











Dans l’architecture logicielle moderne, les interfaces de programmation d’applications (API) agissent comme le tissu conjonctif entre les services. Lorsque ces connexions échouent, l’ensemble du système peut s’arrêter complètement. Identifier la source de la dégradation des performances exige plus que la simple surveillance des métriques ; cela nécessite une compréhension structurale du flux de données à travers le système. Les diagrammes de communication offrent une méthode précise pour visualiser ce flux, permettant aux ingénieurs d’identifier exactement où se produisent les goulets d’étranglement.
Ce guide explore les mécanismes du diagnostic des points de congestion des API à travers le prisme des diagrammes de communication. Nous examinerons la représentation visuelle des interactions entre objets, analyserons les motifs de messages qui indiquent une surcharge, et décrirons une approche systématique pour résoudre les problèmes de latence et de débit sans dépendre d’outils propriétaires.
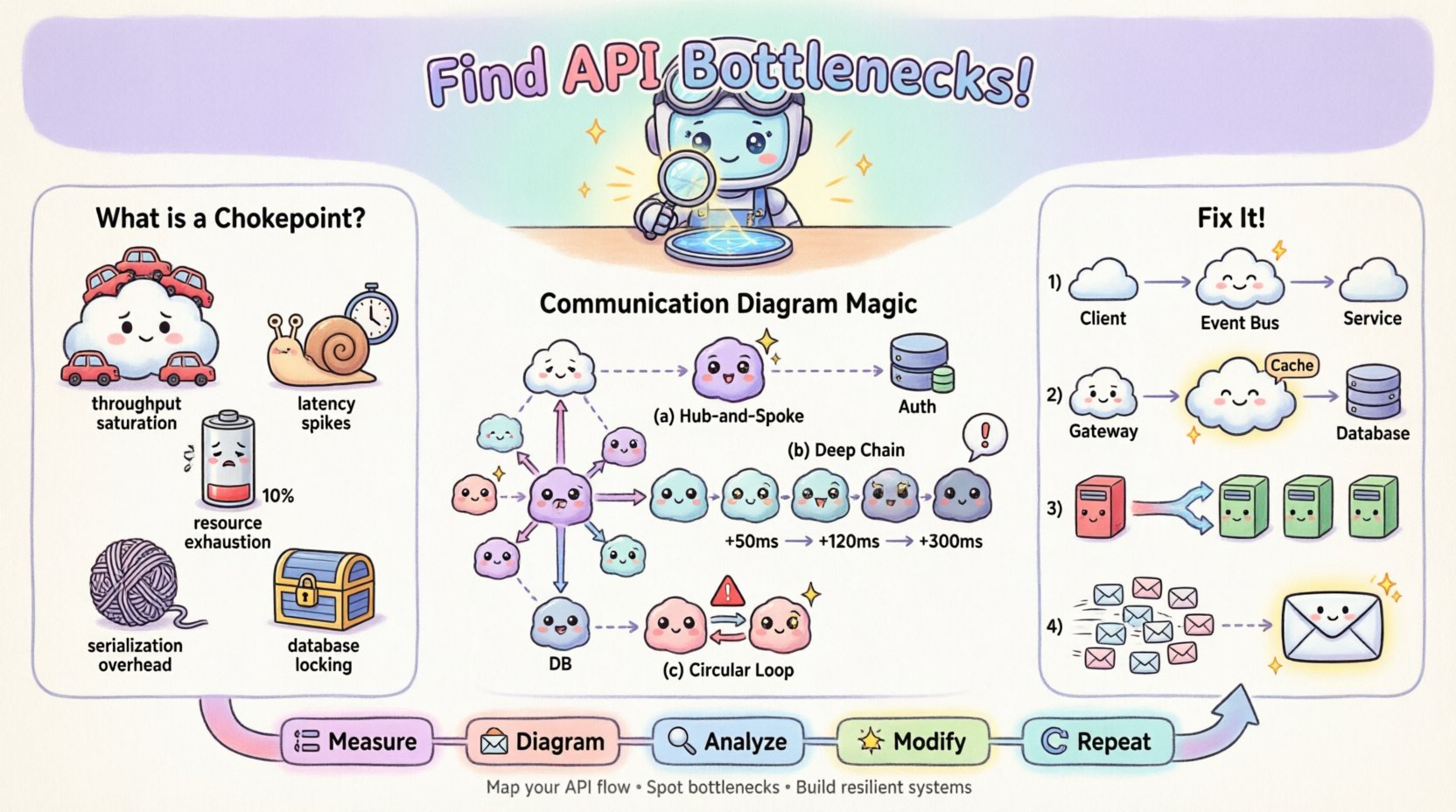
🚦 Comprendre les points de congestion des API
Un point de congestion des API est un point précis au sein du cycle de requête-réponse où le traitement ralentit ou échoue, entraînant un retard accumulé. Contrairement à la latence réseau générale, qui affecte toute la transmission, un point de congestion est souvent localisé à un service spécifique, une requête de base de données ou un mécanisme de synchronisation. Reconnaître le type de point de congestion est la première étape vers une correction efficace.
Les types courants de points de congestion incluent :
- Saturation du débit : Le service récepteur ne peut pas traiter les requêtes entrantes assez rapidement, entraînant une accumulation dans la file d’attente.
- Pic de latence : Un appel spécifique prend considérablement plus de temps que la moyenne, retardant les processus en aval.
- Épuisement des ressources : Les limites de CPU, de mémoire ou de pool de connexions sont atteintes, entraînant des délais d’attente ou des erreurs de rejet.
- Surcharge de sérialisation : Les coûts de transformation des données (par exemple, l’analyse JSON) deviennent excessifs en raison de la taille du chargement.
- Verrouillage de base de données : Les écritures concurrentes bloquent les lectures ou d’autres écritures, bloquant le flux des transactions.
Lorsque ces problèmes surviennent, ils se manifestent souvent sous forme d’échecs en cascade. Un retard dans un microservice peut déclencher des délais d’attente dans le service appelant, qui se propage alors vers le haut de la chaîne. Visualiser cette chaîne est essentiel.
📐 Le rôle des diagrammes de communication dans le débogage
Les diagrammes de communication, une catégorie de diagrammes d’interaction UML (langage de modélisation unifié), se concentrent sur l’organisation structurelle des objets et sur les messages échangés entre eux. Contrairement aux diagrammes de séquence, qui privilégient l’ordre chronologique des messages, les diagrammes de communication mettent l’accent sur les relations et les liens entre les objets. Ce focus structurel les rend particulièrement efficaces pour identifier les goulets d’étranglement architecturaux.
Pourquoi utiliser ce type spécifique de diagramme pour le dépannage ?
- Focus sur la structure : Il révèle quels objets sont des hubs centraux. Un seul objet recevant des messages de dix autres est un candidat idéal pour un point de congestion.
- Comptage des messages : Vous pouvez compter visuellement le nombre de messages échangés au sein d’une seule transaction. Un haut degré de diffusion indique des problèmes potentiels de traitement parallèle.
- Analyse du chemin : Il met en évidence le chemin d’exécution le plus long. Les longues chaînes d’appels synchrones sont sujettes à l’accumulation de latence.
- Clarté du contexte : Il montre le contexte dans lequel les objets existent, aidant à identifier si un service est surchargé en raison de son rôle plutôt que de son code.
En cartographiant les interactions API sur un diagramme de communication, vous transformez des journaux abstraits en une carte concrète. Cette carte vous permet de suivre le trajet exact d’une requête et de mesurer l’effort requis à chaque nœud.
🛠️ Construction du diagramme diagnostique
Pour utiliser un diagramme de communication à des fins de dépannage, vous devez d’abord construire une représentation précise de l’état actuel du système. Ce processus nécessite de rassembler des données provenant des journaux, des outils de traçage et de la documentation architecturale. L’objectif est de créer un modèle qui reflète la réalité, et non un design idéalisé.
Étape 1 : Identifier les acteurs et les objets
Commencez par définir les clients externes et les services internes impliqués dans la transaction problématique. Dans le contexte d’une API, ce sont souvent :
- Client : L’application mobile, le navigateur web ou le service tiers qui initie la requête.
- Passerelle : Le point d’entrée qui gère l’authentification, le contrôle de débit et le routage.
- Orchestrateur : Le service qui coordonne le flux de logique métier.
- Dépendances : Bases de données, APIs externes, couches de mise en mémoire tampon et travailleurs en arrière-plan.
Étape 2 : Cartographier les flux de messages
Tracez les connexions entre ces objets. Chaque ligne représente un message. Utilisez des flèches pour indiquer le sens du flux de données. Étiquetez chaque flèche avec le nom de la méthode ou l’action effectuée (par exemple, GET /orders, processPayment).
Pour le dépannage, il est crucial d’annoter le diagramme avec des données de performance. Si vous avez accès à des métriques de temps, ajoutez-les aux étiquettes des messages. Par exemple :
- Passerelle ➔ Orchestrateur : 50 ms
- Orchestrateur ➔ Base de données : 450 ms (Avertissement)
- Base de données ➔ Orchestrateur : 450 ms
Étape 3 : Définir les lignes de vie des interactions
Bien que les diagrammes de communication n’affichent pas toujours explicitement des lignes de vie verticales comme les diagrammes de séquence, vous devez suivre mentalement la durée de l’implication de chaque objet. Un objet qui reste actif pendant une longue durée en attendant une réponse utilise inutilement des ressources.
🔎 Identification des goulets d’étranglement dans le diagramme
Une fois le diagramme rempli de données, vous pouvez commencer l’analyse. La disposition visuelle révèle souvent des problèmes que les journaux bruts cachent. Recherchez des motifs spécifiques qui indiquent un point de congestion.
Modèle 1 : L’étoile à hub et rayons
Si vous voyez un objet unique connecté à de nombreux autres selon un schéma d’étoile, cet objet central est probablement un goulet d’étranglement. Toutes les requêtes doivent passer par lui. Si cet objet est synchrone, il devient un point de traitement séquentiel.
| Indicateur visuel | Implication | Cause courante |
|---|---|---|
| Un objet avec 10+ flèches entrantes | Charge de concurrence élevée | Service d’agrégation |
| Plusieurs flèches horizontales longues convergentes | Accumulation du temps d’attente | Fan-out synchrone |
| Objet étiqueté avec un taux élevé d’utilisation du CPU | Saturation du traitement | Logique complexe |
Modèle 2 : Chaînes d’appels profondes
Suivez le chemin le plus long depuis le point d’entrée jusqu’à la récupération finale des données. Si le chemin implique cinq sauts ou plus, la latence s’accumulera. Chaque saut ajoute une surcharge réseau et un temps de traitement.
- Impact :Latence totale = Somme de toutes les latences de saut + surcharge réseau.
- Solution : Réduire la profondeur de la chaîne d’appels en regroupant les données ou en utilisant un seul point d’entrée d’agrégation.
Modèle 3 : Dépendances circulaires
Bien que moins fréquent dans les systèmes bien structurés, les messages circulaires (A appelle B, B appelle A) peuvent provoquer un blocage ou des boucles infinies. Dans un contexte de performance, ils indiquent une gestion d’état inefficace.
🛠️ Stratégies de correction basées sur l’analyse visuelle
Une fois le goulot d’étranglement identifié sur le diagramme, des modifications architecturales spécifiques peuvent être appliquées. Le diagramme sert de plan directeur pour ces modifications.
1. Découplage des appels synchrones
Si le diagramme montre une longue chaîne d’appels synchrones, convertissez la fin de la chaîne en un événement asynchrone. Au lieu d’attendre la réponse, l’orchestrateur peut déclencher un événement et retourner immédiatement.
- Avant : Utilisateur ➔ API ➔ Service A ➔ Service B ➔ Base de données (Attente)
- Après : Utilisateur ➔ API ➔ Service A ➔ Bus d’événements ➔ Service B (Déclencher et oublier)
2. Mise en cache au niveau de la périphérie
Si le diagramme montre des requêtes répétées vers le même objet pour les mêmes données, introduisez une couche de mise en cache. Placez cet objet entre l’appelant et la ressource lourde.
- Changement de diagramme : Insérez un objet « Cache » entre la passerelle et la base de données.
- Mise à jour de l’étiquette : Mettez à jour l’étiquette du message pour afficher « Cache réussi : 1 ms » contre « Cache manqué : 200 ms ».
3. Équilibrage de charge et fractionnement (sharding)
Si un seul objet possède trop de connexions (schéma Hub-and-Spoke), répartissez la charge. Cela peut impliquer le fractionnement des données ou l’introduction d’un équilibreur de charge pour redistribuer le trafic entre plusieurs instances de ce service.
4. Regroupement des requêtes
Si le diagramme montre plusieurs petits messages envoyés au même objet en succession rapide, regroupez-les en une seule requête groupée. Cela réduit la surcharge liée à l’établissement de connexion et au changement de contexte.
📊 Analyse du débit par rapport à la latence
Les diagrammes de communication peuvent également aider à distinguer les problèmes de débit de ceux de latence. Cette distinction est essentielle pour choisir la bonne solution.
- Haute latence, faible débit : Le système est lent mais traite peu de requêtes. Cela indique généralement une seule opération lourde (par exemple, la génération d’un rapport complexe).
- Faible latence, faible débit : Le système est rapide mais rejette de nombreuses requêtes. Cela indique des limites de ressources (par exemple, épuisement du pool de connexions).
- Haute latence, haut débit : Le système est lent et traite de nombreuses requêtes. Il s’agit du scénario classique de goulot d’étranglement où la capacité est dépassée.
En annotant votre diagramme avec ces métriques, vous pouvez visualiser la courbe de capacité. Annotez le scénario « Charge élevée » sur votre diagramme pour voir quel nœud cède en premier.
⚠️ Pièges courants dans la création de diagrammes pour le débogage
Même avec les meilleures intentions, la création d’un diagramme pour le débogage peut entraîner de la confusion si certains pièges ne sont pas évités.
- Sur-abstraction : Ne regroupez pas trop de services dans une seule boîte. Si vous masquez la complexité interne d’un service, vous ne pourrez pas identifier où se situe le goulot d’étranglement interne. Gardez les services atomiques.
- Ignorer les flux asynchrones : Si votre diagramme ne montre que des requêtes synchrones, il ne reflétera pas la charge réelle. Incluez les tâches en arrière-plan et les écouteurs d’événements dans le diagramme.
- Statique vs. Dynamique : Un diagramme statique montre la conception ; un diagramme dynamique montre l’exécution en temps réel. Pour le débogage, assurez-vous d’utiliser des données d’exécution (chemins réels empruntés).
- Chemins d’erreur manquants : La plupart des diagrammes montrent le chemin idéal. Un goulot d’étranglement survient souvent lors du traitement des erreurs (par exemple, les réessais, les alternatives). Incluez les boucles de réessai dans le diagramme.
🔄 Affinement itératif du diagramme
L’architecture n’est pas statique. À mesure que vous appliquez des corrections, le diagramme doit évoluer. Après avoir mis en œuvre une couche de mémoire cache, le diagramme change. Le message provenant de la passerelle vers la base de données est remplacé par un message vers la mémoire cache.
Ce processus itératif crée une boucle de rétroaction :
- Mesurer : Capturer les métriques de performance actuelles.
- Diagramme : Cartographiez le flux à l’aide de métriques.
- Analysez : Identifiez le goulot d’étranglement.
- Modifiez : Appliquez un changement architectural.
- Répétez : Re-mesurez et mettez à jour le diagramme.
Cette boucle garantit que les efforts d’optimisation sont fondés sur des données plutôt que sur des suppositions.
📈 Intégration avec les systèmes de surveillance
Bien que les diagrammes de communication soient des outils visuels, ils doivent être ancrés dans des données provenant des systèmes de surveillance. Vous devez corrélater les nœuds du diagramme avec des flux de journaux spécifiques ou des identifiants de télémétrie.
- Identifiants de traçage : Assurez-vous que chaque message du diagramme correspond à un identifiant de traçage unique dans votre système de journalisation.
- Cartes thermiques : Si votre outil de surveillance le permet, visualisez la fréquence des appels sous forme de carte thermique sur le diagramme. Les couleurs plus chaudes indiquent un volume de trafic plus élevé.
- Alertes : Définissez des alertes pour les nœuds spécifiques identifiés comme points de congestion. Si le nœud « Base de données » connaît une augmentation soudaine, déclenchez une notification.
🧠 Étude de cas : La chaîne de traitement des commandes
Considérez un scénario où le processus de paiement e-commerce est lent. La requête initiale affiche un délai de 5 secondes.
Analyse initiale du diagramme :
- Client ➔ Passerelle API (10 ms)
- Passerelle ➔ Service de commande (50 ms)
- Service de commande ➔ Service de stock (200 ms)
- Service de commande ➔ Service de paiement (4000 ms)
- Service de commande ➔ Service de notification (50 ms)
Observation :
Le diagramme révèle que le Service de paiement est l’anomalie. Il consomme 80 % du temps total. Le Service de commande attend de manière synchrone que le Service de paiement soit terminé avant de poursuivre.
Intervention :
1. Déplacez le paiement vers un flux asynchrone. Le Service de commande envoie la requête et marque la commande comme « En cours de traitement ». 2. Un travailleur en arrière-plan gère la confirmation du paiement. 3. Mettez à jour le diagramme pour afficher un objet « Worker de paiement » au lieu d’un appel direct.
Résultat :
L’utilisateur voit immédiatement l’état « En cours de traitement ». La latence totale pour l’expérience utilisateur passe de 5 secondes à 50 millisecondes. Le backend gère le traitement lourd de manière asynchrone. Le diagramme reflète désormais une architecture plus résiliente.
🎯 Meilleures pratiques pour la maintenance
Pour garder ces diagrammes utiles dans le temps, respectez les pratiques de maintenance suivantes.
- Contrôle de version :Stockez les fichiers de diagramme dans le même dépôt que la base de code. Lorsque le code change, le diagramme doit également changer.
- Cycles de revue :Incluez les revues de diagrammes dans les registres des décisions d’architecture. Assurez-vous que les nouveaux services sont ajoutés à la carte avant le déploiement.
- Standardisation :Utilisez une notation cohérente pour les types de messages (par exemple, requête, réponse, événement) afin que les diagrammes soient lisibles par tous les membres de l’équipe.
- Documentation :Annotez le diagramme avec des notes expliquant *pourquoi* un chemin spécifique existe. Cela empêche les ingénieurs futurs de supprimer des logiques nécessaires.
🔗 Conclusion
Le dépannage des performances de l’API est une combinaison d’analyse de données et de visualisation structurelle. Les diagrammes de communication fournissent la structure nécessaire pour comprendre les interactions complexes. En cartographiant les flux de messages, en annotant les données de temporisation et en analysant les schémas de connexion, vous pouvez identifier avec précision les points de congestion. Cette approche va au-delà des suppositions et permet des améliorations architecturales ciblées qui améliorent la stabilité et la vitesse du système.
Souvenez-vous que le diagramme est un document vivant. Il doit évoluer avec le système. Revoir régulièrement la carte garantit que les nouvelles fonctionnalités n’introduisent pas de nouveaux goulets d’étranglement. Avec une vue claire du flux, vous pouvez maintenir un système sain et à haute performance.