











在建模复杂系统时,清晰性是首要目标。数据流图(DFD)是一种基础工具,用于可视化信息在系统中的流动方式。在此框架中,有两个符号占据主导地位:处理以及数据存储尽管它们经常交互,但它们代表了关于转换和持久性截然不同的概念。理解这一区别对于准确的系统分析与设计至关重要。
本指南探讨了这些元素的功能角色、视觉表示及其逻辑含义。通过区分动作与存储,分析人员可以构建出清晰传达系统行为而无歧义的图表。
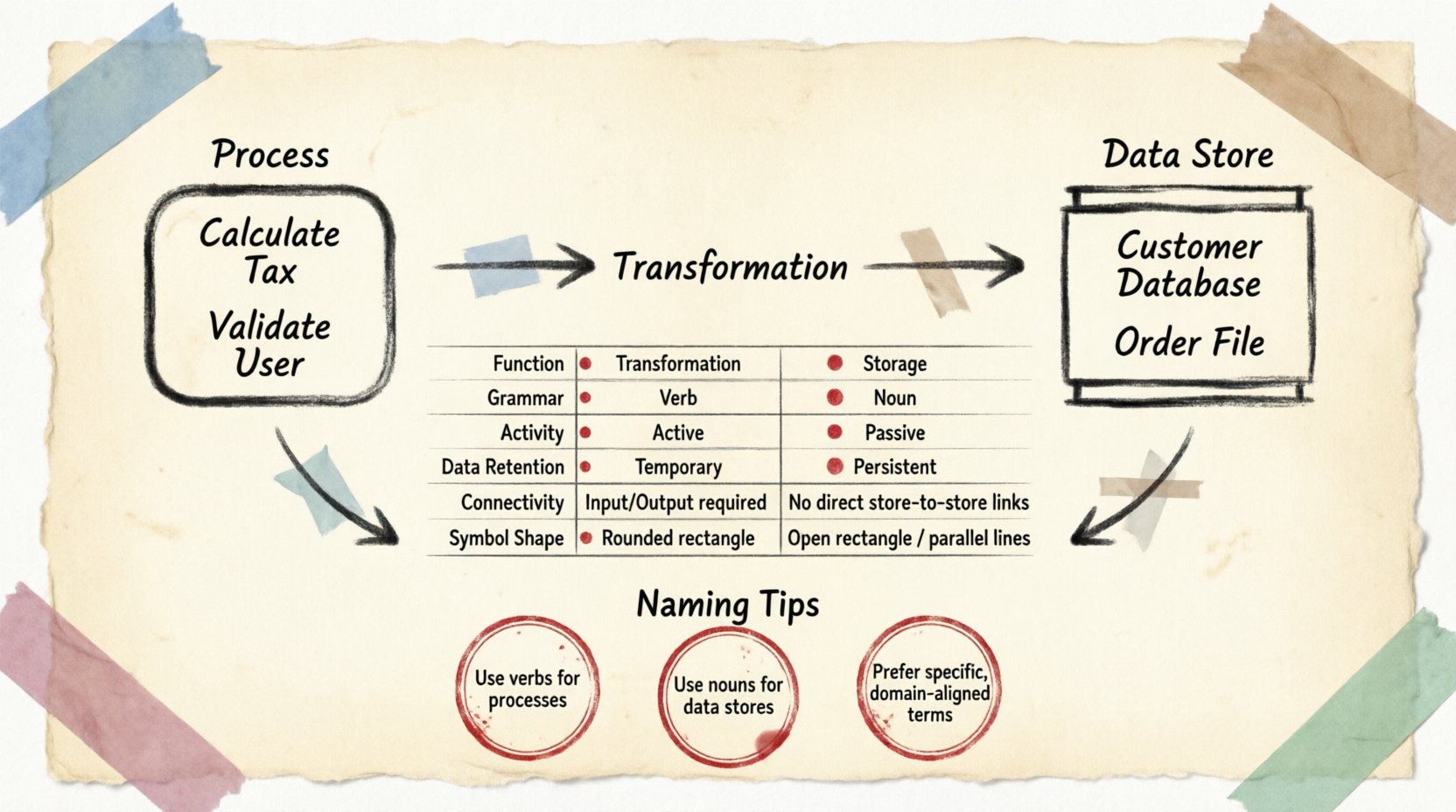
🔄 定义处理
处理代表一项工作或转换的单位。它是数据改变形式、被计算或被过滤的地方。可以将处理视为一个黑箱。你知道什么进入,什么离开,但内部机制由转换逻辑本身决定,而非由信息的存储方式决定。
🔹 核心特征
- 转换: 主要功能是修改数据。输入数据进入,应用规则或逻辑,输出数据离开。
- 时间特性: 处理仅在被触发时才处于活动状态。它们在执行之间不会保留数据。
- 方向性: 数据流入并流出处理。在DFD上下文中,没有输入或输出的处理在逻辑上是无效的。
- 动词命名: 处理通常用动词或动词短语命名(例如,计算税款, 验证用户, 生成报告).
🔹 黑箱概念
在高层建模中,处理是一个黑箱。重点在于发生了什么,而不是如何技术上是如何实现的。例如,名为“处理订单”的处理接收订单详情并创建交易记录。它并不说明计算是在内存中、磁盘上还是通过远程API完成的。这种抽象使利益相关者能够专注于业务逻辑,而非技术实现。
然而,随着图表分解到更低层级,内部逻辑会变得更加详细。即便如此,处理仍然是一个活跃的转换引擎。它消耗输入,执行工作,并产生输出。它并不作为信息的暂存容器。
🗄️ 定义数据存储
数据存储表示信息存放的仓库。与处理过程不同,数据存储不会转换数据。它处于等待状态,将数据以持久状态保存,直到某个过程检索它或将其存入。
🔹 核心特性
- 持久性: 数据即使在没有活动过程时仍保留在存储中。这是与内存缓冲区或临时变量的关键区别。
- 被动性: 数据存储不会主动发起操作。它们需要由一个过程来读取或写入。
- 名词命名: 存储通常用名词命名(例如,客户数据库, 订单文件, 库存日志).
- 开放性: 数据流可以进入和离开一个存储。然而,一个存储不能直接连接到另一个存储。数据必须通过一个过程在不同仓库之间流动。
🔹 仓库概念
想象一个图书馆。书籍就是数据。书架就是数据存储。图书管理员就是处理过程。图书管理员并不创造书籍,而是对它们进行整理。书架本身不会移动书籍,而是将它们固定在原位。当读者请求一本书时,图书管理员将其取出(读取操作)。当新书到达时,图书管理员将其放置在书架上(写入操作)。
在系统架构中,数据存储可能代表数据库表、平面文件、队列或云存储桶。DFD符号抽象了技术细节。无论是SQL表还是简单的文本文件,其逻辑角色完全相同:它是一个信息存放的位置。
⚡ 交互与数据流
过程与数据存储之间的关系由严格的数据流规则所支配。DFD中的箭头表示数据的移动。这些箭头决定了信息传输的方向。
🔹 读写循环
当一个过程需要信息时,它会从数据存储向过程画一个箭头。这表示一次读取操作。该过程提取数据,用于其转换逻辑。相反,当一个过程生成新信息时,它会从过程向数据存储画一个箭头。这表示一次写入操作。数据现在被存储以供将来使用。
关键的是,数据流不能直接连接两个数据存储。信息无法在不经过处理的情况下从一个仓库迁移到另一个仓库。这一规则强化了数据移动总是伴随着某种逻辑或控制的原则,即使这种逻辑只是一个简单的复制操作。
🔹 外部实体
外部实体(源或汇)与过程交互,而不是直接与数据存储交互。外部实体可能是人类用户、第三方API或另一个系统。它们向过程发送数据或从过程接收数据。然后,过程决定是否将该数据存储在仓库中,或将其丢弃。
📋 对比表
为了总结结构上的差异,请考虑以下属性的分解。
| 属性 | 过程 | 数据存储 |
|---|---|---|
| 功能 | 转换 / 操作 | 存储 / 内存 |
| 语法 | 动词(例如:更新) | 名词(例如:用户表) |
| 活动 | 主动(触发时运行) | 被动(等待访问时才激活) |
| 数据保留 | 临时(执行期间) | 持久(长期) |
| 连接性 | 连接到实体、存储、其他过程 | 仅连接到过程 |
| 符号形状 | 圆角矩形或圆形 | 开口矩形或平行线 |
🧩 命名规范
命名的一致性可以防止在评审和实施阶段产生混淆。当同一个术语被同时用于存储和操作时,歧义常常会出现。
🔹 过程命名
名称应描述对数据执行的操作。避免使用“做它”或“处理”之类的通用名称。应使用具体的描述词。例如,“验证登录凭据”比“检查登录”更优。这种清晰性有助于开发人员立即理解预期的输入和输出要求。
🔹 数据存储命名
名称应反映其内部所包含的内容。使用复数名词或明确的标识符。“Orders”暗示一组订单记录的集合。“Order”可能暗示单个事务实例。虽然上下文很重要,但复数名词通常表示包含多个记录的存储库。
在命名数据存储时,应考虑范围。名为“Database”的存储过于模糊。“客户数据库”或“交易日志”则提供了必要的上下文。这种细致程度有助于后续将图表映射到物理存储结构。
🧪 分解与层级
DFD 是分层的。高层图(上下文图)将系统视为一个单一过程。当你将其分解为更低层级时,过程与存储之间的区别变得更为关键。
🔹 0级与1级
在上下文图中,整个系统被视为一个过程。在0级中,该过程被分解为主要的子过程。在此引入数据存储,以显示主要数据组件的位置。在1级及更深层次中,过程进一步细化。
在分解过程中,确保数据存储不会被不必要的重复。如果某存储在0级存在,通常应延续到1级,除非某个特定子过程需要临时缓存(这将是一个不同的存储)。各层级之间的一致性确保了可追溯性。
🔹 平衡
分解中的一个关键规则是“平衡”。父过程的输入和输出必须与下层图中子过程的输入和输出相匹配。数据存储也必须对齐。如果存储出现在父图中,子图必须正确地处理该数据流。如果一个过程被拆分,流向存储的数据流必须在拆分后保持一致。
⚠️ 需避免的逻辑错误
某些结构上的错误可能会使图表无效。及早识别这些错误可以在开发阶段节省时间。
- 幽灵数据流: 一个过程如果没有输入数据流就发出箭头是不可能的。一个过程不可能凭空产生输出。每个输出都必须来自输入或存储的数据。
- 直接存储连接: 如前所述,存储不能直接连接到另一个存储。数据必须经过一个过程。这确保了所有数据流动都是有意的并被处理。
- 孤立的过程: 一个既没有输入也没有输出数据流的过程是孤立的。它不与系统交互,在数据流图中没有任何作用。
- 混淆实体与存储: 外部实体位于系统边界之外。数据存储位于系统内部。不要将外部实体的符号放在系统边界内,仿佛它是一个数据库。
🛠️ 实现影响
过程与存储之间的区别会影响系统的构建方式。过程对应函数、方法或微服务。数据存储对应表、文件或对象存储。
🔹 数据库设计
在设计数据库时,数据流图中的数据存储将成为模式蓝图。数据流箭头中的属性定义了列。存储之间的关系(由过程中介)定义了外键或事务链接。
🔹 工作流自动化
对于工作流引擎,过程代表流水线中的步骤。数据存储代表工作流的状态。一个过程可能会更新存储中的状态,以标记任务已完成。理解存储的被动性质,可以确保工作流引擎在继续之前等待正确的状态。
🔍 可视化表示标准
不同的方法论使用略有不同的符号,但逻辑保持一致。
- 德马科与尤尔丹: 过程使用圆角矩形,数据存储使用开口矩形。
- 盖恩与萨尔森: 过程使用圆角矩形,数据存储使用平行线。
无论选择哪种符号表示,其语义含义都相同。过程是动作的执行者;存储是信息的持有者。项目文档内部的一致性比遵循特定标准更重要,只要团队理解所选的约定即可。
🎯 角色总结
构建一个稳健的系统模型需要在角色分配上保持纪律。过程是执行者,它完成工作。数据存储是舞台,它承载道具。没有执行者,舞台就是空的;没有舞台,执行者无处安放其成果。
通过保持转换与存储之间的清晰分离,分析人员可以创建不仅视觉上美观,而且逻辑上严谨的图表。这些图表充当业务利益相关者与技术团队之间的契约。它们定义了责任边界和价值流动。
在审查数据流图时,对每个符号都应提出两个问题:“它是否在执行工作?”(过程)或“它是否在保存信息?”(存储)。如果答案不明确,应优化标签或连接关系。清晰是系统建模的最终目标。
遵循这些原则可确保最终架构具备可维护性、可扩展性和可理解性。这一区分看似简单,但对系统完整性的影响却极为深远。