











W złożonych systemach wydajność nie zawsze jest oczywista, dopóki nie nastąpi spowolnienie. Gdy procesy zatrzymują się, dane opóźniają się lub przepustowość spada, podstawowym problemem często jest ruch informacji, a nie przechowywanie lub przetwarzanie danych. Analiza przepływu danych zapewnia strukturalny sposób wizualizacji ruchu informacji przez system, co ułatwia wykrycie miejsc, w których pojawia się tarcie. Przyporządkowując te przepływy, zespoły mogą precyzyjnie wskazać miejsca, w których przekroczona jest pojemność lub gromadzą się niepotrzebne opóźnienia. 🧭
Ten podejście wymaga jasnego zrozumienia architektury systemu bez korzystania z narzędzi własnych. Celem jest stworzenie logicznego ramy, która ujawnia nieefektywności. Niezależnie od zarządzania potokiem oprogramowania, linią produkcyjną czy przepływem administracyjnym, zasady pozostają takie same. Identyfikacja tych ograniczeń pozwala na skierowane działania, które przynoszą mierzalne poprawy szybkości i niezawodności. ⚙️
Zrozumienie podstaw diagramów przepływu danych 🗺️
Zanim znajdzie się zator, należy zrozumieć mapę. Diagram przepływu danych (DFD) to graficzne przedstawienie przepływu danych przez system informacyjny. Skupia się na tym, skąd pochodzą dane, dokąd idą i jak się zmieniają. W przeciwieństwie do schematów blokowych przedstawiających logikę sterowania, DFDy podkreślają ruch i przekształcanie elementów danych.
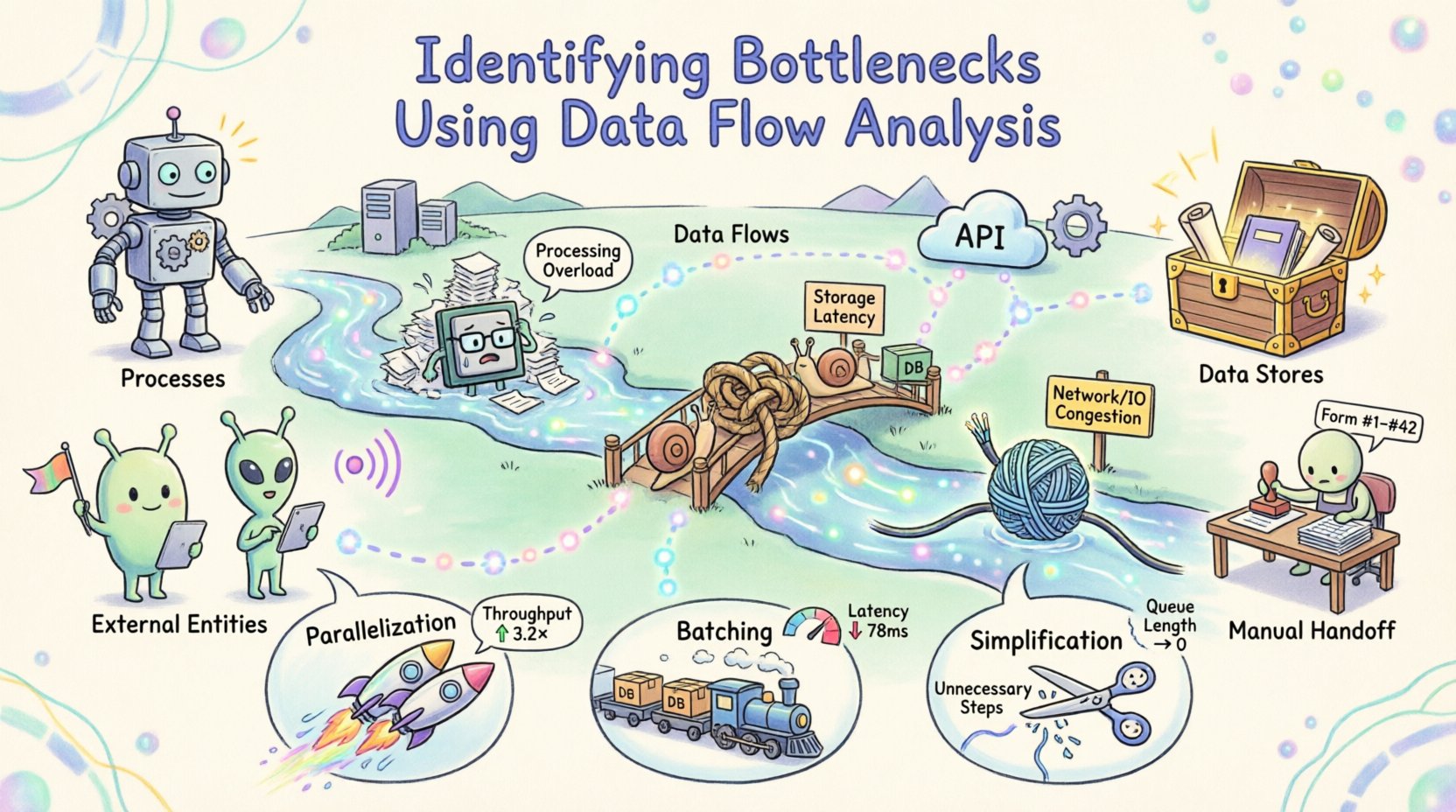
W standardowym DFD znajdują się cztery główne komponenty:
- Procesy:Przekształcenia, które przekształcają dane wejściowe w dane wyjściowe. Często przedstawiane są jako okręgi lub prostokąty z zaokrąglonymi rogami.
- Magazyny danych:Miejsca, w których dane są przechowywane do późniejszego użytku, takie jak bazy danych lub pliki.
- Zewnętrzne jednostki:Źródła lub docelowe jednostki poza granicami systemu, takie jak użytkownicy lub inne systemy.
- Przepływy danych:Ścieżki, po których dane poruszają się między komponentami.
Tworzenie diagramu najwyższego poziomu ustala zakres. Diagram niższego poziomu następnie szczegółowo analizuje konkretne procesy. Ta hierarchia pozwala analitykom badania systemu na różnych poziomach szczegółowości. Jeśli występuje opóźnienie na poziomie makro, przybliżenie ujawnia konkretny proces lub przekaz powodujący opóźnienie. 🔍
Anatomia zatoru w systemie 🚦
Zator to dowolny punkt w systemie, w którym przepływ danych jest ograniczony, powodując gromadzenie się danych lub opóźnienia. W kontekście analizy przepływu danych zatory mogą się objawiać na kilka różnych sposobów. Rozpoznanie rodzaju ograniczenia to pierwszy krok w kierunku rozwiązania.
| Typ zatoru | Opis | Typowe objawy |
|---|---|---|
| Przetwarzanie | Obliczenia lub logika trwają dłużej niż strumień danych wejściowych może obsłużyć. | Kolejki gromadzą się przed procesem; zauważalne są wysokie zużycie CPU lub pamięci. |
| Przechowywanie | Odczyt lub zapis danych do bazy danych lub systemu plików jest powolny. | Opóźnienie wzrasta podczas pobierania danych; czasy transakcji bardzo się różnią. |
| Sieć/Wyjście/Wyjście | Prędkość transferu między komponentami jest ograniczona przez przepustowość lub opóźnienie. | Występują timeouty; duże przesyłki danych często się zatrzymują. |
| Człowiek | Wymagane jest ręczne działanie tam, gdzie powinna występować automatyzacja. | Zadania czekają na zatwierdzenie; błędy pojawiają się z powodu zmęczenia lub złożoności. |
Zrozumienie tych kategorii pomaga w priorytetyzacji napraw. Ograniczenie sieci może wymagać zmian infrastruktury, podczas gdy ograniczenie przetwarzania może wymagać optymalizacji algorytmów. Bez tej różnicy wysiłki mogą być skierowane w nieodpowiednie miejsca, które nie ograniczają systemu. 🛠️
Metodologia identyfikacji 🔎
Identyfikacja węzłów zakłóceń to nie jednorazowy wydarzenie, ale systematyczne badanie. Poniższe kroki przedstawiają solidny podejście do analizy przepływów danych i lokalizacji ograniczeń.
1. Zmapuj stan obecny
Zacznij od dokumentowania istniejącej architektury. Nie polegaj na pamięci ani założeniach. Rozmawiaj z zaangażowanymi stronami i przeglądaj dokumentację, aby uchwycić rzeczywisty przepływ informacji. Stwórz diagram poziomu 0 pokazujący granice systemu i interakcje zewnętrzne. Następnie stwórz diagramy poziomu 1, które rozkładają główne procesy. Upewnij się, że każdy przepływ danych ma zdefiniowany wejście i wyjście.
2. Zdefiniuj metryki do pomiaru
Mapy wizualne są jakościowe. Aby znaleźć węzły zakłóceń, potrzebujesz danych ilościowych. Wybierz kluczowe wskaźniki wydajności (KPI) dla każdego procesu i przepływu danych. Odpowiednie metryki obejmują:
- Przepustowość: Ilość danych przetwarzanych w jednostce czasu.
- Opóźnienie: Czas potrzebny na przesłanie danych od źródła do celu.
- Wykorzystanie: Procent czasu, przez który zasób jest aktywny.
- Długość kolejki: Liczba elementów czekających na przetworzenie.
Zbieranie tych danych przez reprezentatywny okres ujawnia wzorce. Proces może wydawać się szybki średnio, ale pokazywać istotne szczyty podczas maksymalnych obciążeń. Te szczyty często są miejscem, gdzie ukrywa się węzeł zakłóceń. 📉
3. Analizuj przejścia danych
Zbadaj połączenia między procesami. Szukaj przepływów danych, które rozgałęziają się na wiele ścieżek lub łączą się z wielu źródeł. Punkty łączenia często powodują konflikty. Jeśli trzy strumienie zasilają jeden procesor, ten procesor musi obsłużyć łączne obciążenie. Jeśli pojemność nie jest odpowiednio skalowana, powstaje kolejka zadań.
Podobnie sprawdź obecność pętli. Dane, które cyklicznie powracają przez ten sam proces, wskazują na ponowne przetwarzanie lub obsługę błędów. Nadmierne zapętlanie zużywa zasoby bez dodania wartości. Śledź te pętle, aby określić, czy są konieczne, czy wynikają z złego projektu. 🔄
4. Skoreluj z wykorzystaniem zasobów
Zmapuj metryki przepływu danych względem zasobów systemu. Wysoki objętość przepływu danych powinien korelować z wysokim wykorzystaniem zasobów. Jeśli konkretny przepływ danych pokazuje wysokie opóźnienie, ale niskie wykorzystanie zasobów w innych miejscach, problem może dotyczyć tylko tej ścieżki. Z kolei jeśli wszystkie procesy jednocześnie spowalniają, problem może być systemowy, np. blokada wspólnych baz danych lub przeciążenie sieci.
Użyj narzędzi monitoringu, aby śledzić zużycie zasobów wraz z przepływem. Ta korelacja pomaga rozróżnić między węzłem logicznym (złym projektem) a fizycznym (ograniczeniami sprzętowymi). ⚖️
Ilościowe określanie wpływu ograniczeń 📊
Po identyfikacji potencjalnego węzła zakłóceń jego wpływ musi zostać ilościowo określony. Ten krok zapewnia, że zasoby są przydzielane do najważniejszych problemów. Nie wszystkie opóźnienia są równe. Opóźnienie w interfejsie użytkownika może być bardziej szkodliwe niż opóźnienie w generowaniu raportu w tle.
Oblicz koszt opóźnienia. Obejmuje to szacowanie czasu straconego na transakcję i pomnożenie go przez liczbę transakcji. Na przykład, jeśli proces trwa dodatkowe 100 milisekund i obsługuje 10 000 transakcji na godzinę, całkowity stracony czas jest istotny. Jeśli to opóźnienie wpływa na doświadczenie użytkownika, koszt dla biznesu jest jeszcze wyższy.
Zważ efekt kaskadowy. Opóźnienie na początku potoku może się rozprzestrzeniać w dół. Jeśli pierwszy krok jest opóźniony, wszystkie kolejne kroki są przesunięte. To zwiększa całkowity wpływ. Identyfikacja przyczyny pierwotnej zapobiega leczeniu objawów. Naprawienie pierwszego kroku często automatycznie rozwiązuje opóźnienia w kolejnych krokach. 🌊
Strategie optymalizacji 🛠️
Po identyfikacji i ilościowym określeniu węzłów zakłóceń skupienie się przesuwa na optymalizację. Strategia zależy od natury ograniczenia. Istnieją trzy główne mechanizmy: równoległość, grupowanie i uproszczenie.
Równoległość
Jeśli proces jest ograniczony obliczeniowo, podział pracy na wiele zasobów może zwiększyć przepustowość. Jest to często stosowane w przypadku niezależnych zadań. Jeśli przepływ danych pozwala na podział, rozdziel obciążenie. Upewnij się, że narzut synchronizacji nie anuluje zysków. Równoległość działa najlepiej, gdy zadania nie zależą od natychmiastowego wyniku jednego z nich. 🚀
Grupowanie
Jeśli ograniczenie dotyczy wejścia/wyjścia lub opóźnienia sieciowego, przetwarzanie danych w partii może być bardziej efektywne niż przetwarzanie pojedynczych elementów. Zmniejsza to narzut otwierania i zamykania połączeń. Jednak grupowanie wprowadza opóźnienie dla pojedynczych elementów. Zrównowaguj zysk w przepustowości z akceptowalnym opóźnieniem dla użytkownika końcowego. 📦
Uproszczenie
Często najskuteczniejszą optymalizacją jest usunięcie niepotrzebnych kroków. Przejrzyj przepływ danych pod kątem nadmiarowych przekształceń. Jeśli dane są konwertowane z jednego formatu na inny i następnie z powrotem, krok pośredni może zostać usunięty. Uprość logikę, aby zmniejszyć czas przetwarzania. Każdy dodany krok w przepływie wprowadza potencjalne punkty awarii i opóźnienia. ✂️
Ciągła kontrola i iteracja 🔄
Optymalizacja to nie cel końcowy. Systemy się rozwijają, a nowe węzły zatyczki pojawiają się wraz ze zmianami wzorców ruchu. Po zakończeniu analizy początkowej i wdrożeniu poprawek cykl zaczyna się od nowa. Ustanów rutynę przeglądu przepływów danych.
Skonfiguruj ostrzeżenia dla metryk zdefiniowanych wcześniej. Jeśli przepustowość spadnie lub opóźnienia wzrosną, wywołaj dochodzenie. Zachowuj dokumentację schematów przepływu danych (DFD). W miarę wprowadzania zmian w systemie aktualizuj diagramy. Ustarelełe mapy prowadzą do błędnych założeń i marnowania wysiłku. 📝
Wspieraj kulturę ciągłego doskonalenia. Zespoły powinny mieć możliwość zgłaszania nieefektywności, które napotykają w codziennej pracy. Użytkownicy z linii frontu często zauważają węzły zatyczki, które pomijają metryki najwyższego poziomu. Ich opinie są nieocenione przy weryfikacji analizy. 👥
Studium przypadku: Optymalizacja ogólnego przepływu pracy 🏭
Rozważ sytuację, w której system przetwarzania zamówień doświadczał opóźnień w godzinach szczytowych. Początkowa analiza wykazała, że krok weryfikacji zamówienia trwa zbyt długo. Schemat przepływu danych (DFD) ujawnił, że weryfikacja wymagała trzech oddzielnych sprawdzeń wobec różnych systemów zewnętrznych.
Analizując przepływ, zespół zrozumiał, że te sprawdzenia odbywały się sekwencyjnie. Zmiana projektu tak, by sprawdzenia odbywały się równolegle, zmniejszyła całkowity czas weryfikacji o 60%. Schemat przepływu danych został zaktualizowany w celu odzwierciedlenia tej nowej struktury. Monitorowanie potwierdziło, że kolejka została opróżniona szybciej, a system bez interwencji poradził sobie z obciążeniem szczytowym. Ten przykład pokazuje, jak zmiany strukturalne w przepływie dają natychmiastowe rezultaty. ✅
Najlepsze praktyki dla zrównoważonej efektywności 🌱
Aby utrzymać zdrowy system, przestrzegaj tych zasad:
- Utrzymuj diagramy aktualne: Ustareleła mapa jest gorsza niż żadna mapa.
- Skup się na przepływie, a nie tylko na funkcjonalności: Upewnij się, że dane płyną płynnie, a nie tylko że funkcje działają.
- Mierz wszystko: Jeśli nie jest mierzone, nie może być poprawione.
- Przeglądaj regularnie: Zaprojektuj okresowe audyty architektury danych.
- Dokumentuj założenia: Zapisz, dlaczego pewne przepływy zostały zaprojektowane w określony sposób, aby wspomóc przyszłe rozwiązywanie problemów.
Traktując przepływ danych jako kluczowy aktyw, organizacje mogą zapewnić, że ich systemy pozostają reaktywne i niezawodne. Proces identyfikowania węzłów zatyczek nie polega na znajdowaniu wad, ale na głębokim zrozumieniu systemu. To zrozumienie prowadzi do odporności i wydajności. 🛡️
Ostateczne rozważania na temat integralności przepływu danych 🧩
Efektywność w każdym systemie opiera się na płynnym przepływie informacji. Gdy dane napotykają opór, cała operacja zwalnia. Analiza przepływu danych oferuje jasne spojrzenie na miejsca, gdzie ten opór występuje. Poprzez mapowanie, pomiar i modyfikację przepływu zespoły mogą usunąć tarcie i poprawić wydajność.
Techniki opisane tutaj tworzą ramy dla zrównoważonej optymalizacji. Wymagają dyscypliny i uwagi na szczegóły, ale nagroda to system, który działa spójnie pod presją. W miarę wzrostu objętości danych zdolność do zarządzania przepływem staje się coraz ważniejsza. Opanowanie tej dyscypliny zapewnia długowieczność i niezawodność architektury. 🏆