











現代の分散システムの世界において、複雑さはバグではなく、スケーリングの特徴である。組織が成長するにつれて、モノリシックなアーキテクチャはマイクロサービスに分裂する。この移行は柔軟性と耐障害性をもたらすが、同時に大きな課題をもたらす。すなわち、これらの独立したユニットがどのように相互に通信しているかを理解することである。通信フローの明確なマップがなければ、チームは依存関係の迷路をさまようことになり、デバッグサイクルが遅くなり、予期しない副作用が生じ、脆弱なデプロイが発生する。
本ガイドは、複雑なマイクロサービス間通信をマッピングする実用的なアプローチを探求する。抽象的な理論を越えて、サービス間の相互作用のメカニズム、これらの関係を文書化する方法、システムの進化に伴って明確さを維持する戦略を検討する。目標は静的な文書を作成することではなく、分散アーキテクチャについて動的な理解を確立することである。
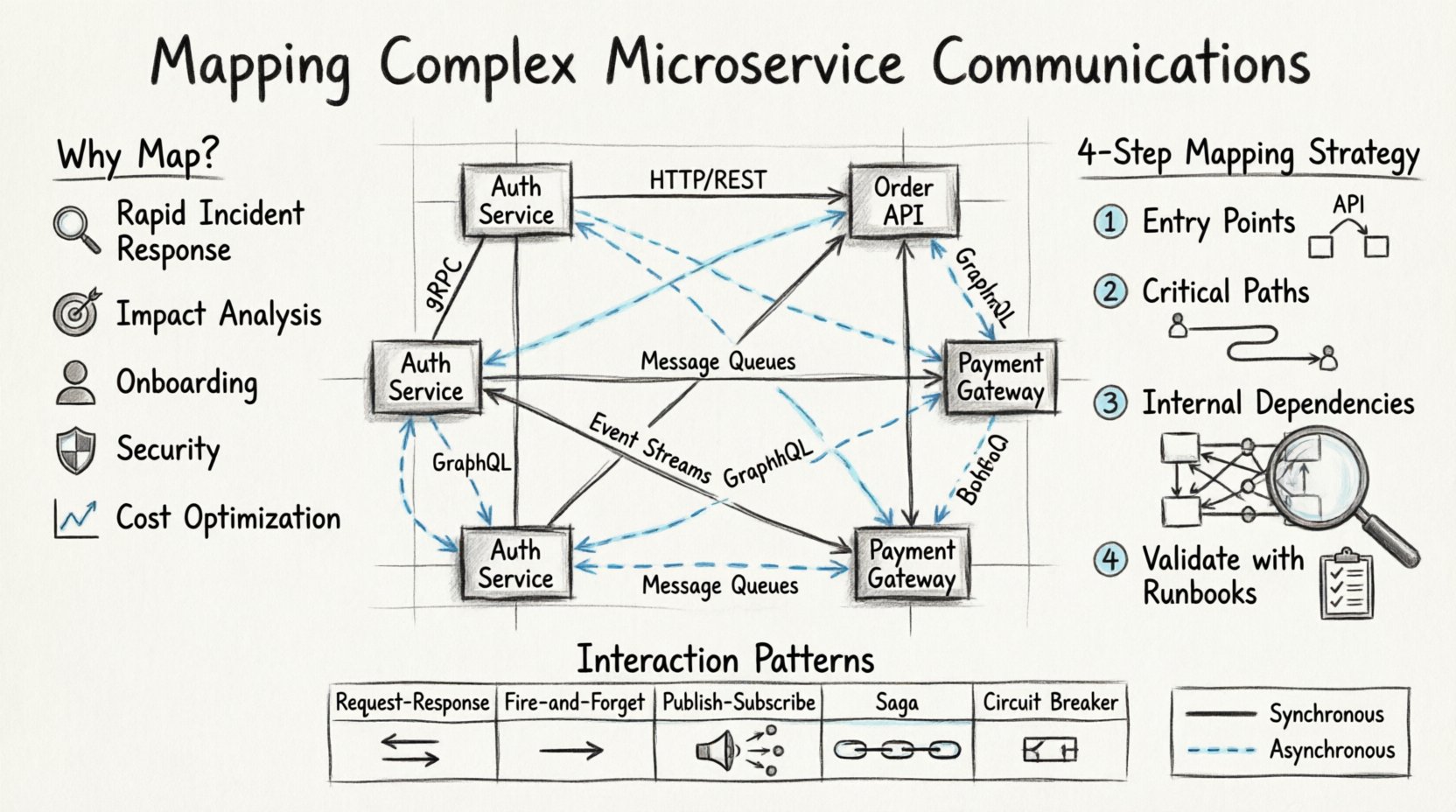
分散システムにおいて可視性が重要な理由 🧠
システムが数十、あるいは数百のサービスから構成される場合、潜在的な相互作用経路の数は指数関数的に増加する。クライアントからの単一のリクエストは、応答が返されるまでに5つの異なるサービスを経由し、2つのバックグラウンドジョブをトリガーし、3つのデータベースを更新する可能性がある。この経路を視覚的または文書化された形で把握できない場合、エンジニアは断片的な知識に頼ることになる。
通信をマッピングすることが不可欠な理由は以下の通りである:
- 迅速なインシデント対応:レイテンシが急上昇したりエラーが発生した際、データの正確な流れを把握することで、エンジニアは障害発生点を迅速に特定できる。
- 影響分析:特定のサービスに変更をデプロイする前に、その現在のAPI契約に依存している他のサービスを把握しておく必要がある。
- 新入社員の導入効率向上:新しくチームに加わるメンバーは、すべてのリポジトリを介してコードを追跡する必要なく、システムアーキテクチャを理解できる。
- セキュリティコンプライアンス:データフローを理解することは、機密情報がどこで送信されているかを特定し、適切に暗号化されていることを保証するために不可欠である。
- コスト最適化:重複する呼び出しや非効率なデータ転送を特定することで、インフラストラクチャのコスト削減が可能になる。
しかし、マップを作成することは、箱と線を描くことだけではない。情報の流れを規定する論理、プロトコル、制約を捉えることが重要である。
通信の範囲を定義する 🚧
1枚の図を描く前に、通信イベントとは何かを明確に定義する必要がある。マイクロサービスアーキテクチャでは、相互作用は一般的に2つの主要なカテゴリに分類される:同期的と非同期的。これらを区別することが、正確なマッピングの第一歩である。
同期通信
同期的な相互作用は、呼び出し元が即時の応答を待つときに発生する。これは、ほとんどのウェブアプリケーションに見られる伝統的なリクエスト・レスポンスモデルである。
- HTTP/REST:最も一般的なプロトコル。クライアントはリクエストを送信し、サーバーからの応答を受けるまでブロックする。
- gRPC:パフォーマンスと強力な型付けのため、内部のサービス間通信に頻繁に使用される。
- GraphQL:クライアントが特定のデータ構造を要求できるようにし、サービスがエンドポイントをどのように公開するかを変える。
これらのフローをマッピングするには、エンドポイント、期待されるペイロード、エラー処理戦略を文書化する必要がある。Service AがService Bを呼び出す場合、5秒待つのか? Service Bが利用不可の場合どうなるのか? これらの詳細は、完全なマップにとって不可欠である。
非同期通信
非同期的な相互作用は、送信者と受信者を分離する。送信者はメッセージを開始し、直接的な返信を待たずに処理を継続する。
- メッセージキュー: サービスはメッセージをキューに投稿し、コンシューマーは準備ができたらそれを取り込みます。
- イベントストリーム: サービスはログやストリームにイベントを発行し、他のサービスがそれらを処理するために購読します。
- バックグラウンドジョブ: イベントによってトリガーされるが、後に実行されるタスク。
非同期フローは、接続が暗黙的であるため、マッピングが難しいです。実行時において送信者と受信者の間に直接的な接続は存在せず、共通のチャネルを共有しています。これらのドキュメント化には、トピック、メッセージスキーマ、およびサブスクリプションロジックをリストアップする必要があります。
相互作用のパターンとその影響 🔄
相互作用のパターンを理解することで、システムの信頼性と複雑さを判断できます。以下は、分散アーキテクチャで使用される一般的なパターンの比較です。
| パターン | 方向 | 信頼性 | 使用例 |
|---|---|---|---|
| リクエスト-レスポンス | 同期的 | 高(リトライが必要) | ユーザー向けAPI、即時データの必要性 |
| 発射して忘却 | 非同期 | 中程度(キューに依存) | ログ記録、通知、分析 |
| 発行-購読 | 非同期 | 高(耐久性キューを使用した場合) | 状態変更、クロスドメインイベント |
| サーガパターン | ハイブリッド | 高(補償トランザクション) | 複雑な複数ステップのビジネスプロセス |
| サーキットブレーカー | 保護的 | 連鎖的な障害を防止する | 下流サービスの過負荷を防ぐ |
システムをマッピングする際には、各サービス間のやり取りに使用しているパターンを注釈する必要があります。たとえば、データベースを呼び出すサービスは同期的です。注文確認メールを送信するサービスは非同期です。複数のサービスを使用してチェックアウトフローをオーケストレーションするサービスは、サーガパターンを使用する可能性があります。
ステップバイステップのマッピング戦略 🛠️
混乱したコードベースから明確な図へと移行するにはどうすればよいでしょうか?一度にすべてをマッピングしようとすると、燃え尽き症候群や不完全なデータに陥りがちです。段階的なアプローチの方が、より良い結果をもたらします。
1. エントリポイントを特定する
エッジから始めましょう。APIゲートウェイまたはロードバランサーを文書化します。外部からのどのリクエストがシステムに入力されるのでしょうか?どのようなプロトコルを使用しているのでしょうか?これにより、図の境界が定義されます。
- すべてのパブリックエンドポイントをリストアップする。
- 認証メカニズムを特定する。
- 内部サービスにトラフィックを誘導するルーティングルールをマッピングする。
2. クリティカルパスを追跡する
すべての関数をマッピングしようとしないでください。重要なビジネスフローに注目してください。ECプラットフォームの場合、それはチェックアウトプロセスです。ソーシャルネットワークの場合、フィード生成や通知配信かもしれません。
- 1つのユーザー要求を開始から終了まで追跡する。
- 経路上で触れたすべてのサービスをメモする。
- 各ホップ間で渡されるデータを記録する。
3. 内部依存関係を文書化する
クリティカルパスをマッピングした後は、内部に目を向けるべきです。メインのユーザーフロー以外で、サービスどうしがどのようにやり取りしているのでしょうか?これにはヘルスチェック、設定の取得、バッチ処理ジョブが含まれます。
- 既知のピアを確認するために、サービスレジストリをチェックする。
- キュー名やトピック購読情報を確認するために、設定ファイルを確認する。
- サイドカー・プロキシを確認するために、コンテナオーケストレーションのマニフェストを検査する。
4. ランブックを使って検証する
ドキュメントはしばしば陳腐化します。最も良い検証方法は、インシデント発生時にマップを使用することです。バグを修正するために図に頼り、その手順が現実と一致しない場合、マップは更新が必要です。図を検証可能な真実の源として扱いましょう。
非同期フローおよびイベントストリームの取り扱い 📬
非同期通信は、多くのマッピング作業が失敗するポイントです。直接的なハンドシェイクがないため、結合が隠されています。これを効果的にマッピングするには、インフラストラクチャ層に注目する必要があります。
イベント知識の統合
イベントはしばしばスキーマレジストリやドキュメントリポジトリに定義されています。すべてのイベントの中央インデックスを作成することで、どのサービスが発行し、どのサービスが購読しているかを把握できます。
- イベントスキーマ:送信されるデータの構造を定義する。スキーマが変更された場合、コンシューマーはそれを把握しなければならない。
- トピック所有権: メッセージブローカーの保守は誰が責任を負っていますか?コンシューマーの保守は誰が責任を負っていますか?
- バックログ監視: キュー内の高いラグは処理のボトルネックを示しており、システムステータスに記録すべきです。
フローの可視化
図において非同期フローは同期フローと異なる見た目になるべきです。メッセージキューには破線を使用し、直接呼び出しには実線を使用してください。破線にはイベント名とトピックをラベルとして記載してください。
Service Aが発行するという状況を考えてみましょう。OrderCreated イベントがあります。Service BとService Cの両方がこのイベントに購読しています。Service Bは支払い処理を行い、Service Cは在庫を更新します。マップがなければ、Service Cが存在することや、Service Bと同じイベントに依存していることを忘れてしまうのは容易です。
変更と進化の管理 🌱
静的なマップは無意味なマップです。サービスは進化し、APIは壊れ、インフラ構成も変化します。コードの変更に伴ってマップが自然に更新されるプロセスを作ることが目標です。
自動発見
手動でのドキュメント作成は価値がありますが、ずれが生じやすいです。可能な限り、自動発見ツールを使用して図の基盤データを生成してください。トレーシングシステムはサービス間の呼び出しを記録し、依存関係グラフとしてエクスポートできます。
- トレーシングデータをドキュメント作成プロセスに統合する。
- 予期しない新しい依存関係が出現した場合にアラートを設定する。
- コード解析を使用して、潜在的な依存関係を示すインポート文を特定する。
図のバージョン管理
アーキテクチャ図をコードとして扱う。アプリケーションコードと同じリポジトリに保存する。サービスインターフェースを変更する任意のプルリクエストには、対応する図の更新を必須とする。
- バージョン管理システムを使用して、時間の経過に伴う変更を追跡する。
- コードレビューのプロセスで図の変更をレビューする。
- アーキテクチャの変化を理解するために、履歴バージョンを保持する。
マッピングにおける一般的な落とし穴 🚫
しっかりとした戦略があっても、チームはマップの有用性を低下させる罠に陥ることがよくあります。
循環依存
Service AがService Bを呼び出し、Service BがService Aを呼び出すと、ループが発生します。これによりシステムは脆弱になり、デバッグが難しくなります。マッピングはこれらのループを強調し、リファクタリングできるようにすべきです。
- 依存関係グラフ内のサイクルを特定する。
- イベントや共有インターフェースを使用して、サイクルを解除するためのリファクタリングを行う。
- すぐに解除できない場合、サイクルの理由をドキュメント化する。
隠れた結合
サービスが明示的なAPI呼び出しをせずにデータベースやファイルシステムを共有することがあります。これは緩い結合を装った強い結合です。デプロイ戦略に影響するため、明確にドキュメント化する必要があります。
- 共有ストレージのマウントを確認する。
- 共有スキーマのデータベース接続文字列を確認する。
- 共有リソースをアーキテクチャ内で明示的に文書化する。
図の過剰設計
すべての関数呼び出しをマッピングしようとすると、読みにくすぎる図になってしまう。高レベルのフローと重要なパスに注目する。詳細はコードコメントやAPIドキュメントに保存する。
- 抽象化レベルを活用する。管理向けには高レベル、エンジニア向けには低レベルとする。
- 詳細なAPIドキュメントを高レベルの図のノードにリンクする。
- 不要な内部論理を図から削除する。
図の人的側面 👥
技術的な課題は半分に過ぎない。もう半分はチームが図を理解し、使いこなす能力にある。誰も読まない図は、まったく図がないよりも悪い。
表記の標準化
チーム全員が使用する記号を理解していることを確認する。非同期フローに特定の色を使う場合、全員がその色がどのプロトコルを表すかを把握している必要がある。一貫性があることで認知負荷が軽減される。
- 図に凡例を作成する。
- サービスの命名規則に合意する。
- データベース、キュー、外部システムの標準アイコンを定義する。
アクセス性と配布
図はどこに保存されているか?個人のドキュメントドライブに埋もれていたらアクセスできない。すべてのエンジニアがアクセスできる中央の検索可能な場所に保存する。
- 図を社内Wikiやドキュメントサイトにホストする。
- 図がMarkdownビューアーで正しくレンダリングされることを確認する。
- サービスのREADMEファイルから図にリンクする。
更新の促進
図の更新を「完了の定義」の一部とする。開発者がコードを変更したが図を更新し忘れた場合、作業は未完了とみなす。この文化的な変化により、ドキュメントが常に最新の状態を保たれる。
- プルリクエストチェックリストに図の更新を含める。
- ドキュメントを最新に保つチームメンバーを称賛する。
- 図を実行中のシステムと定期的に照合する。
図を活用したデバッグ 🐞
コミュニケーションマップの最終的な試練は、インシデント発生時の有用性である。システムが遅延したり停止したりしたとき、図は診断ツールとなる。
- リクエストの流れを追跡する:図を使って、連鎖内のどのサービスがボトルネックになりやすいかを特定する。
- 健全性状態の確認:マッピングされた依存関係が正常に稼働しているかを確認する。
- ログを分析する:マップで特定されたサービスのエラーを確認する。
- 設定の検証:設定がマップと一致していることを確認する(例:キュー名、エンドポイントURL)。
マップが正確であれば、平均障害対応時間(MTTR)を大幅に短縮できる。エンジニアは推測を省き、注意を要する特定のノードに集中できる。
時間の経過に伴う明確さの維持 ⏳
システムが拡大するにつれて、マップも拡大する。複雑な網目状になるのを防ぐため、複雑さを管理しなければならない。
- レイヤードビュー:異なる対象者向けに異なる図を描く。経営陣向けには概要、エンジニア向けには詳細。
- サービスの所有権:特定の図の所有権を特定のチームに割り当てる。これにより、正確性を保つ責任者が確保される。
- 定期的なレビュー:アーキテクチャを四半期ごとにレビューし、無用なコードを削除し、フローを更新する。
- フィードバックループ:エンジニアが本番環境で不整合を発見した際に、図の修正を提案できるようにする。
マップを生きている資産として扱うことで、歴史的遺物ではなく価値ある資産を維持できる。マイクロサービスの複雑さは避けられないが、その周囲の混乱は選択肢である。マッピングに対して厳格なアプローチを取ることで、分散した環境を自信と明確さを持って進むことができる。