











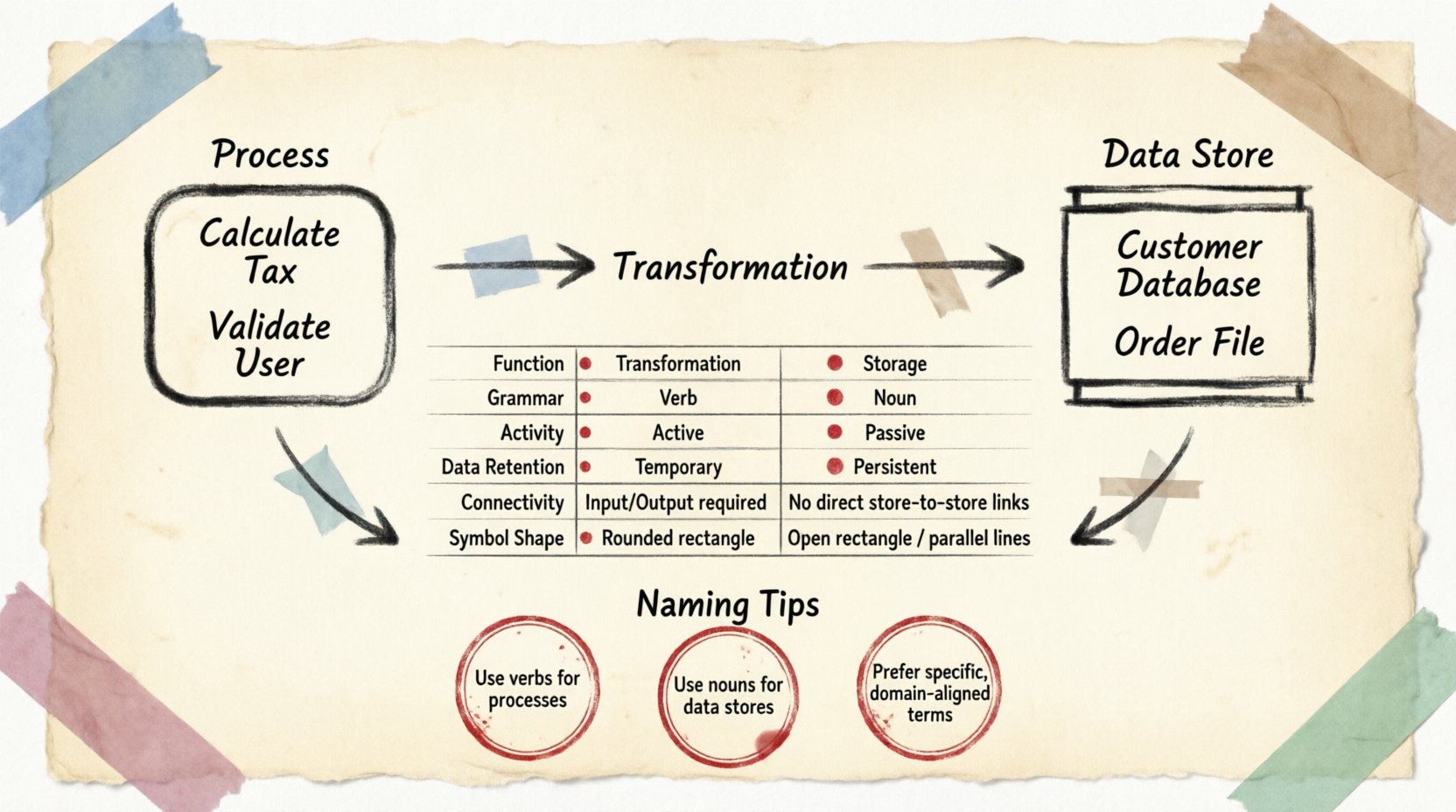
Lors de la modélisation de systèmes complexes, la clarté est l’objectif principal. Les diagrammes de flux de données (DFD) constituent un outil fondamental pour visualiser le déplacement de l’information à travers un système. Dans ce cadre, deux symboles dominent le paysage : le Processus et le Magasin de données. Bien qu’ils interagissent fréquemment, ils représentent des concepts fondamentalement différents en ce qui concerne la transformation et la persistance. Comprendre cette distinction est essentiel pour une analyse et une conception systématiques précises.
Ce guide explore les rôles fonctionnels, les représentations visuelles et les implications logiques de ces éléments. En distinguant l’action du stockage, les analystes peuvent concevoir des diagrammes qui communiquent le comportement du système sans ambiguïté.
🔄 Définition du Processus
Un processus représente une unité de travail ou une transformation. C’est là que les données changent de forme, sont calculées ou filtrées. Pensez à un processus comme une boîte noire. Vous savez ce qui entre et ce qui sort, mais le mécanisme interne est défini par la logique de transformation elle-même, et non par le stockage de ces informations.
🔹 Caractéristiques fondamentales
- Transformation : La fonction principale est de modifier les données. Les données d’entrée entrent, des règles ou une logique sont appliquées, puis les données de sortie sortent.
- Nature temporelle : Les processus sont actifs uniquement lorsqu’ils sont déclenchés. Ils ne conservent pas les données entre les exécutions.
- Directionnalité : Les données entrent et sortent d’un processus. Un processus sans entrée ou sortie est logiquement invalide dans un contexte DFD.
- Nomination par verbe : Les processus sont généralement étiquetés par des verbes ou des phrases verbales (par exemple, Calculer la taxe, Valider l’utilisateur, Générer un rapport).
🔹 Le concept de boîte noire
Dans la modélisation de haut niveau, un processus est une boîte noire. L’accent est mis sur ce qui se produit avec les données, et non sur comment cela se produit techniquement. Par exemple, un processus nommé « Traiter la commande » prend les détails de la commande et crée un enregistrement de transaction. Il ne précise pas si le calcul a lieu en mémoire, sur un disque ou via une API distante. Cette abstraction permet aux parties prenantes de se concentrer sur la logique métier plutôt que sur la mise en œuvre technique.
Toutefois, au fur et à mesure que les diagrammes sont décomposés en niveaux inférieurs, la logique interne devient plus détaillée. Même dans ce cas, le processus reste un moteur actif de transformation. Il consomme les entrées, effectue le travail et produit des sorties. Il ne sert pas de réservoir de conservation pour ces informations.
🗄️ Définition du Magasin de données
Un magasin de données représente un dépôt où les informations reposent. Contrairement à un processus, un magasin de données ne transforme pas les données. Il attend. Il conserve les données dans un état persistant jusqu’à ce qu’un processus les récupère ou les y place.
🔹 Caractéristiques fondamentales
- Persistance : Les données restent dans un magasin même lorsque aucun processus n’est actif. C’est ce qui distingue fondamentalement les magasins de données des tampons mémoire ou des variables temporaires.
- Nature passive : Les magasins de données ne lancent pas d’action. Ils nécessitent un processus pour lire ou écrire dessus.
- Nomination par des noms communs : Les magasins sont généralement étiquetés avec des noms communs (par exemple, Base de données des clients, Fichier de commandes, Journal des stocks).
- Ouvert : Les flux de données peuvent entrer et sortir d’un magasin. Toutefois, un magasin ne peut pas être directement connecté à un autre magasin. Les données doivent passer par un processus pour se déplacer entre les dépôts.
🔹 Le concept de dépôt
Imaginez une bibliothèque. Les livres sont les données. Les étagères sont les magasins de données. Un bibliothécaire est le processus. Le bibliothécaire ne crée pas les livres ; il les organise. Les étagères ne déplacent pas les livres elles-mêmes ; elles les maintiennent en place. Lorsqu’un lecteur demande un livre, le bibliothécaire le récupère (opération de lecture). Lorsqu’un nouveau livre arrive, le bibliothécaire le place sur l’étagère (opération d’écriture).
Dans l’architecture système, un magasin de données peut représenter une table de base de données, un fichier plat, une file d’attente ou un conteneur cloud. Le symbole DFD abstrait la technologie. Que ce soit une table SQL ou un simple fichier texte, le rôle logique est identique : il s’agit d’un endroit où les informations sont conservées.
⚡ Interaction et flux de données
La relation entre un processus et un magasin de données est régie par des règles strictes de flux de données. Les flèches dans un DFD représentent le déplacement des données. Ces flèches déterminent la direction du transfert d’information.
🔹 Le cycle lecture-écriture
Lorsqu’un processus a besoin d’informations, il dessine une flèche depuis un magasin de données vers le processus. Cela indique une opération de lecture. Le processus extrait les données pour les utiliser dans sa logique de transformation. Inversement, lorsque le processus génère de nouvelles informations, il dessine une flèche depuis le processus vers un magasin de données. Cela indique une opération d’écriture. Les données sont désormais stockées pour une utilisation future.
De façon cruciale, un flux de données ne peut pas relier directement deux magasins de données. Les informations ne peuvent pas migrer d’un dépôt à un autre sans être traitées. Cette règle renforce le principe selon lequel tout déplacement de données est toujours accompagné d’un certain niveau de logique ou de contrôle, même si cette logique est une simple opération de copie.
🔹 Entités externes
Les entités externes (sources ou puits) interagissent avec les processus, et non directement avec les magasins de données. Une entité externe peut être un utilisateur humain, une API tierce ou un autre système. Elles envoient des données à un processus ou reçoivent des données d’un processus. Le processus décide alors si stocker ces données dans un dépôt ou les rejeter.
📋 Tableau de comparaison
Pour résumer les différences structurelles, considérez la répartition suivante des attributs.
| Attribut | Processus | Magasin de données |
|---|---|---|
| Fonction | Transformation / Action | Stockage / Mémoire |
| Grammaire | Verbe (par exemple, Mettre à jour) | Nom (par exemple, Table Utilisateur) |
| Activité | Actif (s’exécute lorsqu’il est déclenché) | Passif (reste en attente jusqu’à son accès) |
| Rétention des données | Temporaire (pendant l’exécution) | Persistant (à long terme) |
| Connectivité | Se connecte aux Entités, aux Stockages, aux Autres Processus | Se connecte uniquement aux Processus |
| Forme du symbole | Rectangle arrondi ou cercle | Rectangle ouvert ou lignes parallèles |
🧩 Conventions de nommage
La cohérence dans le nommage évite la confusion pendant les phases de revue et d’implémentation. L’ambiguïté survient souvent lorsque le même terme est utilisé à la fois pour le stockage et l’action.
🔹 Nommage des processus
Les noms doivent décrire l’action effectuée sur les données. Évitez les noms génériques comme « Faire ça » ou « Gérer ». Utilisez plutôt des descripteurs précis. Par exemple, « Valider les identifiants de connexion » est préférable à « Vérifier la connexion ». Cette clarté aide les développeurs à comprendre immédiatement les exigences en entrée et en sortie.
🔹 Nomage des magasins de données
Les noms doivent refléter le contenu stocké. Utilisez des noms pluriels ou des identifiants clairs. « Orders » implique une collection d’enregistrements de commandes. « Order » pourrait indiquer une instance unique d’une transaction. Bien que le contexte soit important, les noms pluriels indiquent généralement un référentiel contenant plusieurs enregistrements.
Lors du nommage des magasins de données, tenez compte de l’ampleur. Un magasin nommé « Base de données » est trop vague. « Base de données Clients » ou « Journal des transactions » fournit le contexte nécessaire. Cette précision aide à relier le diagramme aux structures de stockage physiques ultérieurement.
🧪 Décomposition et niveaux
Les diagrammes de flux de données (DFD) sont hiérarchiques. Un diagramme de haut niveau (Diagramme de contexte) représente le système comme un seul processus. Lorsque vous le décomposez en niveaux inférieurs, la distinction entre processus et stockage devient plus critique.
🔹 Niveau 0 vs. Niveau 1
Dans un diagramme de contexte, l’ensemble du système est un seul processus. Au niveau 0, ce processus est décomposé en sous-processus majeurs. Les magasins de données sont introduits ici pour montrer où se trouvent les composants principaux des données. Au niveau 1 et au-delà, les processus sont affinés davantage.
Lors de la décomposition, assurez-vous que les magasins de données ne sont pas dupliqués inutilement. Si un magasin existe au niveau 0, il doit généralement persister jusqu’au niveau 1, sauf si un sous-processus spécifique nécessite une mémoire cache temporaire (qui serait alors un magasin différent). La cohérence entre les niveaux garantit la traçabilité.
🔹 Équilibre
Une règle fondamentale dans la décomposition est l’« équilibre ». Les entrées et sorties d’un processus parent doivent correspondre aux entrées et sorties des processus enfants dans le diagramme de niveau inférieur. Les magasins de données doivent également être alignés. Si un magasin apparaît dans le diagramme parent, le diagramme enfant doit correctement prendre en compte ce flux de données. Si un processus est divisé, le flux de données vers le magasin doit être maintenu à travers la division.
⚠️ Erreurs logiques à éviter
Certaines erreurs structurelles peuvent invalider un diagramme. Les reconnaître tôt permet d’économiser du temps pendant la phase de développement.
- Flux de données fantômes : Une flèche quittant un processus sans flux de données entrant est impossible. Un processus ne peut pas générer une sortie à partir de rien. Chaque sortie doit être dérivée d’une entrée ou de données stockées.
- Connexions directes entre les magasins : Comme mentionné, un magasin ne peut pas se connecter à un autre magasin. Les données doivent passer par un processus. Cela garantit que tous les déplacements de données sont intentionnels et traités.
- Processus non connectés : Un processus qui n’a ni flux de données entrants ni sortants est isolé. Il n’interagit pas avec le système et n’a aucune fonction dans le diagramme de flux de données.
- Confusion entre entités et magasins : Les entités externes sont situées à l’extérieur de la frontière du système. Les magasins de données sont à l’intérieur. Ne placez pas le symbole d’une entité externe à l’intérieur de la frontière du système comme s’il s’agissait d’une base de données.
🛠️ Implications pour la mise en œuvre
La distinction entre processus et magasin influence la manière dont le système est construit. Les processus correspondent à des fonctions, des méthodes ou des microservices. Les magasins de données correspondent à des tables, des fichiers ou un stockage d’objets.
🔹 Conception de base de données
Lors de la conception d’une base de données, les magasins de données du diagramme de flux de données deviennent le plan directeur du schéma. Les attributs situés dans les flèches de flux de données définissent les colonnes. Les relations entre les magasins (médiées par les processus) définissent les clés étrangères ou les liens transactionnels.
🔹 Automatisation des flux de travail
Pour les moteurs de flux de travail, les processus représentent les étapes d’une chaîne. Les magasins de données représentent l’état du flux de travail. Un processus peut mettre à jour l’état dans le magasin pour marquer une tâche comme terminée. Comprendre la nature passive du magasin garantit que le moteur de flux de travail attend l’état correct avant de poursuivre.
🔍 Normes de représentation visuelle
Différentes méthodologies utilisent des symboles légèrement différents, mais la logique reste cohérente.
- DeMarco & Yourdon : Utilise des rectangles arrondis pour les processus et des rectangles ouverts pour les magasins de données.
- Gane & Sarson : Utilise des rectangles arrondis pour les processus et des lignes parallèles pour les magasins de données.
Quelle que soit la notation choisie, le sens sémantique est identique. Un processus agit ; un magasin contient. La cohérence dans la documentation du projet est plus importante que le respect d’une norme spécifique, à condition que l’équipe comprenne la convention choisie.
🎯 Résumé des rôles
Construire un modèle de système robuste exige une discipline dans l’attribution des rôles. Le processus est l’acteur. Il effectue le travail. Le magasin de données est la scène. Il contient les accessoires. Sans l’acteur, la scène est vide. Sans la scène, l’acteur n’a nulle part où déposer ses résultats.
En maintenant une séparation claire entre transformation et stockage, les analystes créent des diagrammes qui sont non seulement visuellement attrayants mais aussi logiquement solides. Ces diagrammes servent de contrat entre les parties prenantes métier et les équipes techniques. Ils définissent les limites de responsabilité et le flux de valeur.
Lors de la revue d’un diagramme de flux de données, posez deux questions pour chaque symbole : « Est-ce qui fait un travail ? » (Processus) ou « Est-ce qui conserve des informations ? » (Magasin). Si la réponse n’est pas claire, affinez l’étiquette ou la connexion. La clarté est l’objectif ultime de la modélisation système.
Adhérer à ces principes garantit que l’architecture résultante est maintenable, évolutif et compréhensible. La distinction est simple, mais son impact sur l’intégrité du système est profond.