










Une conception efficace des systèmes commence par la compréhension du déplacement des données au sein d’une organisation. Lorsque les équipes tentent de développer des logiciels complexes sans carte claire, elles rencontrent souvent un décalage entre les besoins métiers et l’exécution technique. La modélisation des systèmes d’information offre une approche structurée pour visualiser ces interactions. Au cœur de cette pratique se trouve le diagramme de flux de données, un outil puissant pour documenter la manière dont les informations sont traitées, stockées et transmises.
Cet article explore les principes de la modélisation des systèmes d’information à travers le prisme des diagrammes de flux de données (DFD). Nous examinerons les composants, les niveaux d’abstraction et les techniques analytiques nécessaires à la création de modèles de systèmes robustes. En se concentrant sur la logique du déplacement des données plutôt que sur la mise en œuvre physique, les analystes peuvent garantir clarté et précision avant même qu’un seul code ne soit écrit.
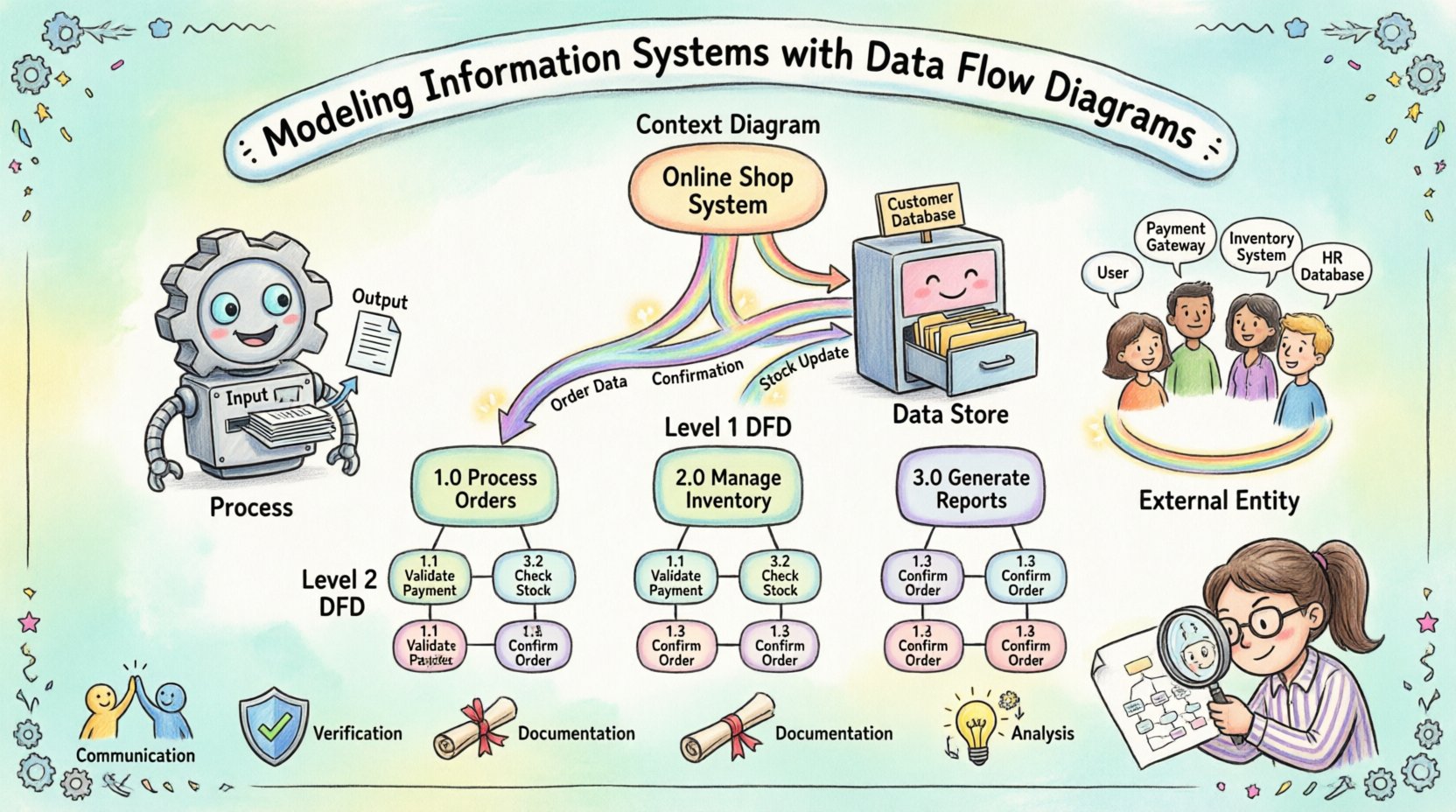
Comprendre le but de la modélisation des systèmes 🧩
Avant de plonger dans des symboles spécifiques, il est essentiel de comprendre pourquoi nous modélisons les systèmes. Un système d’information est bien plus qu’une base de données ou une interface utilisateur ; c’est un réseau de processus qui transforme les entrées en sorties utiles. La modélisation permet aux parties prenantes de voir le tableau global sans se perdre dans les détails techniques.
- Communication :Les diagrammes visuels comblent le fossé entre les équipes techniques et les utilisateurs métiers. Tout le monde peut voir le même flux d’information.
- Vérification :Les modèles aident à vérifier que toutes les exigences métiers sont prises en compte avant le début du développement.
- Documentation :Ils servent de registre durable sur le fonctionnement du système, utile pour la maintenance future et la formation.
- Analyse :Les diagrammes révèlent les points de congestion, les processus redondants et les failles potentielles en matière de gestion des données.
Quand vous modélisez un système d’information, vous créez essentiellement un plan. Tout comme un architecte ne construit pas une maison sans plan, un architecte système ne devrait pas écrire de logique sans carte. Cette approche réduit les reprises et garantit que le produit final s’aligne avec les objectifs organisationnels.
Les composants fondamentaux d’un diagramme de flux de données 🏗️
Un diagramme de flux de données repose sur quatre éléments principaux pour représenter le système. Chaque élément a un rôle spécifique et une représentation visuelle. Comprendre ces éléments de base est la première étape vers la création d’un modèle valide.
1. Processus ⚙️
Les processus représentent des actions qui transforment les données. Ce sont les moteurs du système. Un processus prend des données d’entrée, effectue une opération, puis produit des données de sortie. Dans un diagramme, un processus est souvent représenté par un cercle ou un rectangle arrondi. Il doit avoir un nom qui décrit l’action, par exemple « Calculer la taxe » ou « Valider la connexion ».
Chaque processus doit avoir au moins une entrée et une sortie. Un processus ne peut pas exister simplement sans transformer des données. Si des données entrent dans un processus mais rien ne sort, le modèle est incomplet. Si des données sortent sans entrer, la sortie n’est pas expliquée. Ce principe de conservation garantit une cohérence logique.
2. Stockages de données 🗄️
Les stockages de données représentent des emplacements où les informations sont conservées pour une utilisation ultérieure. Ce peuvent être des bases de données physiques, des fichiers, voire des classeurs physiques. Dans un DFD, un stockage de données est généralement représenté par un rectangle ouvert ou deux lignes parallèles. Contrairement aux processus, les stockages de données ne transforment pas les données ; ils les conservent.
Il est crucial de distinguer un processus d’un stockage de données. Un processus modifie l’état des données, tandis qu’un stockage de données les préserve. Les connexions entre les processus et les stockages de données indiquent que des données sont lues ou écrites dans le stockage. Cette distinction aide à clarifier si les informations sont activement traitées ou simplement archivées.
3. Entités externes 👥
Les entités externes sont des sources ou des destinations de données situées en dehors de la frontière du système. Elles interagissent avec le système mais ne font pas partie de la logique interne. Des exemples incluent les clients, les fournisseurs, les organismes régulateurs ou d’autres systèmes. Dans les diagrammes, ces entités sont souvent représentées par des carrés ou des rectangles.
Lors de la modélisation, définissez clairement le périmètre. Qu’est-ce qui est à l’intérieur du système et qu’est-ce qui est à l’extérieur ? Une entité externe est tout ce que vous ne pouvez pas contrôler ou modifier directement dans le cadre du modèle actuel. Cela aide à concentrer l’analyse sur les limites de responsabilité.
4. Flux de données 🔄
Les flux de données montrent le déplacement de l’information entre les processus, les stockages et les entités. Ils sont représentés par des flèches. Chaque flèche doit avoir une étiquette décrivant les données en cours de déplacement, par exemple « Détails de la commande » ou « Reçu de paiement ».
Les flux de données ne représentent pas les signaux de contrôle ou les délais. Ils représentent la charge utile réelle des informations. Un flux peut se diviser ou se fusionner, mais il doit toujours transporter des données significatives. Les flèches ne doivent pas se croiser inutilement pour préserver la lisibilité. Si un flux relie deux processus, cela indique un transfert direct d’information.
Niveaux d’abstraction et décomposition 🔍
Les systèmes complexes ne peuvent pas être compris en une seule vue. Pour gérer la complexité, les analystes utilisent la décomposition, en divisant le système en couches gérables. Cette approche hiérarchique permet des niveaux de détail différents selon le public et l’objectif.
Diagramme de contexte (Niveau 0)
Le diagramme de contexte fournit le plus haut niveau d’abstraction. Il représente l’ensemble du système comme un seul processus et identifie toutes les entités externes interagissant avec lui. Cette vue répond à la question : « Qu’est-ce que le système ? » Elle définit clairement les limites.
Dans ce diagramme, vous ne voyez ni les processus internes ni les stockages de données. Vous ne voyez que la frontière du système et le flux d’information entrant et sortant. Ce diagramme est souvent le premier créé pour obtenir l’accord des parties prenantes sur le périmètre.
Diagramme de niveau 1
Le diagramme de niveau 1 étend le processus unique du diagramme de contexte en sous-processus majeurs. Il révèle les principales zones fonctionnelles du système. Par exemple, un processus « Gérer une commande » peut être décomposé en « Recevoir une commande », « Vérifier le stock » et « Traiter le paiement ».
Ce niveau introduit les stockages de données et montre comment les données circulent entre les fonctions principales. Il est suffisamment détaillé pour que les équipes techniques comprennent l’architecture, mais assez abstrait pour éviter de s’enfoncer dans des logiques spécifiques.
Niveau 2 et au-delà
La décomposition continue jusqu’à ce que chaque processus soit suffisamment simple pour être compris sans décomposition supplémentaire. C’est souvent à ce stade que les règles métier spécifiques sont documentées. À ce niveau, le diagramme sert de référence directe aux développeurs qui écrivent du code.
La décomposition doit être équilibrée. Les entrées et sorties d’un processus parent doivent correspondre aux entrées et sorties de ses processus enfants. Si un processus se divise en trois enfants, les données entrant dans le processus parent doivent encore entrer collectivement dans les enfants, et les données sortant des enfants doivent sortir du processus parent.
Normes de notation et cohérence 📏
Bien que les concepts des diagrammes en flux de données soient universels, les symboles utilisés peuvent varier. Deux notations principales existent dans l’industrie. Choisir l’une d’elles et s’y tenir est essentiel pour assurer la clarté.
| Fonctionnalité | Yourdon & DeMarco | Gane & Sarson |
|---|---|---|
| Processus | Cercle ou rectangle arrondi | Rectangle arrondi |
| Entrepôt de données | Rectangle ouvert | Rectangle ouvert (avec ligne épaisse) |
| Entité externe | Rectangle | Rectangle |
| Flux de données | Flèche courbée ou droite | Flèche droite |
La cohérence empêche la confusion. Si une équipe change de notation au milieu d’un projet, la documentation devient fragmentée. Il est préférable d’établir une norme dès le début et de la documenter dans un guide de style.
En outre, les conventions de nommage doivent être cohérentes. Utilisez des verbes pour les processus (par exemple, « Mettre à jour un enregistrement ») et des noms pour les flux de données (par exemple, « Données d’enregistrement »). Cette distinction grammaticale aide les lecteurs à identifier rapidement la fonction de chaque élément.
Analyse du système pour l’amélioration 🛠️
Créer un diagramme ne consiste pas seulement à documenter ; c’est aussi une analyse. Une fois le modèle établi, vous pouvez l’interroger pour repérer des inefficacités ou des risques.
Identification des goulets d’étranglement
Recherchez les processus qui reçoivent plusieurs entrées mais produisent une seule sortie. Ces zones deviennent souvent des goulets d’étranglement où le travail s’accumule. Un fort volume de flux entre deux points spécifiques peut indiquer la nécessité d’une optimisation ou d’un traitement parallèle.
Vérification de l’intégrité des données
Examinez la manière dont les données sont stockées et récupérées. Les flux de données sensibles sont-ils chiffrés dans le modèle ? Les entrepôts de données sont-ils validés avant écriture ? Un système bien modélisé garantit la qualité des données à chaque étape. Si les données circulent directement vers un entrepôt sans validation, le modèle révèle un risque potentiel.
Élimination de la redondance
Voyez-vous le même processus répété à différentes parties du diagramme ? Cela suggère une redondance. Vous pourriez être en mesure de regrouper les fonctions dans un seul service. Réduire la duplication permet d’économiser des ressources et de simplifier la maintenance.
Validation de la complétude
Assurez-vous que chaque entité externe a un flux correspondant. Si un client existe mais qu’aucun flux de données ne va vers lui ni ne vient de lui, le modèle est incomplet. De même, vérifiez que chaque entrepôt de données a un écrivain et un lecteur. Un entrepôt de données orphelin suggère un stockage inutilisé.
Meilleures pratiques pour la maintenance et l’évolution 🌱
Les systèmes d’information ne sont pas statiques. Ils évoluent au fur et à mesure que les besoins métiers changent. Un modèle exact aujourd’hui peut devenir obsolète demain. Il est donc aussi important de maintenir la documentation que de la créer.
Contrôle de version
Suivez les modifications apportées aux diagrammes. Les numéros de version ou les dates doivent être visibles. Cela aide les équipes à comprendre ce qui a changé et pourquoi. Cela permet également de revenir en arrière si un nouveau design s’avère problématique.
Revue par les parties prenantes
Revoyez régulièrement les modèles avec les utilisateurs métiers. Ils sont la meilleure source de vérité quant à la correspondance du système avec leur flux de travail. Si un processus ne correspond pas à la réalité, le modèle est erroné, peu importe à quel point il semble logique.
Intégration avec d’autres modèles
Les diagrammes de flux de données (DFD) n’existent pas en isolation. Ils sont souvent liés aux diagrammes Entité-Relation (ERD) pour la structure des données et aux diagrammes de transition d’état pour le comportement du système. Assurer l’alignement de ces modèles évite les contradictions entre la logique des processus et la structure des données.
Le rôle de l’analyste 🧑💼
Le succès de la modélisation dépend largement de l’analyste. Il doit agir comme un traducteur entre le langage métier et la logique technique. Cela exige de solides compétences en communication et une compréhension approfondie du domaine.
Un analyste efficace pose des questions pertinentes. « D’où provient cette donnée ? » « Que se passe-t-il si cette entrée est manquante ? » « Qui est responsable de cette mise à jour ? » Ces questions révèlent des exigences cachées que les parties prenantes pourraient négliger.
La patience est également essentielle. La modélisation est itérative. Les diagrammes initiaux seront probablement erronés ou incomplets. L’objectif est de les affiner grâce aux retours. N’ayez pas peur de rejeter un diagramme s’il ne fonctionne pas ; utilisez les leçons apprises pour en construire un meilleur.
Conclusion et réflexions finales 🚀
La modélisation des systèmes d’information à l’aide de diagrammes de flux de données est une compétence fondamentale pour toute personne impliquée dans la conception de systèmes. Elle fournit un langage clair et visuel pour discuter des processus complexes. En se concentrant sur le déplacement des données plutôt que sur les détails d’implémentation, les équipes peuvent assurer une cohérence et réduire les erreurs.
Le parcours allant d’un diagramme de contexte simple à un modèle détaillé de niveau 2 exige de la discipline et une attention aux détails. Toutefois, le gain est un système plus facile à comprendre, à maintenir et à améliorer. Alors que les organisations continuent de s’appuyer sur des solutions numériques, la capacité à cartographier leur logique reste un atout essentiel.
Commencez par les bases. Définissez vos limites. Décomposez vos processus. Revoyez votre travail. Avec de la pratique, la création de ces modèles deviendra naturelle, conduisant à des systèmes d’information plus robustes et plus efficaces.