











Dans l’architecture moderne de l’information, l’intégrité des données constitue la fondation du comportement fiable du système. Lorsqu’une donnée entre dans un environnement de traitement, elle peut comporter des risques potentiels pouvant perturber les opérations, compromettre la sécurité ou corrompre les sorties en aval. Valider les entrées du système n’est pas simplement une vérification de sécurité ; c’est une exigence logique fondamentale intégrée dans la conception du système. En utilisant la logique de flux au sein des diagrammes de flux de données (DFD), les ingénieurs peuvent déterminer précisément où a lieu la validation, comment les erreurs sont gérées et comment les données transitent à travers l’architecture. Cette approche garantit que chaque information entrant dans le système respecte les critères nécessaires avant d’influencer la logique métier.
Cet article explore les mécanismes de validation des entrées à travers le prisme de la logique de flux. Nous examinerons comment représenter visuellement les règles de validation, comment structurer les points de décision pour l’acceptation des données, et comment gérer les états d’erreur sans interrompre le flux. Comprendre ces mécanismes permet aux architectes de concevoir des systèmes résilients face aux données malformées et aux menaces externes.
Comprendre les diagrammes de flux de données dans la validation 📊
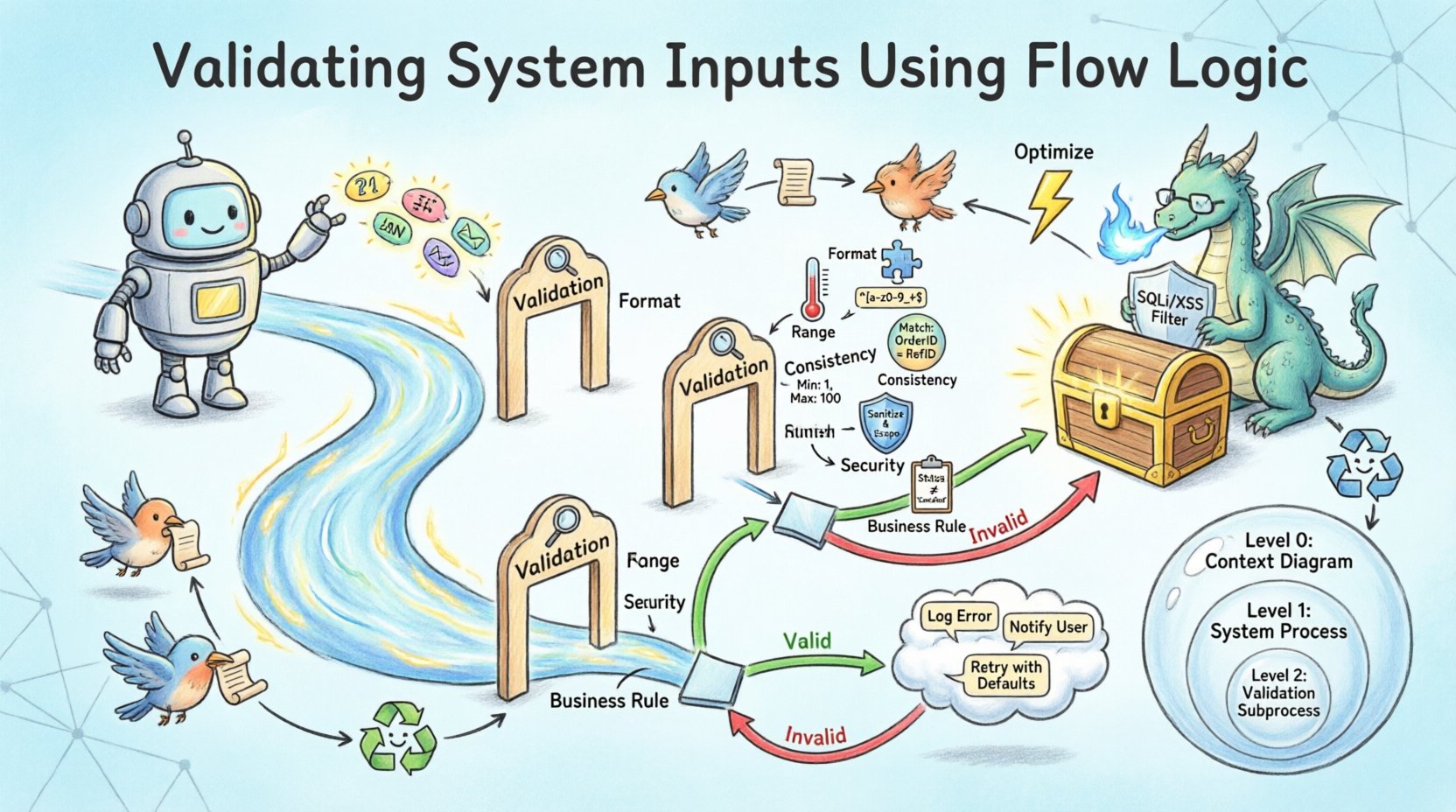
Les diagrammes de flux de données fournissent une représentation visuelle du déplacement de l’information à travers un système. Ils représentent les processus, les entrepôts de données, les entités externes et les données elles-mêmes. Dans le contexte de la validation, le DFD devient une carte de confiance. Il montre où les données sont reçues, où elles sont vérifiées, et où elles sont stockées ou rejetées.
Un DFD standard se compose de quatre éléments principaux :
- Processus : Une transformation de données. C’est là que la logique de validation réside généralement.
- Entrepôt de données : Un répertoire où les données sont sauvegardées. La validation doit avoir lieu avant que les données n’entrent dans un entrepôt.
- Entité externe : Une source ou une destination de données située en dehors de la frontière du système. Les entrées proviennent d’ici.
- Flux de données : Le déplacement des données entre les éléments. Les vérifications de validation ont lieu le long de ces chemins.
Lors de la conception pour la validation, l’élément Processus devient critique. Il ne suffit pas de déplacer simplement les données du point A au point B. Le processus doit évaluer les données par rapport à un ensemble de règles. Dans le diagramme, cela est souvent représenté par un sous-processus spécifique étiqueté « Validation » ou « Nettoyage ». Ce repère visuel rappelle aux développeurs qu’une logique existe ici pour filtrer les entrées.
Mapper la logique de validation aux structures de flux 🧠
La logique de flux fait référence à la séquence d’opérations qui détermine le parcours des données. Dans la validation, cette logique détermine si les données progressent vers l’étape suivante ou sont redirigées vers un gestionnaire d’erreurs. Mettre cela en œuvre nécessite une compréhension claire des points de décision.
Prenons un formulaire de saisie de données qui collecte des informations utilisateur. La logique de flux doit vérifier les attributs suivants :
- Présence : Le champ est-il rempli ?
- Type : L’entrée est-elle du bon type de données (par exemple, entier contre chaîne) ?
- Plage : La valeur est-elle comprise dans des limites acceptables ?
- Format : La chaîne correspond-elle à un motif requis (par exemple, adresse e-mail) ?
Dans un DFD, ces vérifications créent des branches. Si les données passent toutes les vérifications, le flux progresse vers le processus principal. Si elles échouent, le flux est redirigé vers un processus de gestion des erreurs. Cette branche est essentielle pour une architecture robuste. Sans elle, des données invalides pourraient se propager silencieusement, entraînant des erreurs de calcul ou des vulnérabilités de sécurité.
Le mécanisme des points de décision
Les points de décision sont les endroits où le flux se divise. Dans les diagrammes de logique de flux, cela est souvent représenté par une forme en losange ou un nœud de processus spécifique qui produit deux flux de données distincts : l’un étiqueté « Valide » et l’autre étiqueté « Non valide ». Le flux « Valide » continue vers la chaîne principale de traitement. Le flux « Non valide » déclenche une réponse d’erreur ou une boucle de correction.
Il est important de distinguer la validation côté client de la validation côté serveur dans le diagramme. Bien que la validation côté client améliore l’expérience utilisateur, la validation côté serveur est le véritable gardien. Dans le DFD, la vérification côté serveur doit être la dernière barrière avant que les données n’atteignent l’entrepôt de données. Cela garantit que même si l’interface est contournée, le système central reste protégé.
Types de règles de validation des entrées 🛡️
La validation n’est pas un concept monolithique. Elle englobe plusieurs niveaux de vérification. Chaque niveau sert un objectif différent et nécessite des stratégies d’implémentation différentes dans la logique de flux.
| Type de validation | Objectif | Logique d’exemple |
|---|---|---|
| Validation du format | Assure que les données correspondent à la structure attendue | Correspondance par expression régulière pour les numéros de téléphone |
| Validation de plage | Assure que les données se trouvent dans des limites numériques | L’âge doit être compris entre 18 et 120 |
| Validation de cohérence | Assure que les données sont conformes aux autres entrées | La date de fin doit être postérieure à la date de début |
| Validation de sécurité | Empêche l’injection de code malveillant | Nettoyer les balises HTML dans les champs de texte |
| Validation des règles métier | Assure que les données respectent les contraintes opérationnelles | La remise ne peut pas dépasser 50 % |
Intégrer ces règles dans la logique de flux nécessite une séquence soigneuse. La validation de sécurité doit généralement avoir lieu en amont du processus afin d’éviter un traitement coûteux de charges malveillantes. La validation du format est généralement la première étape pour s’assurer que les types de données sont corrects avant toute comparaison logique. La validation des règles métier a souvent lieu en dernier, car elle peut dépendre de données déjà normalisées.
Gestion des flux d’erreurs et des boucles de rétroaction 🔄
Un système robuste ne rejette pas seulement les données non valides ; il gère ce rejet de manière élégante. C’est ici que la branche « Non valide » de la logique de flux entre en jeu. Le flux d’erreur doit conduire à un mécanisme informant l’utilisateur ou l’administrateur système du problème sans révéler de détails internes sensibles.
Dans le diagramme de flux de données, le processus de gestion des erreurs doit inclure :
- Journalisation : Enregistrer les détails de l’erreur pour le débogage. Ce flux va vers un magasin de données de journal d’audit.
- Notification : Alerter l’utilisateur. Ce flux va vers l’entité externe (interface utilisateur).
- Correction : Fournir un mécanisme pour corriger les données. Cela crée une boucle de rétroaction où les données reviennent à l’étape d’entrée.
Les boucles de rétroaction sont essentielles pour l’utilisabilité. Si un utilisateur soumet un formulaire avec une adresse e-mail non valide, le système doit lui permettre de la corriger immédiatement. En termes de flux, les données ne quittent pas définitivement l’étape d’entrée. Elles sont réévaluées par rapport à la logique de validation jusqu’à ce qu’elles soient validées ou que l’utilisateur annule l’action. Cela évite les impasses dans le parcours utilisateur.
Journalisation des erreurs et traçabilité
La sécurité et la conformité exigent souvent que les échecs de validation soient enregistrés. Même si l’entrée est rejetée, l’essai lui-même pourrait être un signe d’une attaque. Par conséquent, un flux de données distinct doit exister depuis le processus de validation vers un journal d’audit. Ce flux capture les horodatages, les adresses IP sources et la nature de l’échec. Il fonctionne indépendamment du flux principal de données afin de garantir que les échecs de journalisation n’empêchent pas le traitement légitime.
Intégration de la validation aux niveaux de processus 🏗️
Les diagrammes de flux de données existent souvent à différents niveaux d’abstraction. Le niveau 0 fournit un aperçu général, tandis que les niveaux 1 et 2 détaillent des processus spécifiques. La logique de validation doit être cohérente à travers ces niveaux.
Niveau 0 : Frontière du système
Au niveau le plus élevé, la validation est représentée comme une porte. L’entité externe envoie des données, et le système les accepte ou les rejette. Le diagramme de flux de données (DFD) montre les frontières d’entrée et de sortie. Toute donnée qui échoue à la validation à ce stade n’entre jamais dans le système interne.
Niveau 1 : Découpage des processus
Lors du découpage du système, des processus spécifiques reçoivent des sous-flux de validation. Par exemple, un processus « Inscription utilisateur » peut se diviser en « Vérification d’identité », « Validation du mot de passe » et « Vérification des coordonnées ». Chacun de ces sous-processus possède sa propre logique de flux. Le DFD à ce niveau montre les déplacements internes des données nécessaires pour effectuer ces vérifications.
Niveau 2 : Logique détaillée
Au niveau le plus bas, la logique est entièrement définie. C’est ici que la structure réelle du code est dérivée du diagramme. La logique de flux précise l’ordre exact des opérations. Par exemple, vérifier si un nom d’utilisateur existe dans la base de données doit se faire avant de vérifier s’il est au bon format, afin d’éviter de révéler des informations sur les utilisateurs existants.
Optimisation des performances pendant la validation ⚡
La logique de validation ajoute une surcharge computationnelle. Chaque vérification nécessite du temps de traitement. Dans les systèmes à fort volume, une validation excessive peut devenir un goulot d’étranglement. Le DFD aide à identifier où l’optimisation est nécessaire.
Les stratégies d’optimisation incluent :
- Sortie anticipée : Si un contrôle basique échoue (par exemple, champ vide), arrêtez immédiatement le traitement. Ne pas exécuter de logique complexe.
- Mise en cache : Si la validation dépend de données externes (par exemple, vérifier un ID utilisateur contre une liste de comptes bannis), mettez ces données en cache pour réduire les appels à la base de données.
- Traitement asynchrone : Pour les validations non critiques, déplacez la vérification vers une file d’attente en arrière-plan. Cela maintient le flux principal de données rapide.
Lors de la représentation de ces optimisations dans le DFD, utilisez des flux de données distincts pour les tâches synchrones et asynchrones. Cela clarifie quelles validations bloquent l’utilisateur et lesquelles s’exécutent en arrière-plan. Cela aide également dans les scénarios de test de charge où le comportement du système sous contrainte doit être compris.
Implications de sécurité de la logique de flux 🔒
Les entrées non valides constituent un vecteur principal d’attaques telles que l’injection SQL, le script cross-site ou les dépassements de tampon. La logique de flux conçue pour la validation agit comme un pare-feu. Toutefois, la conception doit être correcte.
Un défi courant dans la conception est l’hypothèse selon laquelle les entrées proviennent d’une source de confiance. Dans le DFD, chaque entité externe doit être traitée comme potentiellement hostile. Le processus de validation doit nettoyer les données avant qu’elles n’interagissent avec les bases de données ou les lignes de commande. Ce nettoyage est un nœud de processus spécifique dans le diagramme.
En outre, la logique de flux doit empêcher la fuite d’informations. Si une erreur de validation révèle qu’un nom d’utilisateur existe, un attaquant peut exploiter cela pour répertorier des comptes. Le flux d’erreur doit fournir des messages génériques (par exemple, « Identifiants non valides ») plutôt que des raisons spécifiques (par exemple, « Nom d’utilisateur introuvable »). Ce détail doit être capturé dans la description du processus de gestion des erreurs.
Tests et vérification des flux de validation ✅
Une fois la logique de flux conçue, elle doit être vérifiée. Les tests consistent à envoyer des données à travers les chemins du DFD pour s’assurer que la logique est correcte. Cela est souvent fait à l’aide de tests unitaires pour des règles de validation individuelles et de tests d’intégration pour l’ensemble du flux.
Les cas de test doivent couvrir :
- Chemin normal :Les données valides passent toutes les vérifications et atteignent le magasin de données.
- Cas limites :Données aux limites des plages (par exemple, valeurs minimales et maximales).
- Données malformées :Données avec des types incorrects ou des caractères inattendus.
- Données manquantes :Données où des champs requis sont absents.
Si le DFD est précis, les résultats des tests doivent correspondre aux flux visualisés. Si un cas de test échoue de manière non prévue par le diagramme, le DFD doit être mis à jour. Ce processus itératif garantit que la documentation reste une représentation fidèle du comportement du système.
Conclusion sur la validation structurée 📝
Valider les entrées du système à l’aide de la logique de flux transforme une exigence de sécurité en un composant structurel de l’architecture. En cartographiant les règles de validation dans les diagrammes de flux de données, les équipes peuvent visualiser où les données sont vérifiées, comment les erreurs sont gérées et comment les informations circulent dans le système. Cette clarté réduit l’ambiguïté, améliore la communication entre les concepteurs et les développeurs, et conduit finalement à un logiciel plus stable. L’intégration de points de décision, de flux d’erreurs et de contrôles de sécurité garantit que le système reste robuste face au bruit inévitable du monde extérieur.
À mesure que les systèmes gagnent en complexité, la dépendance à la logique de flux structurée devient encore plus critique. Elle fournit un plan directeur pour préserver l’intégrité des données au fil du temps. En s’attachant aux principes décrits ici, les architectes peuvent concevoir des pipelines qui ne font confiance à rien et vérifient tout, assurant ainsi la pérennité et la fiabilité de l’écosystème des données.