











In the landscape of modern software architecture, few concepts carry as much weight as encapsulation. It serves as a fundamental pillar of Object-Oriented Analysis and Design (OOAD), providing the structural integrity necessary for complex systems to function reliably. As applications grow in complexity, the need to manage state, behavior, and data flow becomes increasingly critical. Encapsulation offers a systematic approach to managing this complexity by bundling data and methods that operate on that data within a single unit.
This guide explores the mechanics, benefits, and practical applications of encapsulation. We will examine how it contributes to maintainability, security, and scalability without relying on specific vendor tools or proprietary languages. The focus remains on the underlying principles that govern robust software construction.
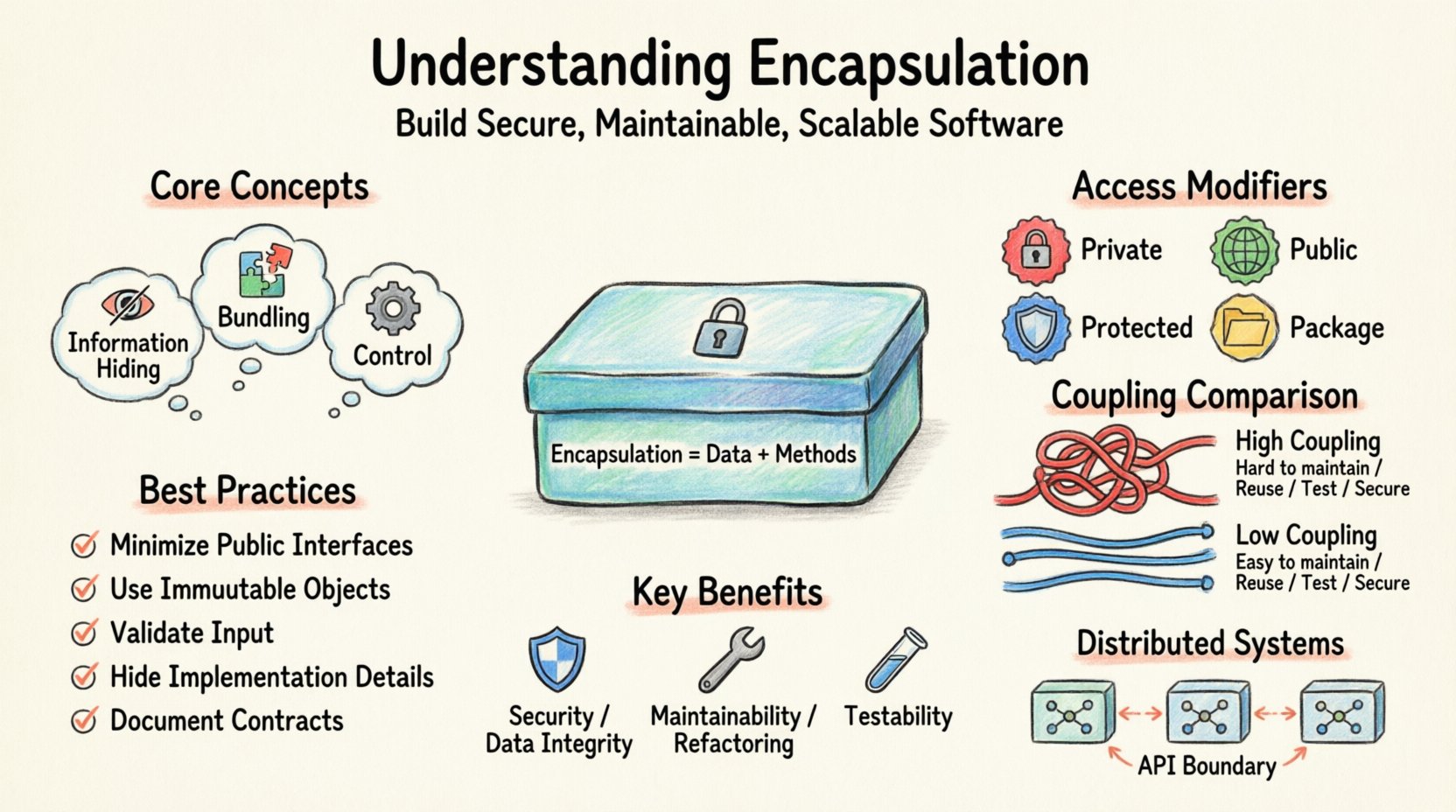
🏗️ The Core Concept of Encapsulation
At its essence, encapsulation is the practice of hiding the internal state of an object and requiring all interaction to be performed through an object’s methods. This concept is often summarized as data hiding. By preventing external code from accessing internal data directly, the system ensures that the internal representation of the object remains flexible and can be modified without breaking dependent code.
Think of encapsulation as a sealed container. You know what goes in and what comes out, but you do not need to know the mechanics of how the container processes the input to use it. This separation of interface from implementation is vital for large-scale development.
- Information Hiding: Prevents direct access to object attributes.
- Bundling: Combines data (fields) and behavior (methods) into a cohesive unit.
- Control: Dictates how external code interacts with the internal logic.
Without this structure, software components become tightly coupled. A change in one area of the system could cascade into failures in unrelated areas. Encapsulation acts as a buffer, absorbing changes and protecting the integrity of the broader system.
🔒 Mechanisms of Data Hiding
To implement encapsulation effectively, developers utilize specific mechanisms to control visibility. These mechanisms define the scope of accessibility for different parts of the code. While syntax varies across different programming environments, the logical categories remain consistent.
Access Modifiers
Access modifiers are keywords that set the accessibility level of classes, methods, and variables. They determine who can see and interact with specific components.
| Modifier | Visibility Scope | Primary Use Case |
|---|---|---|
| Private | Only within the defining class | Internal state variables that must not be exposed |
| Public | Accessible from any other class | Interfaces, constructors, and essential methods |
| Protected | Within the class and its subclasses | Members intended for inheritance hierarchies |
| Package/Private | Within the same package or namespace | Collaboration among closely related classes |
Using these modifiers correctly ensures that the internal logic remains secure. For instance, a variable representing a user’s authentication token should always be private. Exposing it publicly could lead to security vulnerabilities where sensitive data is accessed or modified by unintended parts of the system.
🔄 Encapsulation within Object-Oriented Analysis
In the context of Object-Oriented Analysis and Design, encapsulation is not merely a coding technique; it is a design philosophy. It influences how requirements are translated into software models. During the analysis phase, developers identify objects and their responsibilities. Encapsulation dictates how those responsibilities are hidden and exposed.
Responsibility Assignment
Each object should be responsible for its own data. This principle, often referred to as the Single Responsibility Principle, aligns closely with encapsulation. An object should not delegate the management of its own state to external controllers unless absolutely necessary.
- Internal Consistency: The object validates its own data before accepting changes.
- Behavioral Coupling: Methods that logically belong together are grouped within the class.
- External Independence: External callers do not need to know how the object functions, only what it can do.
This approach simplifies the mental model for developers working on a project. When a developer interacts with a class, they interact with a well-defined contract rather than a complex web of internal variables. This reduces cognitive load and minimizes the likelihood of introducing bugs during maintenance.
🛡️ Benefits for System Architecture
The advantages of proper encapsulation extend beyond simple code organization. They impact the long-term health of the software product, influencing security, testability, and evolution.
1. Security and Data Integrity
By restricting access to internal data, the system prevents unauthorized modification. This is crucial for financial transactions, user credentials, and sensitive business logic. Encapsulation ensures that invariants (conditions that must always be true) are maintained. For example, a bank account object should prevent a withdrawal that results in a negative balance. This logic resides within the object, not outside of it.
2. Maintainability and Refactoring
When internal implementation details are hidden, the internal code can be changed without affecting external code. This freedom allows developers to refactor the internal logic to improve performance or readability without triggering a regression in the wider system. This decoupling is essential for agile development cycles where requirements change frequently.
3. Testability
Encapsulated units are easier to test in isolation. Since the internal state is managed internally, test cases can focus on the public interface and the expected outcomes. This leads to more reliable automated testing suites and faster feedback loops during development.
⚠️ Common Challenges and Anti-Patterns
While encapsulation is beneficial, it is not without its pitfalls. Misapplication can lead to rigid systems that are difficult to extend or overly complex interfaces that frustrate developers.
Over-Encapsulation
Sometimes, developers hide data that does not need to be hidden. This creates an excessive number of getters and setters, cluttering the codebase with boilerplate. If every variable requires a public method to access it, the interface becomes bloated.
God Objects
Conversely, some classes grow too large and attempt to manage everything. This violates encapsulation by creating a single point of failure that is difficult to understand or modify. A class should not know about too many other classes or manage too many distinct responsibilities.
Leaking Internals
A common mistake is returning internal objects directly from public methods. If a method returns a reference to an internal list, external code can modify that list, bypassing the object’s control mechanisms. To prevent this, developers should return copies of internal data or unmodifiable views.
📋 Best Practices for Implementation
To maximize the benefits of encapsulation, specific strategies should be adopted during the design and coding phases.
- Minimize Public Interfaces: Only expose what is necessary for the object to function correctly from the outside.
- Use Immutable Objects: When possible, make objects immutable. This removes the need for complex state management and getter/setter logic entirely.
- Validate Input: Perform all validation checks inside the object’s methods. Do not rely on the caller to ensure data validity.
- Hide Implementation Details: Do not expose internal algorithms or data structures. Use abstraction layers to present a clean API.
- Document Contracts: Clearly document the public interface. External developers should understand how to use the object without reading its source code.
🌐 Encapsulation in Distributed Systems
The principles of encapsulation extend beyond single-process applications into distributed architectures, such as microservices and cloud-native environments. In these contexts, the “object” becomes a service or an API endpoint.
API Boundaries
Just as a class should hide its internal variables, a service should hide its internal database schema or third-party dependencies. The API contract becomes the encapsulation boundary. Changes to the internal logic of a service should not require changes to the clients consuming that service, provided the contract remains stable.
State Management
In distributed systems, state management is critical. Encapsulation ensures that a service owns its state. Other services should not attempt to access the database of another service directly. They should communicate through defined interfaces. This prevents tight coupling and ensures that services can be deployed, scaled, and updated independently.
🔍 Analyzing the Impact of Tight vs. Loose Coupling
Encapsulation is the primary tool for managing coupling. Coupling refers to the degree of interdependence between software modules. High coupling makes systems fragile, while low coupling makes them robust.
| Aspect | High Coupling (Poor Encapsulation) | Low Coupling (Good Encapsulation) |
|---|---|---|
| Maintenance | Changes ripple across the system | Changes are isolated to specific modules |
| Reusability | Modules are difficult to reuse elsewhere | Modules can be easily moved to new projects |
| Testing | Requires complex setup and mocks | Can be tested in isolation easily |
| Security | Higher risk of data exposure | Data access is controlled and auditable |
Achieving low coupling through encapsulation requires discipline. It means resisting the temptation to share data structures between layers. Instead, data should be transformed as it moves between layers, ensuring that each layer only knows about its own domain model.
🚀 Future Proofing with Encapsulation
As software development trends evolve, encapsulation remains relevant. The shift towards component-based design, serverless architectures, and AI-driven code generation all rely on clear boundaries between logic and data.
Future systems will likely require even stricter boundaries. As automated testing and continuous integration become standard, the ability to swap out internal implementations without breaking the build is more valuable than ever. Encapsulation provides the flexibility needed to adopt new technologies without rewriting the entire application.
Furthermore, in the context of security compliance, many regulations require strict control over data access. Encapsulation provides the technical mechanism to enforce these compliance rules at the code level, ensuring that data handling follows legal requirements automatically.
📝 Summary of Key Takeaways
Understanding encapsulation is essential for any developer aiming to build high-quality software. It is not just a syntax feature but a design strategy that promotes safety, clarity, and longevity.
- Encapsulation is about control: It controls how data is accessed and modified.
- It enables change: Internal changes should not break external usage.
- It enhances security: It prevents unauthorized data access.
- It aids maintenance: It isolates complexity within specific modules.
- It supports scalability: It allows for modular growth of the system.
By adhering to these principles, developers can construct systems that are resilient to change and robust in operation. The effort invested in proper encapsulation during the design phase pays dividends throughout the entire lifecycle of the software product.
Remember that encapsulation is a balance. Too much can lead to rigidity, while too little leads to chaos. The goal is to find the sweet spot where data is protected, but the interface remains intuitive and efficient. This balance is the hallmark of mature software architecture.
As you continue to design and build systems, keep the principles of encapsulation at the forefront of your decision-making process. It is the foundation upon which reliable, secure, and maintainable software is built.