











複雑なシステムをモデル化する際、明確さが最も重要な目的です。データフローダイアグラム(DFD)は、情報がシステム内でどのように移動するかを可視化する基盤となるツールです。この枠組みの中で、二つの記号が主導的です:プロセス と データストア。これらは頻繁に相互作用しますが、変換と永続性に関する根本的に異なる概念を表しています。この違いを理解することは、正確なシステム分析と設計にとって不可欠です。
このガイドでは、これらの要素の機能的役割、視覚的表現、論理的含意について探求します。行動と保存の違いを明確にすることで、分析者は曖昧さなくシステムの動作を伝える図を構築できます。
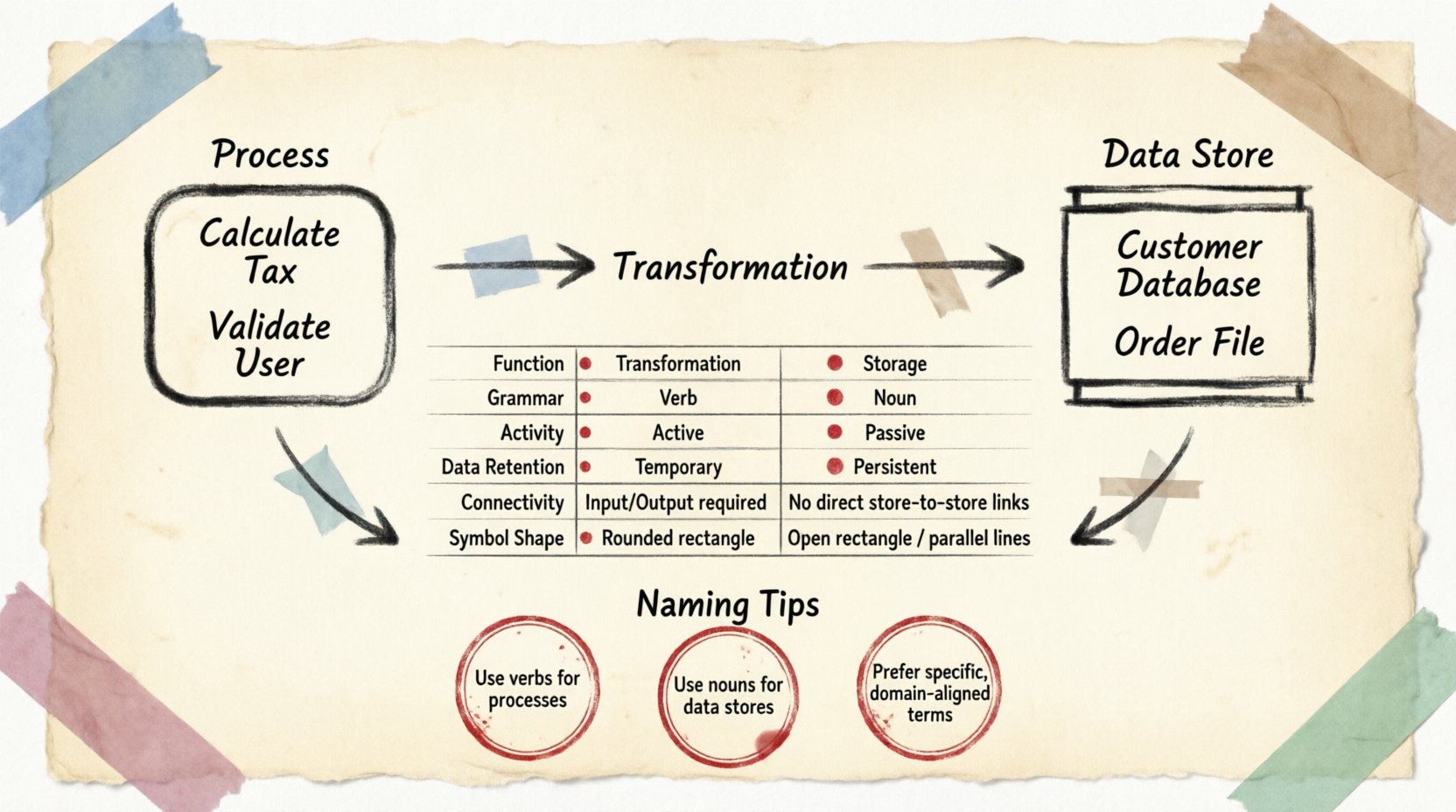
🔄 プロセスの定義
プロセスは作業単位または変換を表します。データが形を変える、計算される、またはフィルタリングされる場所です。プロセスをブラックボックスと考えてください。入力と出力はわかっていますが、内部のメカニズムはその情報の保存ではなく、変換ロジックそのものによって定義されます。
🔹 核心的な特徴
- 変換: 主な機能はデータを変更することです。入力データが入力され、ルールや論理が適用され、出力データが生成されます。
- 時間的性質: プロセスはトリガーされたときだけ活性化されます。実行の間にはデータを保持しません。
- 方向性: データはプロセスに入り、出ていきます。入力も出力もないプロセスは、DFDの文脈では論理的に無効です。
- 動詞による命名: プロセスは通常、動詞または動詞句でラベル付けされます(例:税金を計算, ユーザーを検証, レポートを生成).
🔹 ブラックボックス概念
高レベルのモデル化では、プロセスはブラックボックスです。注目すべきは「何がデータに対して何が起こるか」であり、「どのように技術的に起こるか」ではありません。たとえば、「注文を処理」という名前のプロセスは注文の詳細を受け取り、取引記録を作成します。計算がメモリ上で行われるか、ディスク上か、リモートAPI経由かは指定しません。この抽象化により、ステークホルダーは技術的実装ではなくビジネスロジックに注目できます。
しかし、図がより低いレベルに分解されるにつれて、内部ロジックはより詳細になります。それでもプロセスはアクティブな変換エンジンのままです。入力を消費し、作業を行い、出力を生成します。その情報の保管庫として機能するわけではありません。
🗄️ データストアの定義
データストアは、情報が保管されるリポジトリを表します。プロセスとは異なり、データストアはデータを変換しません。待機します。プロセスがデータを取得するか、プロセスがデータをそこに配置するまで、データを永続的な状態で保持します。
🔹 コア特性
- 永続性: プロセスがアクティブでないときでさえ、データはストアに残ります。これはメモリバッファや一時変数との主要な違いです。
- 受動的性質: データストアは行動を開始しません。読み取りまたは書き込みを行うにはプロセスが必要です。
- 名詞による命名: ストアは通常、名詞(例:顧客データベース, 注文ファイル, 在庫ログ).
- 開放的: データフローはストアに入り出し可能です。しかし、ストアは他のストアに直接接続できません。データはリポジトリ間を移動する際、プロセスを経由しなければなりません。
🔹 リポジトリの概念
図書館を想像してください。本がデータです。本棚がデータストアです。司書がプロセスです。司書は本を作りません。本を整理するだけです。本棚は本を自分で動かすわけではなく、本を固定して保持します。利用者が本を要求すると、司書がそれを取り出します(読み取り操作)。新しい本が届くと、司書が本を本棚に置きます(書き込み操作)。
システムアーキテクチャにおいて、データストアはデータベーステーブル、フラットファイル、キュー、またはクラウドバケットを表すことがあります。DFDの記号は技術を抽象化しています。SQLテーブルであろうと単純なテキストファイルであろうと、論理的な役割は同じです:情報が保管される場所です。
⚡ 連携とデータフロー
プロセスとデータストアの関係は、厳密なデータフローのルールによって支配されています。DFDにおける矢印はデータの移動を表します。これらの矢印が情報転送の方向を規定します。
🔹 読み書きサイクル
プロセスが情報が必要な場合、データストアからプロセスへ矢印を引きます。これは読み取り操作を示します。プロセスは変換ロジックに使用するため、データを抽出します。逆に、プロセスが新しい情報を生成する際は、プロセスからデータストアへ矢印を引きます。これは書き込み操作を示します。データは今後使用するために保存されます。
重要な点として、データフローは二つのデータストアを直接接続できません。処理されない限り、情報は一つのリポジトリから別のリポジトリへ移行できません。このルールは、データの移動が常に何らかの論理または制御を伴うことを強調しています。たとえそれが単純なコピー操作であってもです。
🔹 外部エントリ
外部エントリ(ソースまたはシンク)はプロセスとやり取りしますが、直接データストアとやり取りしません。外部エントリは人間のユーザー、サードパーティAPI、または他のシステムである可能性があります。彼らはデータをプロセスに送信するか、プロセスからデータを受け取ります。その後、プロセスはそのデータをリポジトリに保存するか、破棄するかを決定します。
📋 比較表
構造上の違いを要約するために、以下の属性の分解を検討してください。
| 属性 | プロセス | データストア |
|---|---|---|
| 機能 | 変換/アクション | ストレージ/メモリ |
| 文法 | 動詞(例:更新) | 名詞(例:ユーザー表) |
| アクティビティ | アクティブ(トリガー時に実行) | パッシブ(アクセスされるまで待機) |
| データ保持 | 一時的(実行中) | 永続的(長期) |
| 接続性 | エンティティ、ストア、他のプロセスに接続 | プロセスのみに接続 |
| 記号の形状 | 丸みを帯びた長方形または円 | 開かれた長方形または平行線 |
🧩 名前付け規則
名前の一貫性は、レビューおよび実装フェーズでの混乱を防ぎます。同じ用語をストレージとアクションの両方に使用すると、しばしば曖昧さが生じます。
🔹 プロセス名の付け方
名前は、データに対して実行されるアクションを説明するものにすべきです。”やる”や”処理する”のような一般的な名前は避け、具体的な記述を使用してください。たとえば、「ログイン資格情報を検証する」は「ログインを確認する」よりも優れています。この明確さにより、開発者は入力および出力の要件を即座に理解できます。
🔹 データストアの名前付け
名前は、格納されている内容を反映するべきです。複数形の名詞または明確な識別子を使用してください。「Orders」は注文レコードのコレクションを意味します。「Order」は単一の取引インスタンスを意味する可能性があります。文脈は重要ですが、複数形の名詞は一般的に複数のレコードを含むリポジトリを示します。
データストアの名前を付ける際には、範囲を考慮してください。「Database」という名前はあまりに曖昧です。「Customer Database」や「Transaction Log」は必要な文脈を提供します。この詳細さは、後で図を物理的なストレージ構造にマッピングするのを助けます。
🧪 分解とレベル
DFDは階層的です。高レベルの図(コンテキスト図)では、システムが単一のプロセスとして表示されます。これを低レベルに分解していくと、プロセスとストアの違いがより重要になります。
🔹 レベル0 vs. レベル1
コンテキスト図では、システム全体が一つのプロセスとして表示されます。レベル0では、このプロセスが主要なサブプロセスに分解されます。データストアは、主要なデータコンポーネントがどこに存在するかを示すためにここに導入されます。レベル1以降では、プロセスがさらに精査されます。
分解の過程で、データストアが不要に重複しないようにしてください。レベル0に存在するストアは、特定のサブプロセスが一時的なキャッシュを必要とする場合を除き、レベル1まで通常は維持されるべきです(その場合は別のストアになります)。レベル間での一貫性はトレーサビリティを確保します。
🔹 バランス
分解における重要なルールが「バランス」です。親プロセスの入力と出力は、低レベルの図における子プロセスの入力と出力と一致している必要があります。データストアも同様に整合性を保つ必要があります。親図にストアが存在する場合、子図はそのデータフローを正しく扱わなければなりません。プロセスが分割された場合、ストアへのデータフローは分割の両側で維持されなければなりません。
⚠️ 避けるべき論理的誤り
構造上の誤りが図を無効にする可能性があります。これらの誤りを早期に認識することで、開発フェーズでの時間を節約できます。
- ゴーストデータフロー:入力データフローのないプロセスから矢印が出るというのは不可能です。プロセスは何もない状態から出力を生成できません。すべての出力は、入力または保存されたデータから導かれる必要があります。
- ストア同士の直接接続:前述したように、ストアは他のストアに直接接続できません。データはプロセスを経由しなければなりません。これにより、すべてのデータ移動が意図的であり、処理されることを保証します。
- 接続されていないプロセス:入力も出力も持たないプロセスは孤立しています。システムとやり取りせず、DFDにおいて何の役割も果たしません。
- エンティティとストアの混同:外部エンティティはシステム境界の外にあります。データストアは境界の内側にあります。外部エンティティの記号を、まるでデータベースであるかのようにシステム境界内に配置してはいけません。
🛠️ 実装上の影響
プロセスとストアの違いは、システムの構築方法に影響を与えます。プロセスは関数、メソッド、またはマイクロサービスに対応します。データストアはテーブル、ファイル、またはオブジェクトストレージに対応します。
🔹 データベース設計
データベースを設計する際、DFD内のデータストアがスキーマのブループリントになります。データフロー矢印内の属性がカラムを定義します。ストア間の関係(プロセスを介して媒介される)が外部キーまたはトランザクションリンクを定義します。
🔹 ワークフロー自動化
ワークフローエンジンでは、プロセスがパイプライン内のステップを表します。データストアはワークフローの状態を表します。プロセスはストア内の状態を更新して、タスクが完了したことをマークするかもしれません。ストアの受動的な性質を理解することで、ワークフローエンジンが次のステップに進む前に正しい状態を待つことが保証されます。
🔍 視覚的表現の基準
異なる手法ではわずかに異なる記号を使用しますが、論理は一貫しています。
- デマーコ&ヨードン:プロセスには丸みを帯びた長方形、データストアには開口部のある長方形を使用します。
- ゲイン&サーソン:プロセスには丸みを帯びた長方形、データストアには平行線を使用します。
選ばれた記法に関わらず、意味は同じです。プロセスは動作する。ストアは保持する。チームが選択した規約を理解していれば、プロジェクト文書内の一貫性が、特定の標準に従うよりも重要です。
🎯 役割の要約
堅牢なシステムモデルを構築するには、役割の割り当てに厳密さが必要です。プロセスはアクターです。作業を実行します。データストアは舞台です。道具を保持します。アクターがいなければ、舞台は空です。舞台がなければ、アクターは自分の成果を置く場所がありません。
変換と保存の明確な分離を維持することで、分析者は視覚的に魅力的であるだけでなく論理的に整合性のある図を構築できます。これらの図は、ビジネス関係者と技術チームとの間の契約として機能します。責任の範囲と価値の流れを定義します。
DFDをレビューする際には、すべての記号に対して2つの質問を投げかけましょう。「この記号は作業を行っていますか?」(プロセス)または「この記号は情報を保持していますか?」(ストア)。答えが不明瞭な場合は、ラベルや接続を改善してください。明確さこそがシステムモデリングの最終的な目標です。
これらの原則に従うことで、保守性、拡張性、理解しやすさを備えたアーキテクチャが得られます。違いは単純ですが、システムの整合性に対する影響は非常に大きいです。