











Zrozumienie, jak informacje poruszają się przez system, jest kluczowe dla każdego analityka lub programisty. Diagram przepływu danych (DFD) zapewnia wizualne przedstawienie tego ruchu. Pokazuje, skąd pochodzą dane, jak się zmieniają i gdzie się kończą. Niniejszy przewodnik przedstawia proces tworzenia tych diagramów z dokładnością i jasnością.
Dlaczego wizualizować przepływ danych? 📊
Zanim podniesiesz długopis lub otworzysz płótno, konieczne jest zrozumienie celu diagramu. DFD nie jest schematem blokowym. Nie pokazuje przepływu sterowania ani decyzji logicznych. Zamiast tego skupia się ściśle na przepływie danych. Ta różnica jest kluczowa dla zachowania dokładności.
Wizualizacja przepływu danych oferuje kilka konkretnych korzyści:
- Przejrzystość:Złożone systemy stają się łatwiejsze do zrozumienia, gdy zostaną podzielone na elementy wizualne.
- Komunikacja:Stakeholderzy mogą omawiać zachowanie systemu bez potrzeby znajomości kodu.
- Analiza luk:Brakujące magazyny danych lub niepotrzebne przepływy stają się widoczne w trakcie rysowania projektu.
- Dokumentacja:Diagram służy jako żywy zapis wymagań systemu.
Główne elementy diagramu przepływu danych 🧩
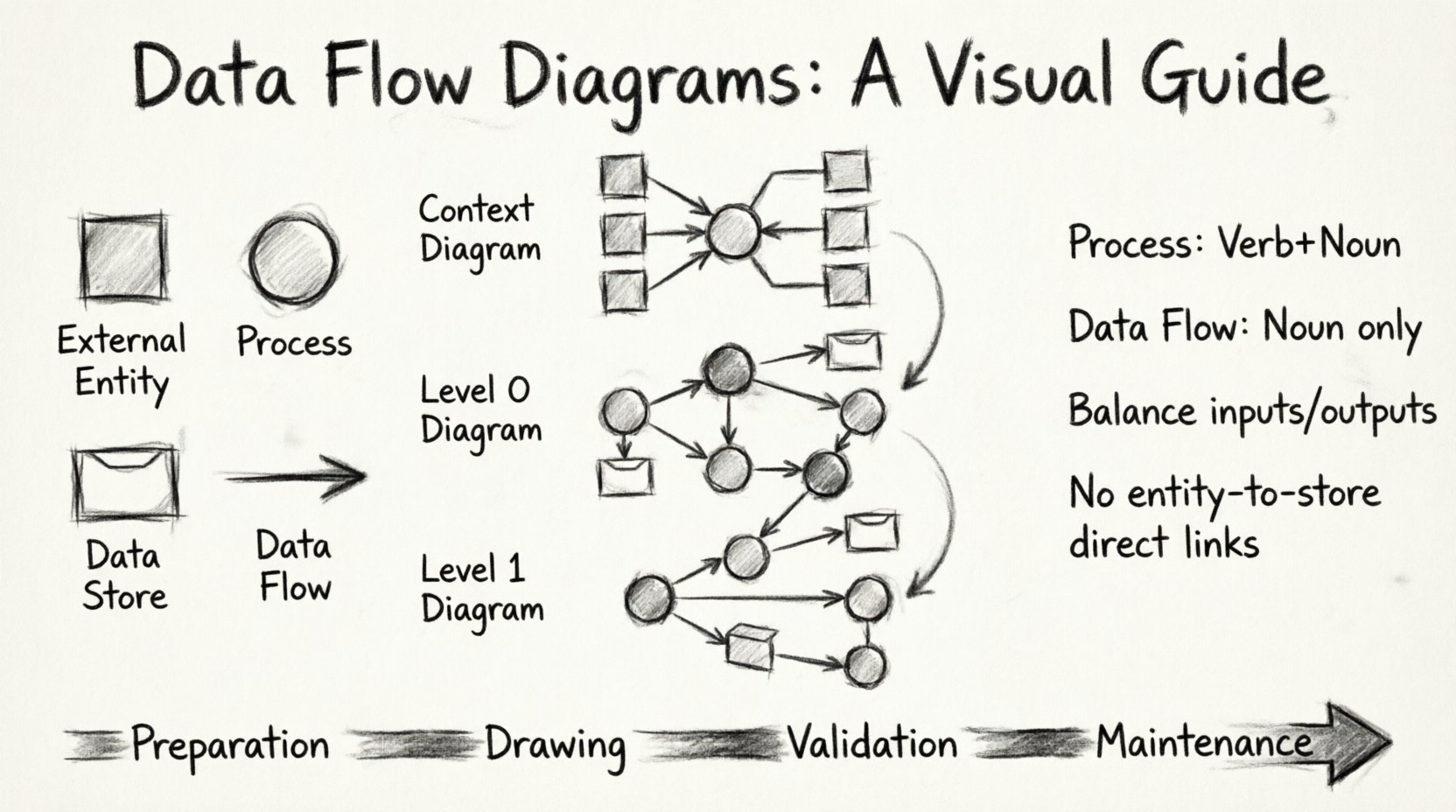
Każdy DFD opiera się na czterech standardowych symbolach. Te symbole tworzą słownictwo diagramu. Poprawne ich użycie zapewnia, że każdy czytający wykres rozumie architekturę systemu.
1. Jednostka zewnętrzna (źródło lub cel)
Jednostki zewnętrzne reprezentują ludzi, organizacje lub inne systemy, które współdziałają z procesem. Znajdują się poza granicą systemu. Dane wpływają do systemu z nich lub wypływają do nich. Zazwyczaj są one rysowane jako kwadraty lub prostokąty.
2. Proces (przekształcenie)
Proces zmienia dane. Przyjmuje dane wejściowe, wykonuje obliczenie lub działanie i generuje dane wyjściowe. To serce diagramu. Procesy są zwykle przedstawiane jako okręgi lub prostokąty z zaokrąglonymi rogami. Każdy proces musi mieć co najmniej jedno dane wejściowe i jedno wyjściowe.
3. Magazyn danych (repozytorium)
Magazyny danych przechowują informacje do późniejszego użycia. W przeciwieństwie do procesów nie przekształcają danych – po prostu je chronią. Przykłady to bazy danych, pliki lub kolejki. Często są one przedstawiane jako otwarte prostokąty lub równoległe linie.
4. Przepływ danych (połączenie)
Przepływy danych reprezentują ruch informacji. Strzałki wskazują kierunek. Każdy przepływ musi być oznaczony frazą rzeczownikową opisującą dane, a nie czasownikiem. Na przykład „Szczegóły zamówienia” jest poprawne, natomiast „Przetwarzanie zamówienia” jest błędne.
Faza przygotowania 📝
Zaczynanie rysowania od razu często prowadzi do zamieszania. Przygotowanie zapewnia, że diagram pozostanie przejrzysty. Postępuj zgodnie z tymi krokami przed narysowaniem pierwszej linii.
Zdefiniuj granice systemu
Zidentyfikuj, co znajduje się wewnątrz systemu, a co poza nim. Wszystko wewnątrz granicy jest zarządzane przez oprogramowanie lub proces. Wszystko poza granicą jest zewnętrzne. Ta granica pomaga określić, gdzie umieścić jednostki zewnętrzne.
Zbierz źródła informacji
Przejrzyj istniejącą dokumentację, przeprowadź rozmowy z stakeholderami i przeanalizuj obecne przepływy pracy. Musisz wiedzieć, jakie dane wchodzą do systemu i jakie wyniki są oczekiwane. Bez dokładnych danych wejściowych diagram będzie spekulatywny.
Krok 1: Diagram kontekstowy 🌍
Diagram kontekstowy to widok najwyższego poziomu. Pokazuje cały system jako pojedynczy proces oraz jednostki zewnętrzne, które z nim współpracują. Jest to punkt wyjścia dla każdego DFD.
- Zidentyfikuj pojedynczy proces:Narysuj okrąg lub kropkę reprezentującą całą system. Nadaj mu nazwę, np. „System zarządzania zamówieniami”.
- Umieść jednostki zewnętrzne:Narysuj prostokąty dla wszystkich użytkowników, działów lub zewnętrznych systemów zaangażowanych. Przykłady to „Klient”, „Magazyn” lub „Brama płatności”.
- Narysuj przepływy danych:Połącz jednostki z głównym procesem za pomocą strzałek. Oznacz każdą strzałkę danymi wymienianymi. Upewnij się, że strzałki są dwukierunkowe, jeśli dane są wysyłane i odbierane.
- Zweryfikuj kompletność:Sprawdź, czy każdy zewnętrzny kontakt został uwzględniony. Jeśli jednostka wysyła dane, ale nie otrzymuje żadnych, sprawdź, czy brakuje odpowiedzi.
Krok 2: Diagram poziomu 0 (poziom najwyższego) 🏗️
Po ustaleniu kontekstu rozłóż pojedynczy proces na główne podprocesy. Nazywa się to diagramem poziomu 0. Dzieli system na główne obszary funkcjonalne.
- Rozłóż proces:Zastąp pojedynczy proces kontekstowy trzema do siedmiu głównymi procesami. Unikaj zbyt wielu, ponieważ powoduje to zamieszanie, albo zbyt mało, ponieważ brakuje szczegółów.
- Zidentyfikuj magazyny danych:Określ, gdzie dane muszą być zapisane na tym poziomie. Umieść magazyny danych pomiędzy procesami, w których dane są pobierane lub przechowywane.
- Połącz przepływy:Narysuj strzałki między procesami, jednostkami i magazynami. Upewnij się, że każdy proces ma wejście i wyjście.
- Zachowaj równowagę:Wejścia i wyjścia na tym poziomie muszą odpowiadać diagramowi kontekstowemu. Jeśli diagram kontekstowy pokazuje „Zamówienie” wchodzące, diagram poziomu 0 musi pokazywać „Zamówienie” wchodzące do jednego z podprocesów.
Krok 3: Rozkład na poziom 1 i dalej 🔍
Jeśli proces na diagramie poziomu 0 jest złożony, wymaga dalszego rozkładu. Tworzy to diagram poziomu 1. Możesz kontynuować ten proces, aż procesy będą wystarczająco proste, aby bezpośrednio je zaimplementować.
Zasady rozkładu
- Jeden proces naraz:Skup się na rozkładzie jednego podprocesu przed przejściem do następnego. Nie próbuj narysować całego systemu naraz.
- Zachowaj przepływy:Gdy rozkładasz proces na mniejsze, dane wpływające do oryginalnego procesu muszą wpływać do nowych podprocesów. Dane wypływające muszą pochodzić z nowych podprocesów.
- Ogranicz szczegółowość:Przestań rozkładać, gdy logika jest wystarczająco jasna, by programista mógł ją zaimplementować bez dodatkowych wyjaśnień. Zazwyczaj trzy poziomy są wystarczające dla większości systemów.
Zasady nazewnictwa i najlepsze praktyki 🏷️
Spójne nazewnictwo czyni diagram czytelnym. Niespójne nazewnictwo prowadzi do zamieszania i błędów.
Nazwy procesów
Nazwy procesów powinny składać się z czasownika następującego po rzeczowniku. Przykłady to „Weryfikuj Użytkownika”, „Oblicz Podatek” lub „Generuj Raport”. Wskazuje to na działanie. Unikaj nieprecyzyjnych nazw takich jak „System” lub „Dane”. Używaj czasowników w formie czynnej, aby opisać przekształcenie.
Nazwy przepływów danych
Nazwy przepływów danych powinny być rzeczownikami lub frazami rzeczownikowych. Przykłady to „ID Klienta”, „Faktura” lub „Potwierdzenie Płatności”. Unikaj czasowników takich jak „Wyślij Fakturę”, ponieważ przepływ to same dane, a nie działanie. Działaniem jest proces.
Nazwy encji
Zewnętrzne encje powinny być rzeczownikami liczby pojedynczej lub mnogiej reprezentującymi wykonawcę. Używaj „Klient”, a nie „Dane Klienta”. Używaj „Magazyn”, a nie „Zarządzanie Magazynem”. Encja to wykonawca, a nie dane.
Zasady i ograniczenia przepływów danych ⚖️
Przestrzeganie rygorystycznych zasad zapobiega błędom logicznym w projektowaniu. Te ograniczenia zapewniają, że schemat reprezentuje poprawny system.
| Zasada | Opis |
|---|---|
| Wejście do magazynu danych | Dane mogą być zapisywane tylko do magazynu z procesu. Bezpośrednie przepływy między encjami a magazynami są zazwyczaj niedozwolone. |
| Wyjście z magazynu danych | Dane mogą być odczytywane tylko z magazynu przez proces. Encje nie mogą bezpośrednio uzyskiwać dostępu do magazynów. |
| Wejście/Wyjście procesu | Każdy proces musi mieć co najmniej jedno wejście i jedno wyjście. Proces, który pochłania dane bez ich wydawania, to „czarna dziura”. Proces, który tworzy dane bez wejścia, to „magiczne źródło”. Oba przypadki są błędami. |
| Przecięcie przepływów danych | Przepływy danych nie powinny bezpośrednio przecinać magazynów danych ani zewnętrznych encji. Muszą przechodzić przez proces. |
Weryfikacja i przegląd ✅
Po narysowaniu schematu musi zostać zweryfikowany. Ten krok zapewnia, że model odpowiada rzeczywistości.
Sprawdź zrównoważenie
Porównaj wejścia i wyjścia procesu nadrzędnego z wejściami i wyjściami jego procesów potomnych. Dane wejściowe do procesu nadrzędnego muszą być równe danym wejściowym do procesów potomnych. Dane wyjściowe z procesu nadrzędnego muszą być równe danym wyjściowym z procesów potomnych. Jeśli nie są równe, schemat jest niereprezentatywny i wymaga korekty.
Sprawdź kompletność
Przejrzyj każdy przepływ danych. Czy każda część danych ma docelowy punkt? Czy każdy proces ma źródło? Czy istnieją niezwiązane magazyny danych? Pełny schemat nie ma wolnych końców.
Weryfikacja przez zainteresowane strony
Pokaż schemat osobom, które korzystają z systemu. Poproś je o prześledzenie przepływu danych. Czy zgadzają się z trasą? Czy identyfikują brakujące kroki? Ich opinia jest ostatecznym testem dokładności.
Utrzymanie schematu 🔄
Schemat DFD to nie jednorazowa praca. Systemy się rozwijają, a wymagania się zmieniają. Schemat musi się rozwijać razem z nimi.
- Kontrola wersji: Śledź zmiany. Oznacz wersje datami lub numerami.
- Regularnie aktualizuj: Zawsze, gdy dodawana jest nowa funkcja lub zmienia się proces, natychmiast aktualizuj schemat przepływu danych (DFD).
- Archiwizuj stare wersje: Przechowuj starsze schematy jako odniesienie podczas audytów lub debugowania.
Wnioski dotyczące dokładności wizualnej 🎯
Tworzenie schematu przepływu danych to dyscyplinowane ćwiczenie logiczne i wizualne. Wymaga cierpliwości, aby rozłożyć złożone systemy na zrozumiałe części. Postępując zgodnie z powyższymi krokami, możesz stworzyć schemat, który będzie wiarygodnym projektem dla rozwoju i komunikacji.
Cel nie polega tylko na rysowaniu linii, ale na zrozumieniu przepływu. Gdy przepływy danych są jasne, projekt systemu staje się jasny. Ta przejrzystość zmniejsza błędy i poprawia ostateczny produkt. Skup się na danych, a nie na kodzie, i schemat spełni swoje zadanie skutecznie.