











W nowoczesnej architekturze oprogramowania interfejsy programowania aplikacji (API) pełnią rolę tkanki łączącej usługi. Gdy te połączenia zawiodą, cały system może się zatrzymać. Identyfikacja źródła spowolnienia wydajności wymaga więcej niż tylko monitorowania metryk; wymaga strukturalnego zrozumienia, jak dane przepływają przez system. Diagramy komunikacji oferują dokładny sposób wizualizacji tego przepływu, pozwalając inżynierom dokładnie wskazać, gdzie występują przepływy.
Ten przewodnik bada mechanizmy diagnozowania punktów zatkania interfejsów API z perspektywy diagramów komunikacji. Przeanalizujemy wizualne przedstawienie interakcji obiektów, przeanalizujemy wzorce wiadomości wskazujące na obciążenie i przedstawimy systematyczny sposób rozwiązywania problemów z opóźnieniem i przepustowością bez użycia narzędzi własnych.
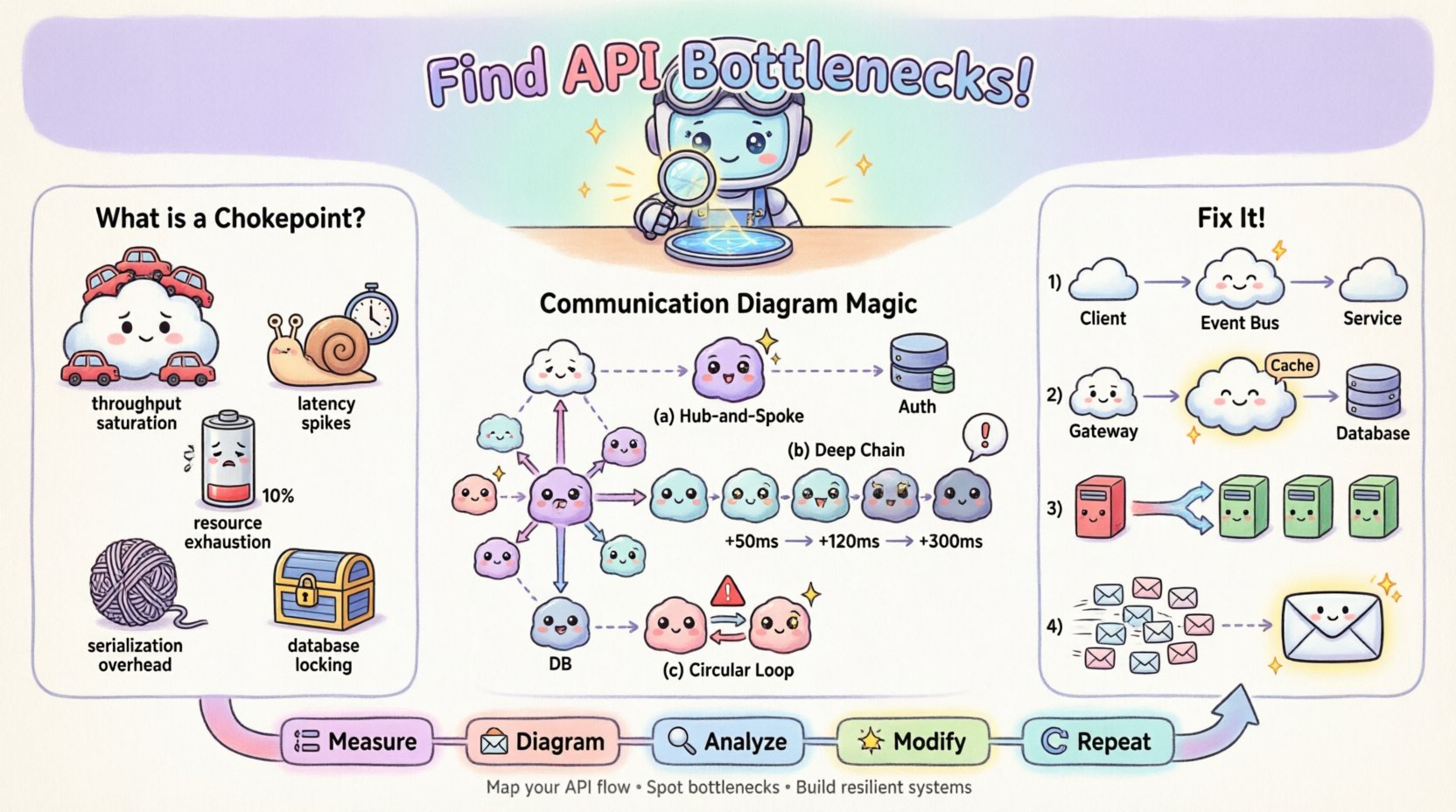
🚦 Zrozumienie punktów zatkania interfejsów API
Punkt zatkania interfejsu API to określony punkt w cyklu żądanie-odpowiedź, w którym przetwarzanie spowalnia się lub kończy niepowodzeniem, powodując zator. W przeciwieństwie do ogólnego opóźnienia sieciowego, które wpływa na całą transmisję, punkt zatkania często jest lokalizowany w konkretnym serwisie, zapytaniu do bazy danych lub mechanizmie synchronizacji. Rozpoznanie rodzaju punktu zatkania to pierwszy krok w skutecznej naprawie.
Typowe rodzaje punktów zatkania obejmują:
- Nasycenie przepustowości: Serwis odbierający nie może wystarczająco szybko przetwarzać przychodzących żądań, co prowadzi do gromadzenia się kolejek.
- Piky opóźnień: Określone wywołanie trwa znacznie dłużej niż średnio, opóźniając procesy w dalszej części systemu.
- Wyczerpanie zasobów: Osiągnięto limity CPU, pamięci lub puli połączeń, co powoduje timeouty lub błędy odrzucenia.
- Nadmiar kosztów serializacji: Koszty przekształcania danych (np. analiza JSON) stają się nadmiernie duże z powodu rozmiaru danych.
- Blokowanie bazy danych: Współbieżne zapisy blokują odczyty lub inne zapisy, zatrzymując przepływ transakcji.
Gdy te problemy występują, często manifestują się jako zjawisko kaskadowych awarii. Opóźnienie w jednym mikroserwisie może wywołać timeouty w serwisie wywołującym, które następnie rozprzestrzenia się w górę łańcucha. Wizualizacja tego łańcucha jest kluczowa.
📐 Rola diagramów komunikacji w debugowaniu
Diagramy komunikacji, rodzaj diagramu interakcji UML (Unified Modeling Language), skupiają się na strukturalnej organizacji obiektów oraz na wiadomościach wymienianych między nimi. W przeciwieństwie do diagramów sekwencji, które podkreślają kolejność chronologiczną wiadomości, diagramy komunikacji podkreślają relacje i połączenia między obiektami. Ta strukturalna orientacja czyni je szczególnie skutecznymi w identyfikowaniu przepięć architektonicznych.
Dlaczego używać tej konkretnej rodziny diagramów do rozwiązywania problemów?
- Skupienie się na strukturze: Wykazuje, które obiekty są głównymi węzłami. Jeden obiekt odbierający wiadomości od dziesięciu innych to doskonały kandydat na punkt zatkania.
- Liczenie wiadomości: Możesz wizualnie policzyć liczbę przesłanych wiadomości w jednej transakcji. Duże rozgałęzienie wskazuje na potencjalne problemy z przetwarzaniem równoległym.
- Analiza ścieżek: Wyróżnia najdłuższą ścieżkę wykonania. Długie łańcuchy synchronicznych wywołań są podatne na akumulację opóźnień.
- Jasność kontekstu: Pokazuje kontekst, w którym istnieją obiekty, pomagając rozpoznać, czy serwis jest przeciążony z powodu jego roli, a nie z powodu kodu.
Przyporządkowując interakcje interfejsów API do diagramu komunikacji, przekształcasz abstrakcyjne logi w rzeczywistą mapę. Ta mapa pozwala śledzić dokładną trasę, jaką przebywa żądanie, oraz mierzyć wysiłek wymagany na każdym węźle.
🛠️ Budowanie diagramu diagnostycznego
Aby użyć diagramu komunikacji do rozwiązywania problemów, najpierw należy stworzyć dokładne odwzorowanie bieżącego stanu systemu. Ten proces wymaga zbierania danych z dzienników, narzędzi śledzenia i dokumentacji architektonicznej. Celem jest stworzenie modelu odzwierciedlającego rzeczywistość, a nie idealizowanego projektu.
Krok 1: Zidentyfikuj aktorów i obiekty
Zacznij od zdefiniowania zewnętrznych klientów i wewnętrznych usług uczestniczących w problematycznej transakcji. W kontekście interfejsu API są to często:
- Klient: Aplikacja mobilna, przeglądarka internetowa lub usługa trzeciej strony inicjująca żądanie.
- Brama:Punkt wejścia obsługujący uwierzytelnianie, ograniczanie szybkości i routowanie.
- Orkiestrator:Usługa koordynująca przepływ logiki biznesowej.
- Zależności:Bazy danych, zewnętrzne interfejsy API, warstwy buforowania i zadania działające w tle.
Krok 2: Zmapuj przepływy komunikatów
Narysuj połączenia między tymi obiektami. Każdy odcinek reprezentuje komunikat. Użyj strzałek, aby wskazać kierunek przepływu danych. Oznacz każdą strzałkę nazwą metody lub działaniem wykonywanym (np.GET /orders, processPayment).
W celu rozwiązywania problemów, kluczowe jest oznaczenie diagramu danymi wydajnościowymi. Jeśli masz dostęp do metryk czasowych, dodaj je do etykiet komunikatów. Na przykład:
- Brama ➔ Orkiestrator: 50ms
- Orkiestrator ➔ Baza danych: 450ms (Ostrzeżenie)
- Baza danych ➔ Orkiestrator: 450ms
Krok 3: Zdefiniuj linie życia interakcji
Choć diagramy komunikacji nie zawsze wyraźnie pokazują pionowe linie życia, jak to robią diagramy sekwencji, musisz w myślach śledzić czas zaangażowania każdego obiektu. Obiekt, który długo pozostaje aktywny oczekując odpowiedzi, niepotrzebnie utrzymuje zasoby.
🔎 Identyfikowanie węzłów zatyczki na diagramie
Gdy diagram zostanie wypełniony danymi, możesz rozpocząć analizę. Ułożenie wizualne często ujawnia problemy, które ukrywają surowe dzienniki. Szukaj określonych wzorców wskazujących na węzeł zatyczki.
Wzorzec 1: Gwiazda z centralnym węzłem
Jeśli widzisz pojedynczy obiekt połączony z wieloma innymi w układzie gwiazdy, ten centralny obiekt prawdopodobnie stanowi węzeł zatyczki. Każde żądanie musi przez niego przejść. Jeśli ten obiekt jest synchroniczny, staje się punktem przetwarzania sekwencyjnego.
| Wskaźnik wizualny | Skutki | Typowa przyczyna |
|---|---|---|
| Jeden obiekt z 10+ przychodzącymi strzałkami | Wysokie obciążenie współbieżności | Usługa agregacji |
| Wiele długich poziomych strzałek zbiegających się | Akumulacja czasu oczekiwania | Synchroniczne rozgałęzienie |
| Obiekt oznaczony wysokim procentem zużycia CPU | Nasycenie przetwarzania | Złożona logika |
Wzorzec 2: Głębokie łańcuchy wywołań
Śledź najdłuższą ścieżkę od punktu wejścia do ostatecznego pobrania danych. Jeśli ścieżka obejmuje pięć lub więcej skoków, opóźnienie się zwiększy. Każdy skok dodaje narzut sieciowy i czas przetwarzania.
- Skutki: Całkowite opóźnienie = Suma opóźnień wszystkich skoków + narzut sieciowy.
- Rozwiązanie: Zmniejsz głębokość łańcucha wywołań poprzez współlokalizację danych lub użycie jednego punktu końcowego agregacji.
Wzorzec 3: Zależności cykliczne
Choć rzadsze w dobrze zbudowanych systemach, wiadomości cykliczne (A wywołuje B, B wywołuje A) mogą powodować zakleszczenie lub pętle nieskończone. W kontekście wydajności wskazują na nieefektywne zarządzanie stanem.
🛠️ Strategie naprawcze oparte na analizie wizualnej
Po znalezieniu węzła zatkania na schemacie można zastosować konkretne zmiany architektoniczne. Schemat pełni rolę projektu tych zmian.
1. Odłączenie wywołań synchronicznych
Jeśli schemat pokazuje długie łańcuchy synchronicznych wywołań, przekształć końcówkę łańcucha na zdarzenie asynchroniczne. Zamiast czekać na odpowiedź, orchestrator może wygenerować zdarzenie i od razu wrócić.
- Przed: Użytkownik ➔ API ➔ Usługa A ➔ Usługa B ➔ Baza danych (Czekaj)
- Po: Użytkownik ➔ API ➔ Usługa A ➔ Magistrala zdarzeń ➔ Usługa B (Wyślij i zapomnij)
2. Buforowanie na krawędzi
Jeśli schemat pokazuje powtarzające się żądania do tego samego obiektu dla tych samych danych, wprowadź warstwę buforowania. Umieść ten obiekt pomiędzy wywołującym a ciężkim zasobem.
- Zmiana schematu: Wstaw obiekt „Bufor” pomiędzy Bramę a Bazę danych.
- Aktualizacja etykiety: Zaktualizuj etykietę komunikatu, aby pokazywała „Pomyłka w pamięci podręcznej: 1ms” w porównaniu do „Niepowodzenie w pamięci podręcznej: 200ms”.
3. Równoważenie obciążenia i rozmieszczanie danych
Jeśli pojedynczy obiekt ma zbyt wiele połączeń (model Hub-and-Spoke), rozdziel obciążenie. Może to obejmować rozmieszczanie danych lub wprowadzenie balansownika obciążenia, który będzie przekierowywał ruch między wieloma wystąpieniami tej usługi.
4. Łączenie żądań
Jeśli diagram pokazuje wiele małych komunikatów wysyłanych do tego samego obiektu w szybkim ciągu, połącz je w jedną dużą żądanie. Zmniejsza to narzut związany z ustanawianiem połączeń i przełączaniem kontekstów.
📊 Analiza przepustowości w porównaniu do opóźnienia
Diagramy komunikacji mogą również pomóc rozróżnić problemy z przepustowością od problemów z opóźnieniem. Ta różnica jest kluczowa przy wyborze odpowiedniego rozwiązania.
- Wysokie opóźnienie, niska przepustowość: System jest wolny, ale obsługuje niewiele żądań. Zazwyczaj wskazuje to na jedną ciężką operację (np. generowanie skomplikowanego raportu).
- Niskie opóźnienie, niska przepustowość: System jest szybki, ale odrzuca wiele żądań. Wskazuje to na ograniczenia zasobów (np. wyczerpanie puli połączeń).
- Wysokie opóźnienie, wysoka przepustowość: System jest wolny i obsługuje wiele żądań. Jest to klasyczny scenariusz zatyczki, gdy pojemność jest przekroczona.
Poprzez oznaczenie diagramu tymi metrykami możesz wizualizować krzywą pojemności. Oznacz scenariusz „Duże obciążenie” na diagramie, aby zobaczyć, który węzeł pęka najpierw.
⚠️ Powszechne pułapki przy tworzeniu diagramów do debugowania
Nawet z najlepszymi intencjami tworzenie diagramu do rozwiązywania problemów może prowadzić do zamieszania, jeśli nie uniknie się pewnych pułapek.
- Zbyt duża abstrakcja: Nie grupuj zbyt wielu usług w jednym polu. Jeśli ukrywasz wewnętrzną złożoność usługi, nie możesz zobaczyć, gdzie znajduje się wewnętrzna zatyczka. Zachowaj usługi atomowe.
- Ignorowanie przepływów asynchronicznych: Jeśli diagram pokazuje tylko synchroniczne żądania, nie odzwierciedli prawdziwego obciążenia. Uwzględnij zadania w tle i nasłuchy zdarzeń w diagramie.
- Statyczny vs. dynamiczny: Diagram statyczny pokazuje projekt; diagram dynamiczny pokazuje działanie w czasie rzeczywistym. Podczas rozwiązywania problemów upewnij się, że używasz danych czasu działania (rzeczywistych ścieżek przebytych).
- Brakujące ścieżki błędów: Większość diagramów pokazuje ścieżkę sukcesu. Zatyczka często występuje podczas obsługi błędów (np. ponowne próby, przejście na alternatywę). Uwzględnij pętle ponownych prób w diagramie.
🔄 Iteracyjne doskonalenie diagramu
Architektura nie jest statyczna. W miarę stosowania poprawek diagram musi się rozwijać. Po wdrożeniu warstwy pamięci podręcznej diagram się zmienia. Komunikat od Bramy do Bazy danych jest zastępowany komunikatem do Pamięci podręcznej.
Ten proces iteracyjny tworzy pętlę zwrotną:
- Mierz: Zbierz aktualne metryki wydajności.
- Diagram: Zmapuj przepływ za pomocą metryk.
- Analizuj: Zidentyfikuj węzeł zatyczki.
- Modyfikuj: Zastosuj zmianę architektoniczną.
- Powtórz: Ponownie zmierz i zaktualizuj schemat.
Ten cykl zapewnia, że wysiłki optymalizacyjne są oparte na danych, a nie na zgadywaniu.
📈 Integracja z systemami monitoringu
Choć diagramy komunikacji są narzędziami wizualnymi, muszą być oparte na danych z systemów monitoringu. Powinieneś skojarzyć węzły diagramu z konkretnymi strumieniami dzienników lub identyfikatorami telemetrii.
- Identyfikatory śledzenia: Upewnij się, że każde wiadomość na diagramie odpowiada unikalnemu identyfikatorowi śledzenia w systemie dzienników.
- Mapy ciepła: Jeśli narzędzie monitoringu to umożliwia, wizualizuj częstotliwość wywołań jako mapę ciepła na diagramie. Cieplejsze kolory wskazują na wyższy obciążenie ruchem.
- Powiadomienia: Ustaw powiadomienia dla konkretnych węzłów uznanych za węzły zatyczki. Jeśli węzeł „Baza danych” zwiększy się, wywołaj powiadomienie.
🧠 Studium przypadku: Łańcuch przetwarzania zamówień
Rozważ sytuację, w której proces zakupowy w e-commerce jest powolny. Początkowe żądanie pokazuje opóźnienie 5 sekund.
Analiza początkowego diagramu:
- Klient ➔ Brama API (10 ms)
- Brama ➔ Usługa Zamówień (50 ms)
- Usługa Zamówień ➔ Usługa Inwentarza (200 ms)
- Usługa Zamówień ➔ Usługa Płatności (4000 ms)
- Usługa Zamówień ➔ Usługa Powiadomień (50 ms)
Obserwacja:
Diagram pokazuje, że Usługa Płatności jest wyjątkiem. Zużywa 80% całkowitego czasu. Usługa Zamówień oczekuje synchronicznie na zakończenie Usługi Płatności przed kontynuacją.
Wprowadzenie zmiany:
1. Przenieś płatność do przepływu asynchronicznego. Usługa Zamówień wysyła żądanie i oznacza zamówienie jako „W trakcie przetwarzania”. 2. Tło pracuje nad potwierdzeniem płatności. 3. Zaktualizuj diagram, aby pokazywał obiekt „Pracownik Płatności” zamiast bezpośredniego wywołania.
Wynik:
Użytkownik natychmiast widzi status „W trakcie przetwarzania”. Całkowita opóźnienie dla doświadczenia użytkownika spada z 5 sekund do 50 milisekund. Backend przetwarza ciężką pracę asynchronicznie. Diagram teraz odzwierciedla bardziej odporną architekturę.
🎯 Najlepsze praktyki utrzymania
Aby te schematy pozostawały przydatne w czasie, przestrzegaj poniższych praktyk utrzymania.
- Kontrola wersji: Przechowuj pliki schematów w tym samym repozytorium co kod źródłowy. Gdy zmienia się kod, schemat również powinien się zmienić.
- Cykle przeglądu: Włącz przeglądy schematów do zapisów decyzji architektonicznych. Upewnij się, że nowe usługi są dodawane do mapy przed wdrożeniem.
- Standardyzacja: Używaj spójnej notacji dla typów wiadomości (np. żądanie, odpowiedź, zdarzenie), aby schematy były czytelne dla wszystkich członków zespołu.
- Dokumentacja: Uzupełnij schemat notatkami wyjaśniającymi *dlaczego* istnieje określona droga. Zapobiega to temu, by przyszli inżynierowie usunęli konieczny kod.
🔗 Wnioski
Rozwiązywanie problemów z wydajnością interfejsu API to połączenie analizy danych i wizualizacji strukturalnej. Schematy komunikacji zapewniają niezbędną strukturę do zrozumienia złożonych interakcji. Przez mapowanie przepływów wiadomości, dodawanie informacji o czasie i analizę wzorców połączeń możesz precyzyjnie identyfikować węzły zatkania. Ten podejście wykracza poza zgadywanie i pozwala na skierowane ulepszenia architektoniczne, które zwiększają stabilność i szybkość systemu.
Pamiętaj, że schemat to dokument żywy. Musi ewoluować wraz z rozwojem systemu. Regularne powtarzanie przeglądu mapy zapewnia, że nowe funkcje nie wprowadzają nowych węzłów zatkania. Mając jasny obraz przepływu, możesz utrzymać zdrowy, wysokiej wydajności system.