверка с помощью инструкций по эксплуатации
Документация часто устаревает. Лучший способ проверки — использовать карту во время инцидента. Если вы полагаетесь на схему для устранения ошибки, а шаги не соответствуют реальности, схему нужно обновить. Рассматривайте схему как источник истины, который необходимо проверять.
Обработка асинхронных потоков и потоков событий 📬
Асинхронная коммуникация — это то, где часто терпят неудачу попытки составления карты. Поскольку отсутствует прямое взаимодействие, связь скрыта. Чтобы эффективно отобразить это, необходимо обратиться к уровню инфраструктуры.
Централизация знаний о событиях
События часто определяются в реестрах схем или хранилищах документации. Создание централизованного индекса всех событий позволяет увидеть, какие сервисы публикуют события, а какие подписываются на них.
- Схемы событий: Определяют структуру передаваемых данных. Если схема изменяется, потребитель должен знать об этом.
- Ответственность за тему: Кто несет ответственность за поддержку брокера сообщений? Кто несет ответственность за потребителей?
- Мониторинг бэклога:Высокая задержка в очереди указывает на узкое место в обработке, что следует отметить в статусе системы.
Визуализация потока
На диаграмме асинхронные потоки должны выглядеть иначе, чем синхронные. Используйте штриховые линии для обозначения очередей сообщений и сплошные линии для прямых вызовов. Подпишите штриховые линии именем события и темой.
Рассмотрим сценарий, при котором Service A публикуетOrderCreatedсобытие. Service B и Service C оба подписываются на него. Service B обрабатывает оплату, а Service C обновляет инвентарь. Без карты легко забыть, что Service C существует, или что он зависит от того же события, что и Service B.
Управление изменениями и эволюцией 🌱
Статическая карта — бесполезная карта. Сервисы эволюционируют, API ломаются, и меняется инфраструктура. Цель — создать процесс, при котором карта обновляется естественным образом по мере изменения кода.
Автоматическое обнаружение
Хотя ручная документация ценна, она подвержена отклонению. Там, где это возможно, используйте инструменты автоматического обнаружения для генерации базовых данных для ваших диаграмм. Системы трассировки могут фиксировать вызовы между сервисами и экспортировать их в виде графов зависимостей.
- Интегрируйте данные трассировки в процесс документирования.
- Настройте оповещения о новых зависимостях, которые появляются неожиданно.
- Используйте анализ кода для выявления операторов импорта, указывающих на потенциальные зависимости.
Контроль версий для диаграмм
Рассматривайте архитектурные диаграммы как код. Храните их в том же репозитории, что и код приложения. Требуйте, чтобы каждый запрос на слияние, изменяющий интерфейс сервиса, включал соответствующее обновление диаграммы.
- Используйте систему контроля версий для отслеживания изменений с течением времени.
- Проводите проверку изменений диаграмм в процессе код-ревью.
- Храните исторические версии, чтобы понять, как изменилась архитектура.
Распространённые ошибки при составлении карт 🚫
Даже при наличии надёжной стратегии команды часто попадают в ловушки, снижающие полезность карты.
Циклические зависимости
Когда Service A вызывает Service B, а Service B вызывает Service A, вы создаете цикл. Это делает систему уязвимой и трудной для отладки. На карте следует выделять такие циклы, чтобы их можно было рефакторить.
- Выявляйте циклы в графе зависимостей.
- Переписывайте код для разрыва цикла с помощью событий или общих интерфейсов.
- Документируйте причину цикла, если его нельзя немедленно устранить.
Скрытая связь
Сервисы могут делить базу данных или файловую систему без явных вызовов API. Это тесная связь, маскирующаяся под слабую связь. Её необходимо чётко документировать, так как она влияет на стратегии развертывания.
- Проверьте наличие общих точек монтирования хранилища.
- Проверьте строки подключения к базе данных для общих схем.
- Явно документируйте общие ресурсы в архитектуре.
Чрезмерная детализация диаграммы
Попытка отобразить каждый отдельный вызов функции приводит к диаграмме, которая слишком сложна для чтения. Сосредоточьтесь на высоком уровне потоков и критических путях. Подробности можно хранить в комментариях к коду или документации API.
- Используйте уровни абстракции. Высокий уровень для руководства, низкий уровень для инженеров.
- Связывайте подробную документацию API с узлами диаграммы высокого уровня.
- Удалите ненужную внутреннюю логику из диаграммы.
Человеческий фактор диаграмм 👥
Технология — это только половина проблемы. Вторая половина — способность команды понимать и использовать карту. Диаграмма, которую никто не читает, хуже, чем отсутствие диаграммы вообще.
Стандартизация нотации
Убедитесь, что каждый член команды понимает используемые символы. Если вы используете определенный цвет для асинхронных потоков, каждый должен знать, что этот цвет обозначает протокол. Согласованность снижает когнитивную нагрузку.
- Создайте легенду для ваших диаграмм.
- Договоритесь о правилах именования сервисов.
- Определите стандартные иконки для баз данных, очередей и внешних систем.
Доступность и распространение
Где хранится диаграмма? Если она скрыта в личном хранилище документов, к ней невозможно получить доступ. Храните её в централизованном, поисковом месте, доступном для всех инженеров.
- Размещайте диаграммы на внутренней вики или сайте документации.
- Убедитесь, что диаграммы корректно отображаются в просмотрщиках markdown.
- Ссылайтесь на диаграммы из файлов README сервисов.
Поощрение обновлений
Сделайте обновление карты частью определения «готово». Если разработчик меняет код, но забывает обновить карту, работа считается незавершённой. Такой культурный сдвиг гарантирует, что документация остаётся актуальной.
- Включите обновления диаграмм в чек-лист запросов на слияние.
- Хвалите членов команды, которые поддерживают документацию в актуальном состоянии.
- Регулярно проверяйте диаграммы по отношению к работающей системе.
Отладка с помощью карты 🐞
Последнее испытание коммуникационной карты — её полезность во время инцидента. Когда система работает медленно или сломана, карта становится инструментом диагностики.
- Отследите запрос:Используйте карту, чтобы определить, какой сервис в цепочке, вероятно, является узким местом.
- Проверьте статус работоспособности:Убедитесь, что отображённые зависимости работают и запущены.
- Анализировать журналы: Искать ошибки в службах, определенных картой.
- Проверить конфигурацию: Убедитесь, что конфигурация соответствует карте (например, имена очередей, URL-адреса конечных точек).
Если карта точна, это значительно сокращает среднее время устранения неисправностей (MTTR). Инженеры могут пропустить угадывание и сосредоточиться на конкретном узле, требующем внимания.
Поддержание ясности с течением времени ⏳
По мере масштабирования системы карта будет расти. Чтобы предотвратить её превращение в запутанную сеть, необходимо управлять её сложностью.
- Многоуровневые представления: Создавайте разные диаграммы для разных аудиторий. Общие для руководителей, детальные для инженеров.
- Ответственность за сервис: Назначьте ответственность за конкретные диаграммы определённым командам. Это гарантирует, что кто-то будет отвечать за их точность.
- Регулярные обзоры: Планируйте ежеквартальные обзоры архитектуры для удаления неиспользуемого кода и обновления потоков.
- Петли обратной связи: Позволяйте инженерам предлагать исправления диаграмм, когда они обнаруживают расхождения в рабочей среде.
Рассматривая карту как живой артефакт, вы гарантируете, что она останется ценным активом, а не исторической реликвией. Сложность микросервисов неизбежна, но хаос вокруг неё — нет. При дисциплинированном подходе к созданию карты вы сможете уверенно и ясно ориентироваться в распределённой среде.