











In der modernen Softwarearchitektur dienen Anwendungsprogrammierschnittstellen (APIs) als die verbindende Struktur zwischen Diensten. Wenn diese Verbindungen ausfallen, kann das gesamte System zum Stillstand kommen. Die Identifizierung der Ursache für Leistungsabfälle erfordert mehr als nur die Überwachung von Metriken; es bedarf eines strukturellen Verständnisses dafür, wie Daten durch das System fließen. Kommunikationsdiagramme bieten eine präzise Methode zur Visualisierung dieses Flusses und ermöglichen es Ingenieuren, genau dort Engpässe zu identifizieren, wo sie auftreten.
Diese Anleitung untersucht die Mechanismen zur Diagnose von API-Engpässen aus der Perspektive von Kommunikationsdiagrammen. Wir werden die visuelle Darstellung von Objektinteraktionen untersuchen, Muster von Nachrichten analysieren, die auf Belastung hinweisen, und einen systematischen Ansatz zur Behebung von Latenz- und Durchsatzproblemen vorstellen, ohne auf proprietäre Werkzeuge angewiesen zu sein.
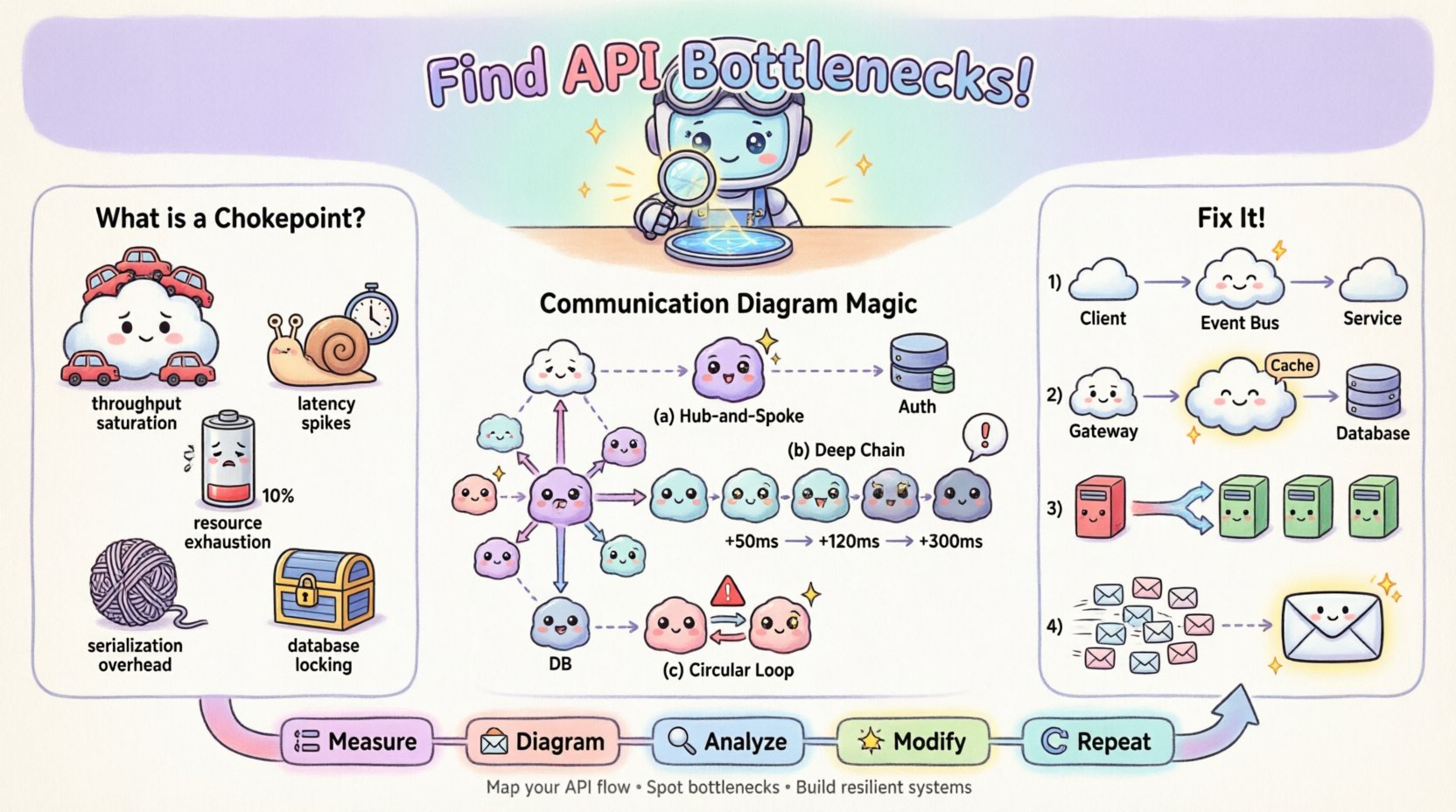
🚦 Verständnis von API-Engpässen
Ein API-Engpass ist ein bestimmter Punkt im Anfrage-Antwort-Zyklus, an dem die Verarbeitung verlangsamt wird oder ausfällt, was zu einer Ansammlung von Aufträgen führt. Im Gegensatz zur allgemeinen Netzwerklatenz, die die gesamte Übertragung beeinflusst, ist ein Engpass oft auf einen bestimmten Dienst, eine Datenbankabfrage oder eine Synchronisationsmechanismus beschränkt. Die Erkennung der Art des Engpasses ist der erste Schritt zur wirksamen Behebung.
Häufige Arten von Engpässen sind:
- Durchsatz-Sättigung: Der empfangende Dienst kann eingehende Anfragen nicht schnell genug verarbeiten, was zu einer Ansammlung in der Warteschlange führt.
- Latenzspitzen: Ein bestimmter Aufruf dauert erheblich länger als der Durchschnitt und verzögert Prozesse im nachfolgenden Teil des Ablaufs.
- Ressourcen-Erschöpfung: Die Grenzen für CPU, Speicher oder Verbindungs-Pools werden erreicht, was zu Zeitüberschreitungen oder Ablehnungsfehlern führt.
- Serialisierungs-Aufwand: Die Kosten für die Datenumwandlung (z. B. JSON-Parser) werden aufgrund der Payload-Größe übermäßig hoch.
- Datenbank-Sperrung: Gleichzeitige Schreibvorgänge blockieren Lesevorgänge oder andere Schreibvorgänge und stoppen den Transaktionsfluss.
Wenn diese Probleme auftreten, zeigen sie sich oft als Kettenreaktionen. Eine Verzögerung in einem Mikrodienst kann Zeitüberschreitungen im aufrufenden Dienst auslösen, die dann die Kette entlang weitergegeben werden. Die Visualisierung dieser Kette ist entscheidend.
📐 Die Rolle von Kommunikationsdiagrammen bei der Fehlersuche
Kommunikationsdiagramme, eine Art von UML-Interaktionsdiagramm (Unified Modeling Language), konzentrieren sich auf die strukturelle Organisation von Objekten und die zwischen ihnen ausgetauschten Nachrichten. Im Gegensatz zu Sequenzdiagrammen, die die zeitliche Reihenfolge der Nachrichten betonen, legen Kommunikationsdiagramme den Fokus auf die Beziehungen und Verbindungen zwischen Objekten. Diese strukturelle Ausrichtung macht sie besonders effektiv bei der Identifizierung architektonischer Engpässe.
Warum diese spezifische Diagrammart zur Fehlersuche verwenden?
- Fokus auf Struktur: Es zeigt auf, welche Objekte zentrale Knotenpunkte sind. Ein einzelnes Objekt, das Nachrichten von zehn anderen empfängt, ist ein hervorragender Kandidat für einen Engpass.
- Nachrichten-Zählung: Sie können visuell die Anzahl der Nachrichten zählen, die in einer einzelnen Transaktion ausgetauscht werden. Ein hoher Fan-out weist auf mögliche Probleme bei der parallelen Verarbeitung hin.
- Pfad-Analyse: Es hebt den längsten Ausführungs-Pfad hervor. Lange Ketten synchroner Aufrufe sind anfällig für die Ansammlung von Latenz.
- Kontext-Klarheit: Es zeigt den Kontext, in dem Objekte existieren, und hilft dabei, festzustellen, ob ein Dienst aufgrund seiner Rolle überlastet ist und nicht aufgrund seines Codes.
Durch die Abbildung der API-Interaktionen in ein Kommunikationsdiagramm verwandeln Sie abstrakte Protokolle in eine greifbare Karte. Diese Karte ermöglicht es Ihnen, den genauen Weg einer Anfrage zu verfolgen und die Anstrengung zu messen, die an jedem Knoten erforderlich ist.
🛠️ Erstellung des Diagnosediagramms
Um ein Kommunikationsdiagramm zur Fehlerbehebung zu verwenden, müssen Sie zunächst eine genaue Darstellung des aktuellen Systemzustands erstellen. Dieser Prozess erfordert die Sammlung von Daten aus Protokollen, Trace-Tools und architektonischen Dokumentationen. Ziel ist es, ein Modell zu erstellen, das der Realität entspricht, nicht einem idealisierten Entwurf.
Schritt 1: Identifizieren Sie die Akteure und Objekte
Beginnen Sie damit, die externen Clients und internen Dienste zu definieren, die an der problematischen Transaktion beteiligt sind. Im Kontext einer API sind dies oft:
- Client: Die mobile App, der Webbrowser oder der Drittanbieterdienst, der die Anfrage initiiert.
- Gateway: Der Einstiegspunkt, der Authentifizierung, Rate Limiting und Routing verwaltet.
- Orchestrator: Der Dienst, der den Ablauf der Geschäftslogik koordiniert.
- Abhängigkeiten: Datenbanken, externe APIs, Caching-Ebenen und Hintergrundarbeiter.
Schritt 2: Abbildung der Nachrichtenflüsse
Zeichnen Sie die Verbindungen zwischen diesen Objekten. Jede Linie stellt eine Nachricht dar. Verwenden Sie Pfeile, um die Richtung des Datenflusses anzuzeigen. Beschriften Sie jeden Pfeil mit dem Methodennamen oder der ausgeführten Aktion (z. B. GET /orders, processPayment).
Für die Fehlerbehebung ist es entscheidend, das Diagramm mit Leistungsdaten zu versehen. Wenn Sie Zugriff auf Zeitmesswerte haben, fügen Sie diese den Nachrichtenbeschriftungen hinzu. Zum Beispiel:
- Gateway ➔ Orchestrator: 50ms
- Orchestrator ➔ Datenbank: 450ms (Warnung)
- Datenbank ➔ Orchestrator: 450ms
Schritt 3: Definieren Sie Interaktions-Lebenslinien
Obwohl Kommunikationsdiagramme nicht immer vertikale Lebenslinien explizit zeigen wie Sequenzdiagramme, müssen Sie die Dauer der Beteiligung jedes Objekts mental verfolgen. Ein Objekt, das lange aktiv bleibt, während es auf eine Antwort wartet, hält Ressourcen unnötigerweise zurück.
🔎 Identifizieren von Engpässen im Diagramm
Sobald das Diagramm mit Daten gefüllt ist, können Sie die Analyse beginnen. Die visuelle Anordnung offenbart oft Probleme, die rohe Protokolle verbergen. Suchen Sie nach spezifischen Mustern, die auf einen Engpass hindeuten.
Muster 1: Das Sternmuster aus Hub und Speichen
Wenn Sie ein einzelnes Objekt sehen, das in einem Sternmuster mit vielen anderen verbunden ist, ist dieses zentrale Objekt wahrscheinlich ein Engpass. Jede Anfrage muss durch es hindurchgehen. Wenn dieses Objekt synchron ist, wird es zu einem seriellen Verarbeitungspunkt.
| Visueller Indikator | Auswirkung | Häufige Ursache |
|---|---|---|
| Ein Objekt mit 10+ eingehenden Pfeilen | Hohe Konkurrenzlast | Aggregationsdienst |
| Mehrere lange horizontale Pfeile, die sich konvergieren | Akkumulation von Wartezeiten | Synchroner Fan-Out |
| Objekt mit hoher CPU-Auslastung gekennzeichnet | Verarbeitungssättigung | Komplexe Logik |
Muster 2: Tiefgehende Aufrufketten
Verfolge den längsten Pfad vom Einstiegspunkt bis zur endgültigen Datenabruf. Wenn der Pfad fünf oder mehr Sprünge umfasst, addiert sich die Latenz. Jeder Sprung fügt Netzwerkoverhead und Verarbeitungszeit hinzu.
- Auswirkung:Gesamtlatenz = Summe aller Sprunglatenzen + Netzwerkoverhead.
- Lösung: Verringere die Tiefe der Aufrufkette durch gemeinsame Standortbestimmung von Daten oder durch Verwendung eines einzigen Aggregationsendpunkts.
Muster 3: Zirkuläre Abhängigkeiten
Obwohl sie in gut strukturierten Systemen seltener vorkommen, können zirkuläre Nachrichten (A ruft B auf, B ruft A auf) zu Deadlocks oder Endlosschleifen führen. Im Leistungsaspekt deuten sie auf ineffizientes Zustandsmanagement hin.
🛠️ Behebungsstrategien basierend auf visueller Analyse
Sobald der Engpass im Diagramm identifiziert ist, können spezifische architektonische Änderungen vorgenommen werden. Das Diagramm dient als Bauplan für diese Änderungen.
1. Entkopplung synchroner Aufrufe
Wenn das Diagramm eine lange Kette synchroner Aufrufe zeigt, wandle das Ende der Kette in ein asynchrones Ereignis um. Anstatt auf die Antwort zu warten, kann der Orchesterer ein Ereignis auslösen und sofort zurückkehren.
- Vorher: Benutzer ➔ API ➔ Dienst A ➔ Dienst B ➔ Datenbank (Warten)
- Nachher: Benutzer ➔ API ➔ Dienst A ➔ Ereignisbus ➔ Dienst B (Auslösen und Vergessen)
2. Caching am Rand
Wenn das Diagramm wiederholte Anfragen an dasselbe Objekt für dieselben Daten zeigt, führe eine Caching-Schicht ein. Platziere dieses Objekt zwischen dem Aufrufer und der belasteten Ressource.
- Diagrammänderung: Füge ein „Cache“-Objekt zwischen den Gateway und die Datenbank ein.
- Beschriftungsaktualisierung: Aktualisieren Sie die Nachrichtenbeschriftung, um „Cache-Hit: 1ms“ gegenüber „Cache-Miss: 200ms“ anzuzeigen.
3. Lastverteilung und Sharding
Wenn ein einzelnes Objekt zu viele Verbindungen hat (das Hub-and-Spoke-Muster), verteilen Sie die Last. Dazu könnte das Sharding von Daten oder die Einführung eines Lastverteilers gehören, der den Datenverkehr über mehrere Instanzen dieses Dienstes rotieren lässt.
4. Anforderungs-Koaleszenz
Wenn das Diagramm mehrere kleine Nachrichten zeigt, die nacheinander an dasselbe Objekt gesendet werden, kombinieren Sie sie zu einer einzigen Massenanforderung. Dadurch wird die Overhead-Kosten für die Verbindungsaufnahme und den Kontextwechsel reduziert.
📊 Analyse von Durchsatz gegenüber Latenz
Kommunikationsdiagramme können ebenfalls helfen, zwischen Durchsatzproblemen und Latenzproblemen zu unterscheiden. Diese Unterscheidung ist entscheidend für die Wahl der richtigen Lösung.
- Hohe Latenz, geringer Durchsatz: Das System ist langsam, verarbeitet aber nur wenige Anfragen. Dies weist meist auf eine einzelne intensive Operation hin (z. B. die Erstellung eines komplexen Berichts).
- Geringe Latenz, geringer Durchsatz: Das System ist schnell, lehnt aber viele Anfragen ab. Dies deutet auf Ressourcenbegrenzungen hin (z. B. Erschöpfung des Verbindungs-Pools).
- Hohe Latenz, hoher Durchsatz: Das System ist langsam und verarbeitet viele Anfragen. Dies ist das klassische Engpass-Szenario, bei dem die Kapazität überlastet ist.
Durch die Annotation Ihres Diagramms mit diesen Metriken können Sie die Kapazitätskurve visualisieren. Markieren Sie das „Schwerer Last“-Szenario in Ihrem Diagramm, um zu sehen, welcher Knoten zuerst ausfällt.
⚠️ Häufige Fehler bei der Erstellung von Diagrammen zur Fehlersuche
Selbst mit den besten Absichten kann die Erstellung eines Diagramms zur Fehlersuche zu Verwirrung führen, wenn bestimmte Fallen nicht vermieden werden.
- Überabstraktion: Gruppieren Sie nicht zu viele Dienste in einer einzigen Box. Wenn Sie die interne Komplexität eines Dienstes verbergen, können Sie nicht erkennen, wo sich der interne Engpass befindet. Halten Sie Dienste atomar.
- Ignorieren asynchroner Abläufe: Wenn Ihr Diagramm nur synchrone Anfragen zeigt, spiegelt es die tatsächliche Last nicht wider. Fügen Sie Hintergrundjobs und Ereignis-Listener in das Diagramm ein.
- Statisch gegenüber Dynamisch: Ein statisches Diagramm zeigt die Architektur; ein dynamisches Diagramm zeigt die Laufzeit. Stellen Sie bei der Fehlersuche sicher, dass Sie Laufzeitdaten (tatsächlich zurückgelegte Pfade) verwenden.
- Fehlende Fehlerpfade: Die meisten Diagramme zeigen den glücklichen Pfad. Ein Engpass tritt oft bei der Fehlerbehandlung auf (z. B. Wiederholungen, Fallbacks). Fügen Sie die Wiederholungsschleifen in das Diagramm ein.
🔄 Iterative Verfeinerung des Diagramms
Die Architektur ist nicht statisch. Während Sie Fehlerbehebungen anwenden, muss sich das Diagramm weiterentwickeln. Nach der Implementierung einer Cacheschicht ändert sich das Diagramm. Die Nachricht vom Gateway zur Datenbank wird durch eine Nachricht an den Cache ersetzt.
Dieser iterative Prozess erzeugt eine Rückkopplungsschleife:
- Messen: Erfassen Sie aktuelle Leistungsmetriken.
- Diagramm: Kartieren Sie den Fluss mit Metriken.
- Analysieren:Identifizieren Sie die Engstelle.
- Ändern:Wenden Sie eine architektonische Änderung an.
- Wiederholen:Messen Sie erneut und aktualisieren Sie die Diagramm.
Diese Schleife stellt sicher, dass Optimierungsmaßnahmen datengestützt und nicht auf Vermutungen basieren.
📈 Integration mit Überwachungssystemen
Obwohl Kommunikationsdiagramme visuelle Werkzeuge sind, müssen sie auf Daten aus Überwachungssystemen basieren. Sie sollten die Diagrammknoten mit spezifischen Protokollströmen oder Telemetrie-IDs verknüpfen.
- Trace-IDs:Stellen Sie sicher, dass jede Nachricht im Diagramm einer eindeutigen Trace-ID in Ihrem Protokollsystem entspricht.
- Heatmaps:Wenn Ihr Überwachungstool dies unterstützt, visualisieren Sie die Aufrufhäufigkeit als Heatmap im Diagramm. Hellere Farben deuten auf höhere Datenverkehrsintensität hin.
- Benachrichtigungen:Legen Sie Benachrichtigungen für die spezifischen Knoten fest, die als Engpässe identifiziert wurden. Wenn der Knoten „Datenbank“ ansteigt, lösen Sie eine Benachrichtigung aus.
🧠 Fallstudie: Die Auftragsverarbeitungskette
Betrachten Sie einen Fall, bei dem ein E-Commerce-Kassenprozess langsam ist. Die ursprüngliche Anfrage zeigt eine Verzögerung von 5 Sekunden.
Anfängliche Diagrammanalyse:
- Client ➔ API-Gateway (10ms)
- Gateway ➔ Auftragsdienst (50ms)
- Auftragsdienst ➔ Bestandsdienst (200ms)
- Auftragsdienst ➔ Zahlungsdienst (4000ms)
- Auftragsdienst ➔ Benachrichtigungsdienst (50ms)
Beobachtung:
Das Diagramm zeigt, dass der Zahlungsdienst der Ausreißer ist. Er verbraucht 80 % der Gesamtzeit. Der Auftragsdienst wartet synchron auf die Beendigung des Zahlungsdienstes, bevor er fortfährt.
Eingriff:
1. Verschieben Sie die Zahlung in einen asynchronen Ablauf. Der Auftragsdienst sendet die Anfrage und markiert den Auftrag als „Wird bearbeitet“. 2. Ein Hintergrundarbeiter behandelt die Zahlungsbestätigung. 3. Aktualisieren Sie das Diagramm, um ein „Zahlungsarbeiter“-Objekt anstelle eines direkten Aufrufs darzustellen.
Ergebnis:
Der Benutzer sieht den Status „Wird bearbeitet“ sofort. Die Gesamtverzögerung für die Benutzererfahrung sinkt von 5 Sekunden auf 50 Millisekunden. Der Hintergrund erledigt die schwere Arbeit asynchron. Das Diagramm spiegelt nun eine widerstandsfähigere Architektur wider.
🎯 Best Practices für die Wartung
Um sicherzustellen, dass diese Diagramme über die Zeit hinweg nützlich bleiben, halten Sie sich an die folgenden Wartungspraktiken.
- Versionskontrolle:Speichern Sie Diagrammdateien im selben Repository wie die Codebasis. Wenn sich der Code ändert, sollte auch das Diagramm geändert werden.
- Überprüfungszyklen:Schließen Sie die Überprüfung von Diagrammen in die Architektur-Entscheidungsprotokolle ein. Stellen Sie sicher, dass neue Dienste vor der Bereitstellung in die Karte aufgenommen werden.
- Standardisierung:Verwenden Sie eine konsistente Notation für Nachrichtentypen (z. B. Anfrage, Antwort, Ereignis), damit alle Teammitglieder die Diagramme verstehen können.
- Dokumentation:Ergänzen Sie das Diagramm mit Notizen, die erklären, *warum* ein bestimmter Pfad existiert. Dadurch wird verhindert, dass zukünftige Entwickler notwendige Logik entfernen.
🔗 Schlussfolgerung
Die Fehlerbehebung bei der API-Leistung ist eine Kombination aus Datenanalyse und struktureller Visualisierung. Kommunikationsdiagramme bieten die notwendige Struktur, um komplexe Interaktionen zu verstehen. Durch die Abbildung von Nachrichtenflüssen, die Annotation von Zeitdaten und die Analyse von Verbindungsstrukturen können Sie Engpässe präzise identifizieren. Dieser Ansatz geht über Vermutungen hinaus und ermöglicht gezielte architektonische Verbesserungen, die Stabilität und Geschwindigkeit des Systems erhöhen.
Denken Sie daran, dass das Diagramm ein lebendiges Dokument ist. Es muss sich entwickeln, je größer das System wird. Regelmäßige Überprüfungen der Karte stellen sicher, dass neue Funktionen keine neuen Engpässe verursachen. Mit einer klaren Sicht auf den Fluss können Sie ein gesundes, hochleistungsfähiges System aufrechterhalten.