











Na arquitetura de software moderna, as Interfaces de Programação de Aplicativos (APIs) atuam como o tecido conectivo entre os serviços. Quando essas conexões falham, todo o sistema pode parar completamente. Identificar a origem da degradação de desempenho exige mais do que apenas monitorar métricas; exige uma compreensão estrutural de como os dados fluem pelo sistema. Diagramas de comunicação oferecem um método preciso para visualizar esse fluxo, permitindo que engenheiros identifiquem exatamente onde ocorrem gargalos.
Este guia explora a mecânica da diagnóstico de gargalos de API sob a perspectiva dos diagramas de comunicação. Analisaremos a representação visual das interações entre objetos, examinaremos padrões de mensagens que indicam estresse e apresentaremos uma abordagem sistemática para resolver problemas de latência e throughput sem depender de ferramentas proprietárias.
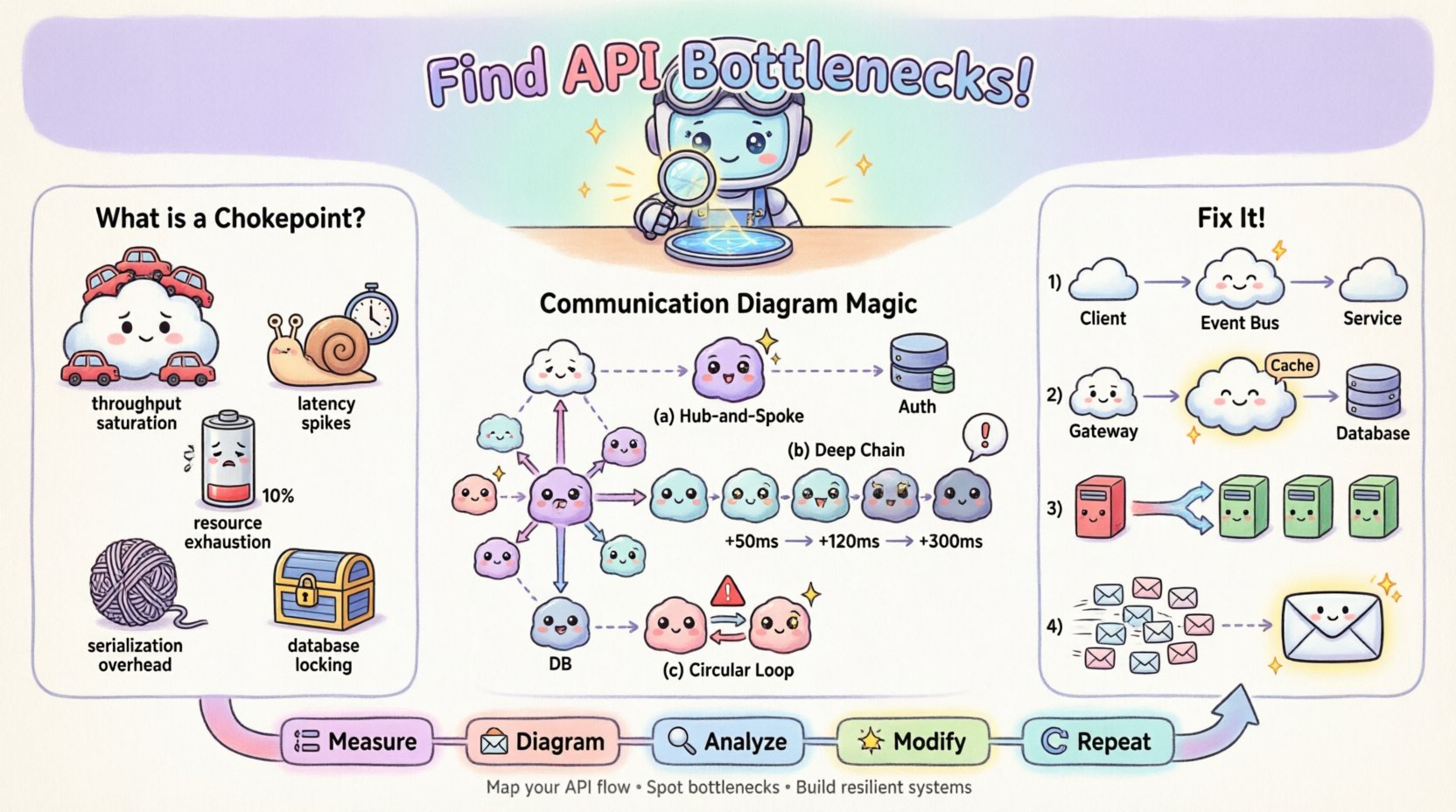
🚦 Compreendendo gargalos de API
Um gargalo de API é um ponto específico no ciclo de solicitação-resposta onde o processamento desacelera ou falha, causando uma fila de espera. Diferentemente da latência de rede geral, que afeta toda a transmissão, um gargalo geralmente está localizado em um serviço específico, consulta ao banco de dados ou mecanismo de sincronização. Reconhecer o tipo de gargalo é o primeiro passo para uma correção eficaz.
Tipos comuns de gargalos incluem:
- Saturação de throughput:O serviço receptor não consegue processar as solicitações recebidas com rapidez suficiente, resultando na acumulação de filas.
- Picos de latência:Uma chamada específica leva significativamente mais tempo que a média, atrasando os processos downstream.
- Exaustão de recursos:Os limites de CPU, memória ou pool de conexões são atingidos, causando tempos limite ou erros de rejeição.
- Custo de serialização:Os custos de transformação de dados (por exemplo, análise de JSON) tornam-se excessivos devido ao tamanho da carga útil.
- Bloqueio de banco de dados:Escritas concorrentes bloqueiam leituras ou outras escritas, travando o fluxo de transações.
Quando esses problemas ocorrem, muitas vezes se manifestam como falhas em cascata. Um atraso em um microsserviço pode acionar tempos limite no serviço chamador, que então se propaga para cima na cadeia. Visualizar essa cadeia é essencial.
📐 O papel dos diagramas de comunicação na depuração
Diagramas de comunicação, um tipo de diagrama de interação UML (Linguagem Unificada de Modelagem), focam na organização estrutural dos objetos e nas mensagens trocadas entre eles. Diferentemente dos diagramas de sequência, que priorizam a ordem cronológica das mensagens, os diagramas de comunicação enfatizam as relações e os links entre objetos. Esse foco estrutural os torna particularmente eficazes para identificar gargalos arquitetônicos.
Por que usar este tipo específico de diagrama para solução de problemas?
- Foco na estrutura:Revela quais objetos são centros principais. Um único objeto que recebe mensagens de dez outros é um candidato ideal para um gargalo.
- Contagem de mensagens:Você pode contar visualmente o número de mensagens trocadas em uma única transação. Alta dispersão indica possíveis problemas de processamento paralelo.
- Análise de caminho:Destaca o caminho de execução mais longo. Cadeias longas de chamadas síncronas são propensas ao acúmulo de latência.
- Clareza de contexto:Mostra o contexto em que os objetos existem, ajudando a identificar se um serviço está sobrecarregado devido ao seu papel e não ao seu código.
Ao mapear as interações de API em um diagrama de comunicação, você transforma logs abstratos em um mapa tangível. Esse mapa permite rastrear o caminho exato que uma solicitação percorre e medir o esforço necessário em cada nó.
🛠️ Construindo o diagrama diagnóstico
Para usar um diagrama de comunicação para solução de problemas, você deve primeiro construir uma representação precisa do estado atual do sistema. Esse processo exige coletar dados de logs, ferramentas de rastreamento e documentação arquitetônica. O objetivo é criar um modelo que reflita a realidade, e não um design idealizado.
Passo 1: Identifique os Atores e Objetos
Comece definindo os clientes externos e os serviços internos envolvidos na transação problemática. No contexto de uma API, esses são frequentemente:
- Cliente: O aplicativo móvel, navegador web ou serviço de terceiros que inicia a solicitação.
- Gateway: O ponto de entrada que gerencia autenticação, limitação de taxa e roteamento.
- Orquestrador: O serviço que coordena o fluxo da lógica de negócios.
- Dependências: Bancos de dados, APIs externas, camadas de cache e trabalhadores em segundo plano.
Passo 2: Mapeie os Fluxos de Mensagens
Desenhe as conexões entre esses objetos. Cada linha representa uma mensagem. Use setas para indicar a direção do fluxo de dados. Rotule cada seta com o nome do método ou a ação sendo realizada (por exemplo, GET /pedidos, processarPagamento).
Para solução de problemas, é crucial anotar o diagrama com dados de desempenho. Se você tiver acesso a métricas de tempo, adicione-as às rótulos das mensagens. Por exemplo:
- Gateway ➔ Orquestrador: 50ms
- Orquestrador ➔ Banco de dados: 450ms (Aviso)
- Banco de dados ➔ Orquestrador: 450ms
Passo 3: Defina as Linhas de Vida das Interações
Embora os diagramas de comunicação nem sempre mostrem explicitamente linhas de vida verticais como os diagramas de sequência, você deve rastrear mentalmente a duração da participação de cada objeto. Um objeto que permanece ativo por longo tempo enquanto aguarda uma resposta está segurando recursos desnecessariamente.
🔎 Identificando gargalos no diagrama
Uma vez que o diagrama está preenchido com dados, você pode começar a análise. A disposição visual revela frequentemente problemas que os logs brutos escondem. Procure padrões específicos que indiquem um gargalo.
Padrão 1: A Estrela Hub-and-Spoke
Se você observar um único objeto conectado a muitos outros em um padrão de estrela, esse objeto central provavelmente é um gargalo. Todas as solicitações devem passar por ele. Se esse objeto for síncrono, torna-se um ponto de processamento serial.
| Indicador Visual | Implicação | Causa Comum |
|---|---|---|
| Um objeto com 10+ setas entrantes | Alto carregamento de concorrência | Serviço de Agregação |
| Múltiplas setas horizontais longas convergindo | Acúmulo de Tempo de Espera | Fan-out Síncrono |
| Objeto rotulado com alto uso de CPU % | Saturação de Processamento | Lógica Complexa |
Padrão 2: Cadeias de Chamadas Profundas
Trace o caminho mais longo desde o ponto de entrada até a recuperação final dos dados. Se o caminho envolver cinco ou mais saltos, a latência será acumulada. Cada salto adiciona sobrecarga de rede e tempo de processamento.
- Impacto:Latência total = Soma de todas as latências dos saltos + sobrecarga de rede.
- Solução: Reduza a profundidade da cadeia de chamadas co-localizando dados ou usando um único ponto de extremidade agregado.
Padrão 3: Dependências Circulares
Embora menos comum em sistemas bem estruturados, mensagens circulares (A chama B, B chama A) podem causar bloqueios ou loops infinitos. Em um contexto de desempenho, indicam uma gestão ineficiente do estado.
🛠️ Estratégias de Remediação Baseadas na Análise Visual
Uma vez localizado o gargalo no diagrama, mudanças arquitetônicas específicas podem ser aplicadas. O diagrama serve como o projeto para essas mudanças.
1. Desacoplamento de Chamadas Síncronas
Se o diagrama mostrar uma longa cadeia de chamadas síncronas, converta a parte final da cadeia em um evento assíncrono. Em vez de esperar pela resposta, o orquestrador pode disparar um evento e retornar imediatamente.
- Antes: Usuário ➔ API ➔ Serviço A ➔ Serviço B ➔ Banco de Dados (Espera)
- Depois: Usuário ➔ API ➔ Serviço A ➔ Barramento de Eventos ➔ Serviço B (Disparar e Esquecer)
2. Cache na Borda
Se o diagrama mostrar solicitações repetidas ao mesmo objeto para os mesmos dados, introduza uma camada de cache. Coloque esse objeto entre o chamador e o recurso pesado.
- Alteração no Diagrama: Insira um objeto “Cache” entre o Gateway e o Banco de Dados.
- Atualização da Rótulo: Atualize a etiqueta da mensagem para mostrar “Acerto no Cache: 1ms” em vez de “Falha no Cache: 200ms”.
3. Balanceamento de Carga e Shardização
Se um único objeto tiver demasiadas conexões (padrão Hub-and-Spoke), distribua a carga. Isso pode envolver a shardização de dados ou a introdução de um balanceador de carga para rotear o tráfego entre várias instâncias desse serviço.
4. Agrupamento de Requisições
Se o diagrama mostrar múltiplas mensagens pequenas enviadas ao mesmo objeto em rápida sucessão, combine-as em uma única requisição em lote. Isso reduz a sobrecarga de estabelecimento de conexão e troca de contexto.
📊 Análise de Throughput versus Latência
Diagramas de comunicação também podem ajudar a distinguir entre problemas de throughput e problemas de latência. Essa distinção é vital para escolher a correção adequada.
- Alta Latência, Baixo Throughput: O sistema é lento, mas processa poucas requisições. Isso geralmente aponta para uma única operação pesada (por exemplo, a geração de um relatório complexo).
- Baixa Latência, Baixo Throughput: O sistema é rápido, mas rejeita muitas requisições. Isso aponta para limites de recursos (por exemplo, esgotamento da pool de conexões).
- Alta Latência, Alto Throughput: O sistema é lento e está lidando com muitas requisições. Este é o cenário clássico de gargalo, onde a capacidade é superada.
Ao anotar seu diagrama com essas métricas, você pode visualizar a curva de capacidade. Anote o cenário de “Carga Pesada” no seu diagrama para ver qual nó falha primeiro.
⚠️ Armadilhas Comuns na Elaboração de Diagramas para Depuração
Mesmo com as melhores intenções, criar um diagrama para depuração pode levar à confusão se certas armadilhas não forem evitadas.
- Sobreabstração: Não agrupe muitos serviços em uma única caixa. Se ocultar a complexidade interna de um serviço, não será possível identificar onde está o gargalo interno. Mantenha os serviços atômicos.
- Ignorar Fluxos Assíncronos: Se o seu diagrama mostrar apenas requisições síncronas, ele não refletirá a carga real. Inclua trabalhos em segundo plano e ouvintes de eventos no diagrama.
- Estático versus Dinâmico: Um diagrama estático mostra o design; um diagrama dinâmico mostra o tempo de execução. Para depuração, certifique-se de estar usando dados em tempo de execução (caminhos reais percorridos).
- Caminhos de Erro Ausentes: A maioria dos diagramas mostra o caminho feliz. Um gargalo frequentemente ocorre durante o tratamento de erros (por exemplo, repetições, fallbacks). Inclua os loops de repetição no diagrama.
🔄 Aperfeiçoamento Iterativo do Diagrama
A arquitetura não é estática. À medida que você aplica correções, o diagrama deve evoluir. Após a implementação de uma camada de cache, o diagrama muda. A mensagem do Gateway para o Banco de Dados é substituída por uma mensagem para o Cache.
Esse processo iterativo cria um ciclo de feedback:
- Medir: Capture as métricas de desempenho atuais.
- Diagrama: Mapeie o fluxo com métricas.
- Analise:Identifique o gargalo.
- Modifique:Aplicar mudança arquitetônica.
- Repita:Re-mensure e atualize o diagrama.
Este ciclo garante que os esforços de otimização sejam baseados em dados, em vez de adivinhações.
📈 Integração com Sistemas de Monitoramento
Embora os diagramas de comunicação sejam ferramentas visuais, eles devem ser baseados em dados provenientes de sistemas de monitoramento. Você deve correlacionar os nós do diagrama com fluxos de logs específicos ou IDs de telemetria.
- IDs de Rastreamento:Garanta que cada mensagem no diagrama corresponda a um ID de Rastreamento exclusivo no seu sistema de registro.
- Mapas de Calor:Se a sua ferramenta de monitoramento permitir, visualize a frequência de chamadas como um mapa de calor no diagrama. Cores mais quentes indicam maior volume de tráfego.
- Alertas:Defina alertas para os nós específicos identificados como gargalos. Se o nó “Banco de Dados” apresentar picos, acione uma notificação.
🧠 Estudo de Caso: A Cadeia de Processamento de Pedidos
Considere um cenário em que o processo de checkout de um e-commerce é lento. A requisição inicial mostra um atraso de 5 segundos.
Análise Inicial do Diagrama:
- Cliente ➔ Gateway da API (10ms)
- Gateway ➔ Serviço de Pedidos (50ms)
- Serviço de Pedidos ➔ Serviço de Estoque (200ms)
- Serviço de Pedidos ➔ Serviço de Pagamento (4000ms)
- Serviço de Pedidos ➔ Serviço de Notificação (50ms)
Observação:
O diagrama revela que o Serviço de Pagamento é o outlier. Ele consome 80% do tempo total. O Serviço de Pedidos aguarda sincronicamente a conclusão do Serviço de Pagamento antes de prosseguir.
Intervenção:
1. Mova o pagamento para um fluxo assíncrono. O Serviço de Pedidos envia a requisição e marca o pedido como “Em Processamento”. 2. Um trabalhador em segundo plano trata a confirmação do pagamento. 3. Atualize o diagrama para mostrar um objeto “Trabalhador de Pagamento” em vez de uma chamada direta.
Resultado:
O usuário vê o status “Em Processamento” imediatamente. A latência total para a experiência do usuário cai de 5 segundos para 50 milissegundos. O backend realiza o trabalho pesado de forma assíncrona. O diagrama agora reflete uma arquitetura mais resiliente.
🎯 Melhores Práticas para Manutenção
Para manter esses diagramas úteis ao longo do tempo, siga as seguintes práticas de manutenção.
- Controle de Versão: Armazene os arquivos do diagrama no mesmo repositório que o código-fonte. Quando o código mudar, o diagrama também deve mudar.
- Ciclos de Revisão: Inclua revisões de diagramas nos registros de decisões arquitetônicas. Certifique-se de que novos serviços sejam adicionados ao mapa antes da implantação.
- Padronização: Use notação consistente para os tipos de mensagens (por exemplo, solicitação, resposta, evento) para tornar os diagramas legíveis por todos os membros da equipe.
- Documentação: Anote o diagrama com observações explicando *por que* um caminho específico existe. Isso evita que engenheiros futuros removam lógica necessária.
🔗 Conclusão
Solucionar problemas de desempenho da API é uma combinação de análise de dados e visualização estrutural. Diagramas de comunicação fornecem a estrutura necessária para entender interações complexas. Ao mapear fluxos de mensagens, anotar dados de tempo e analisar padrões de conexão, você pode identificar gargalos com precisão. Essa abordagem vai além da adivinhação e permite melhorias arquitetônicas direcionadas que aumentam a estabilidade e a velocidade do sistema.
Lembre-se de que o diagrama é um documento vivo. Ele deve evoluir conforme o sistema cresce. Revisar regularmente o mapa garante que novos recursos não introduzam novos gargalos. Com uma visão clara do fluxo, você pode manter um sistema saudável e de alto desempenho.