











Dans les systèmes complexes, l’efficacité n’est pas toujours évidente avant qu’un ralentissement ne se produise. Lorsque les processus s’arrêtent, les données sont en retard ou le débit diminue, le problème sous-jacent réside souvent dans le déplacement de l’information plutôt que dans le stockage ou le traitement lui-même. L’analyse du flux de données fournit une méthode structurée pour visualiser le mouvement de l’information à travers un système, ce qui facilite la détection des points de friction. En cartographiant ces flux, les équipes peuvent identifier précisément les endroits où la capacité est dépassée ou où des délais inutiles s’accumulent. 🧭
Cette approche nécessite une compréhension claire de l’architecture du système sans dépendre d’outils propriétaires. L’objectif est d’établir un cadre logique qui révèle les inefficacités. Que l’on gère une chaîne logicielle, une ligne de production ou un flux administratif, les principes restent les mêmes. Identifier ces contraintes permet des interventions ciblées qui entraînent des améliorations mesurables en vitesse et en fiabilité. ⚙️
Comprendre les fondements des diagrammes de flux de données 🗺️
Avant de localiser un goulet d’étranglement, il faut comprendre la carte. Un diagramme de flux de données (DFD) est une représentation graphique du flux de données à travers un système d’information. Il se concentre sur l’origine des données, leur destination et leur transformation. Contrairement aux organigrammes qui représentent la logique de contrôle, les DFD mettent l’accent sur le déplacement et la transformation des éléments de données.
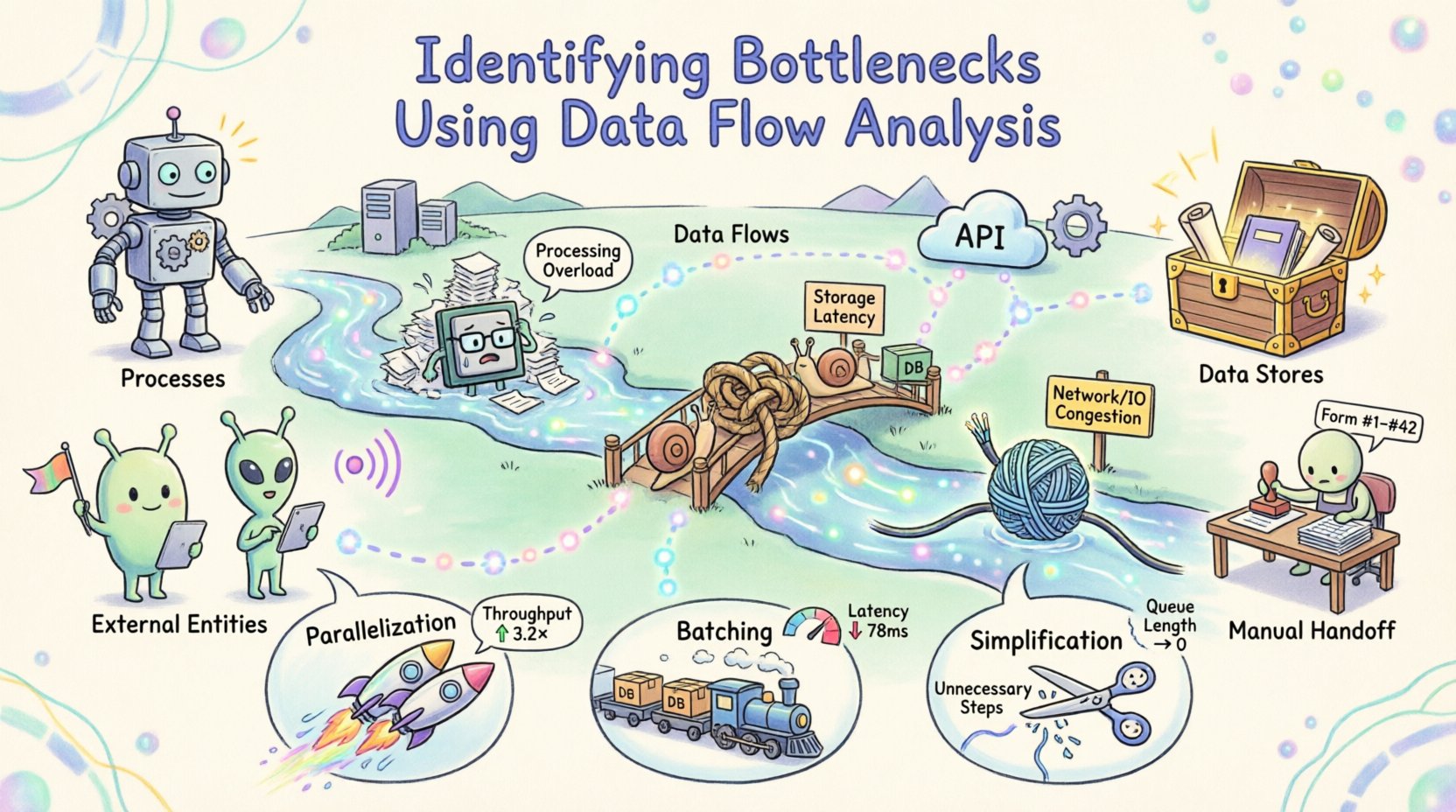
Il existe quatre composants principaux dans un DFD standard :
- Traitements :Transformations qui convertissent les données d’entrée en données de sortie. Ils sont souvent représentés par des cercles ou des rectangles arrondis.
- Stockages de données :Emplacements où les données sont conservées pour une utilisation ultérieure, tels que des bases de données ou des fichiers.
- Entités externes :Sources ou destinations situées en dehors de la frontière du système, telles que des utilisateurs ou d’autres systèmes.
- Flux de données :Les chemins suivis par les données entre les composants.
La création d’un diagramme de haut niveau établit le périmètre. Un diagramme de niveau inférieur permet ensuite d’approfondir des processus spécifiques. Cette hiérarchie permet aux analystes d’examiner le système à différentes granularités. Si un retard se produit au niveau macro, le zoom en détail révèle le processus ou le transfert spécifique à l’origine du retard. 🔍
L’anatomie d’un goulet d’étranglement système 🚦
Un goulet d’étranglement est tout point d’un système où le flux de données est restreint, entraînant un retard ou un embouteillage. Dans le cadre de l’analyse du flux de données, les goulets d’étranglement se manifestent de plusieurs façons distinctes. Reconnaître le type de contrainte est la première étape vers une résolution.
| Type de goulet d’étranglement | Description | Symptômes typiques |
|---|---|---|
| Traitement | Le traitement ou la logique prend plus de temps que le flux de données entrant ne peut le supporter. | Les files d’attente s’accumulent avant le traitement ; les pics d’utilisation du CPU ou de la mémoire sont élevés. |
| Stockage | La lecture ou l’écriture des données dans une base de données ou un système de fichiers est lente. | La latence augmente lors de la récupération des données ; les temps de transaction varient considérablement. |
| Réseau/E/S | La vitesse de transfert entre les composants est limitée par la bande passante ou la latence. | Des timeouts se produisent ; les transferts de grandes quantités de données s’interrompent fréquemment. |
| Humain | Une intervention manuelle est requise là où une automatisation devrait exister. | Les tâches attendent une validation ; des erreurs surviennent à cause de la fatigue ou de la complexité. |
Comprendre ces catégories aide à prioriser les corrections. Une limitation réseau pourrait nécessiter des modifications d’infrastructure, tandis qu’une limitation de traitement pourrait nécessiter une optimisation algorithmique. Sans cette distinction, les efforts pourraient être mal orientés vers des zones qui n’entravent pas le système. 🛠️
Méthodologie d’identification 🔎
Identifier les goulets d’étranglement n’est pas une action ponctuelle, mais une investigation systématique. Les étapes suivantes décrivent une approche solide pour analyser les flux de données et localiser les contraintes.
1. Cartographier l’état actuel
Commencez par documenter l’architecture existante. Ne comptez pas sur la mémoire ou les hypothèses. Interviewez les parties prenantes et examinez la documentation pour capturer le flux réel d’information. Créez un diagramme de niveau 0 qui montre la frontière du système et les interactions externes. Ensuite, créez des diagrammes de niveau 1 qui décomposent les principaux processus. Assurez-vous que chaque flux de données a une entrée et une sortie définies.
2. Définir des métriques de mesure
Les cartes visuelles sont qualitatives. Pour identifier les goulets d’étranglement, vous avez besoin de données quantitatives. Sélectionnez des indicateurs clés de performance (KPI) pour chaque processus et chaque flux de données. Les métriques pertinentes incluent :
- Débit : La quantité de données traitées par unité de temps.
- Latence : Le temps nécessaire pour que les données voyagent de la source à la destination.
- Utilisation : Le pourcentage de temps pendant lequel une ressource est active.
- Longueur de la file d’attente : Le nombre d’éléments en attente de traitement.
Collecter ces données sur une période représentative révèle des motifs. Un processus peut sembler rapide en moyenne, mais afficher des pics importants pendant les pics de charge. Ces pics sont souvent là où le goulet d’étranglement se cache. 📉
3. Analyser les transitions de données
Examinez les connexions entre les processus. Recherchez les flux de données qui se divisent en plusieurs chemins ou qui se rejoignent à partir de plusieurs sources. Les points de fusion créent souvent des conflits. Si trois flux alimentent un seul processeur, ce dernier doit gérer la charge combinée. Si la capacité n’est pas ajustée en conséquence, une file d’attente se forme.
De même, vérifiez les boucles. Les données qui reviennent plusieurs fois dans un processus indiquent un travail redondant ou un traitement d’erreurs. Une boucle excessive consomme des ressources sans ajouter de valeur. Suivez ces boucles pour déterminer si elles sont nécessaires ou le résultat d’une mauvaise conception. 🔄
4. Corréler avec l’utilisation des ressources
Cartographiez les métriques de flux de données par rapport aux ressources du système. Un volume élevé de flux de données devrait être corrélé à une utilisation élevée des ressources. Si un flux de données spécifique affiche une latence élevée mais une faible utilisation des ressources ailleurs, le problème pourrait être spécifique à ce chemin. À l’inverse, si tous les processus ralentissent simultanément, le problème pourrait être systémique, comme un verrou partagé sur la base de données ou une congestion réseau.
Utilisez des outils de surveillance pour suivre la consommation des ressources en parallèle avec le flux. Cette corrélation aide à distinguer entre un goulet d’étranglement logique (mauvaise conception) et un goulet d’étranglement physique (limites matérielles). ⚖️
Quantifier l’impact des contraintes 📊
Une fois un goulet d’étranglement potentiel identifié, son impact doit être quantifié. Cette étape garantit que les ressources sont allouées aux problèmes les plus critiques. Tous les retards ne sont pas égaux. Un retard dans l’interface utilisateur peut être plus dommageable qu’un retard dans la génération d’un rapport en arrière-plan.
Calculez le coût du retard. Cela implique d’estimer le temps perdu par transaction et de le multiplier par le volume des transactions. Par exemple, si un processus prend 100 millisecondes supplémentaires et traite 10 000 transactions par heure, le temps perdu total est important. Si ce retard affecte l’expérience utilisateur, le coût pour l’entreprise est encore plus élevé.
Pensez à l’effet domino. Un retard au début d’un pipeline peut se propager en aval. Si la première étape est retardée, toutes les étapes suivantes sont repoussées. Cela amplifie l’impact total. Identifier la cause racine permet d’éviter de traiter les symptômes. Corriger la première étape résout souvent automatiquement les retards en aval. 🌊
Stratégies d’optimisation 🛠️
Une fois les goulets d’étranglement identifiés et quantifiés, l’attention se tourne vers l’optimisation. La stratégie dépend de la nature de la contrainte. Il existe trois leviers principaux : la parallélisation, le regroupement par lots et la simplification.
Parallélisation
Si un processus est limité par le calcul, diviser le travail entre plusieurs ressources peut augmenter le débit. Cela s’applique souvent aux tâches indépendantes. Si le flux de données le permet, répartissez la charge. Assurez-vous que le surcoût de synchronisation ne compense pas les gains. La parallélisation fonctionne le mieux lorsque les tâches ne dépendent pas de la sortie immédiate les unes des autres. 🚀
Regroupement par lots
Si la contrainte est liée à l’I/O ou à la latence réseau, le traitement des données par lots peut être plus efficace que le traitement d’éléments individuels. Cela réduit le surcoût lié à l’ouverture et à la fermeture des connexions. Toutefois, le regroupement par lots introduit une latence pour les éléments individuels. Équilibrez le gain de débit contre le délai acceptable pour l’utilisateur final. 📦
Simplification
Souvent, l’optimisation la plus efficace consiste à supprimer les étapes inutiles. Examinez le flux de données à la recherche de transformations redondantes. Si les données sont converties d’un format à un autre puis de nouveau au format initial, l’étape intermédiaire peut être supprimée. Simplifiez la logique pour réduire le temps de traitement. Chaque étape ajoutée à un flux introduit des points potentiels de défaillance et de retard. ✂️
Surveillance continue et itération 🔄
L’optimisation n’est pas une destination finale. Les systèmes évoluent, et de nouveaux goulets d’étranglement apparaissent au fur et à mesure que les modèles de trafic changent. Une fois l’analyse initiale terminée et les améliorations mises en œuvre, le cycle recommence. Établissez une routine de revue des flux de données.
Configurez des alertes pour les métriques définies précédemment. Si le débit diminue ou la latence augmente brusquement, déclenchez une enquête. Maintenez à jour la documentation des diagrammes de flux de données (DFD). À chaque modification du système, mettez à jour les diagrammes. Des cartes obsolètes entraînent des hypothèses erronées et des efforts perdus. 📝
Encouragez une culture d’amélioration continue. Les équipes doivent être autonomes pour signaler les inefficacités qu’elles rencontrent au quotidien. Les utilisateurs sur le terrain voient souvent des goulets d’étranglement que les métriques de haut niveau manquent. Leur retour est précieux pour affiner l’analyse. 👥
Étude de cas : Une optimisation de workflow générique 🏭
Considérez un scénario où un système de traitement des commandes a connu des retards pendant les heures de pointe. L’analyse initiale a montré que l’étape de validation des commandes prenait trop de temps. Le DFD a révélé que la validation nécessitait trois vérifications distinctes contre différents systèmes externes.
En analysant le flux, l’équipe a compris que ces vérifications s’effectuaient de manière séquentielle. En modifiant la conception pour effectuer ces vérifications en parallèle, le temps total de validation a été réduit de 60 %. Le diagramme de flux de données a été mis à jour pour refléter cette nouvelle structure. La surveillance a confirmé que la file d’attente se vidait plus rapidement, et le système a géré les charges de pointe sans intervention. Cet exemple démontre comment des changements structurels dans le flux produisent des résultats immédiats. ✅
Meilleures pratiques pour une efficacité durable 🌱
Pour maintenir un système sain, suivez ces directives :
- Maintenez les diagrammes à jour : Une carte obsolète est pire qu’aucune carte.
- Concentrez-vous sur le flux, pas seulement sur la fonction : Assurez-vous que les données circulent sans heurt, et non seulement que les fonctionnalités fonctionnent.
- Mesurez tout : Si ce n’est pas mesuré, cela ne peut pas être amélioré.
- Revoyez régulièrement : Programmez des audits périodiques de l’architecture des données.
- Documentez les hypothèses : Enregistrez pourquoi certains flux ont été conçus d’une manière spécifique afin d’aider au dépannage futur.
En traitant le flux de données comme un actif essentiel, les organisations peuvent garantir que leurs systèmes restent réactifs et fiables. Le processus d’identification des goulets d’étranglement ne consiste pas à trouver des défauts, mais à comprendre en profondeur le système. Cette compréhension conduit à la résilience et à des performances optimales. 🛡️
Réflexions finales sur l’intégrité du flux de données 🧩
L’efficacité de tout système repose sur le déplacement fluide de l’information. Lorsque les données rencontrent une résistance, toute l’opération ralentit. L’analyse du flux de données offre un regard clair sur l’emplacement de cette résistance. En cartographiant, en mesurant et en modifiant le flux, les équipes peuvent éliminer les frottements et améliorer les performances.
Les techniques décrites ici fournissent un cadre pour une optimisation durable. Elles exigent de la discipline et une attention aux détails, mais le retour est un système qui fonctionne de manière cohérente sous pression. À mesure que les volumes de données augmentent, la capacité à gérer le flux devient de plus en plus critique. Maîtriser cette discipline assure la longévité et la fiabilité de l’architecture. 🏆