











W nowoczesnych systemach rozproszonych niezawodność usługi backendowej często zależy od tego, jak dobrze obsługuje ona równoczesne żądania i współdzielone zasoby. Jednym z najbardziej utrzymujących się i trudnych do odtworzenia problemów w tym obszarze jest zakleszczenie. Zawieszenie występuje, gdy dwa lub więcej procesów nie mogą kontynuować działania, ponieważ każdy czeka na zwolnienie zasobu przez drugi. Ten stan trwałego zablokowania może spowodować całkowity zatrzymanie systemu, co prowadzi do niezgodności danych, niedostępności usługi i frustracji użytkowników. Aby zmniejszyć te ryzyka, architekci i inżynierowie muszą wyjść poza proste przeglądy kodu i zastosować wizualne podejście do projektowania systemu. Diagramy komunikacji zapewniają strukturalny sposób mapowania interakcji, identyfikacji potencjalnych punktów zawieszenia i wprowadzania wzorców odporności jeszcze przed napisaniem kodu.
Ten przewodnik bada mechanizmy zakleszczeń w środowiskach backendowych i pokazuje, jak diagramy komunikacji mogą działać jako narzędzie zapobiegawcze. Poprzez wizualizację przepływu sterowania i nabycia zasobów zespoły mogą wykrywać cykliczne zależności i implementować strategie ich rozwiązania. Omówimy podstawy teoretyczne, praktyczne techniki wizualizacji oraz konkretne wzorce architektoniczne wspierające odporność systemu.
Zrozumienie mechanizmów zakleszczenia 🛑
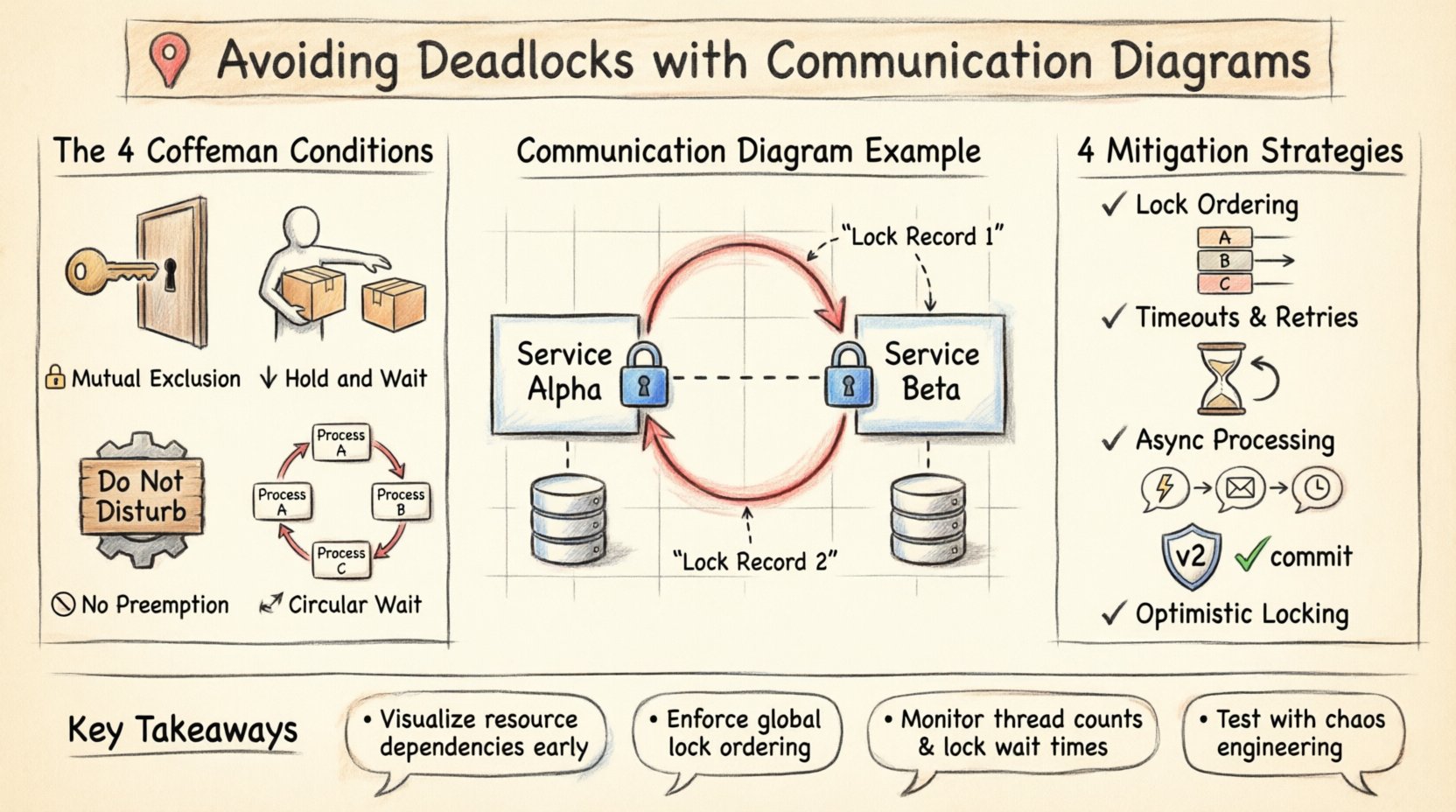
Zanim przejdziemy do zapobiegania, konieczne jest zrozumienie warunków, które powodują zakleszczenie. W informatyce zakleszczenie nie jest zdarzeniem przypadkowym; jest wynikiem jednoczesnego wystąpienia określonego zestawu warunków. Są one często nazywane warunkami Coffmana. Aby zakleszczenie mogło istnieć, wszystkie cztery poniższe warunki muszą być spełnione:
- Wyłączność wzajemna: Przynajmniej jeden zasób musi być używany w trybie nieudostępnianym. W danym momencie tylko jeden proces może korzystać z zasobu.
- Zachowaj i czekaj: Proces musi trzymać przynajmniej jeden zasób, jednocześnie czekając na nabycie dodatkowych zasobów, które są używane przez inne procesy.
- Brak wywłaszczenia: Zasoby nie mogą być wymuszenie zabierane od procesu. Muszą zostać zwolnione dobrowolnie przez proces, który je trzyma.
- Cykliczne czekanie: Istnieje zbiór procesów, w którym P1 czeka na P2, P2 czeka na P3 i tak dalej, aż Pn czeka na P1.
W aplikacji jednowątkowej zakleszczenie jest rzadkie. Jednak w systemach backendowych obsługujących tysiące równoczesnych żądań te warunki są łatwo spełnione. Na przykład, jeśli Usługa A trzyma blokadę na Zasobie X i czeka na Zasób Y, a Usługa B trzyma Zasób Y i czeka na Zasób X, powstaje cykliczne czekanie. Bez wywłaszczenia lub starannego porządkowania system zamarza.
Rola diagramów komunikacji 📊
Diagramy komunikacji to rodzaj diagramu języka modelowania jednolitego (UML). Podczas gdy diagramy sekwencji skupiają się na czasie przekazywania wiadomości, diagramy komunikacji podkreślają strukturalną organizację obiektów oraz połączenia między nimi. W kontekście odporności backendu ta strukturalna perspektywa jest kluczowa. Pozwala projektantom zobaczyćktorozmawia zkimijakiezasoby są wymieniane, a nie tylko kolejność, w jakiej wiadomości przychodzą.
Podczas projektowania architektury mikroserwisów lub skomplikowanego backendu monolitycznego diagramy komunikacji pomagają odpowiedzieć na kluczowe pytania:
- Które usługi wymagają dostępu wyłącznego do tej samej tabeli bazy danych?
- Czy istnieją wzajemne zależności między dwoma jednostkami przetwarzania?
- Czy łańcuch żądań powraca do nadawcy przed zakończeniem?
- Jaka jest maksymalna głębokość zagnieżdżonego blokowania zasobów?
Mapując te interakcje wczesnym etapie projektowania, zespoły mogą wykryć potencjalne scenariusze zakleszczeń, które mogą być niewidoczne w przeglądzaniu kodu wyłącznie z punktu widzenia kodu. Diagram działa jak umowa interakcji, wyrzucając na jaw ukryte założenia.
Mapowanie zależności zasobów 🗺️
Aby skutecznie wykorzystać diagramy komunikacji do unikania zakleszczeń, diagram musi przedstawiać zasoby, a nie tylko przepływ danych. Standardowe diagramy interakcji często pokazują wywołania między usługami. Jednak do analizy blokad musimy oznaczać połączenia identyfikatorami zasobów. Wymaga to nieco wyższego poziomu abstrakcji, w którym węzły reprezentują procesy lub wątki, a połączenia – współdzielone zasoby lub kanały komunikacji.
Kroki tworzenia diagramu świadomego zakleszczeń
- Zidentyfikuj krytyczne zasoby: Wylicz wszystkie współdzielone stany, takie jak wiersze bazy danych, deskryptory plików lub bufor pamięci. Przypisz im unikalne identyfikatory.
- Zdefiniuj własność: Określ, który serwis lub wątek aktualnie kontroluje który zasób. Zaznacz to na diagramie.
- Śledź ścieżki nabycia zasobów: Narysuj strzałki wskazujące żądanie zasobu. Oznacz strzałkę nazwą zasobu.
- Wyróżnij stany oczekiwania: Użyj specjalnej notacji, aby pokazać, kiedy proces jest zablokowany i oczekuje na zasób.
- Analizuj cykle: Szukaj zamkniętych pętli na diagramie, gdzie Proces A oczekuje na Proces B, który oczekuje na Proces A.
Identyfikowanie wzorców cyklicznego oczekiwania 🔁
Najbardziej niebezpiecznym wzorcem w projektowaniu systemu jest cykliczna zależność. Na diagramie komunikacji pojawia się jako zamknięta pętla interakcji. Rozważ sytuację z dwoma serwisami, Serwisem Alpha i Serwisem Beta.
- Serwis Alpha inicjuje transakcję i blokuje Rekord 1.
- Serwis Alpha żąda blokady Rekordu 2 od Serwisu Beta.
- Serwis Beta już posiada blokadę Rekordu 2, ale potrzebuje zaktualizować Rekord 1, który jest zablokowany przez Alpha.
Na wizualnym przedstawieniu ta pętla jest od razu widoczna. Diagram pokazuje, że Alpha wskazuje na Beta, a Beta zwraca się do Alpha, oba żądając zasobu zablokowanego przez drugą stronę. Bez diagramu ta logika mogła zostać wykryta jedynie podczas awarii w środowisku produkcyjnym lub trudnego testu obciążeniowego.
Typowe sytuacje prowadzące do cykliczności
- Propagacja transakcji: Gdy transakcja rozproszona wymaga, by wiele serwisów zatwierdziło w określonej kolejności, ale ta kolejność nie jest wymuszana.
- Zagnieżdżone wywołania: Funkcja wywołuje inną funkcję, która w końcu wywołuje oryginalną funkcję, tworząc łańcuch rekurencyjnych blokad.
- Współdzielony bufor: Wiele serwisów próbujących jednocześnie zaktualizować tę samą wpis w buforze bez mechanizmu rozproszonej blokady.
- Klucze obce bazy danych: Aktualizacje powiązanych tabel, które wymagają blokad na obu tabelach, gdzie kolejność aktualizacji różni się między serwisami.
Strategiczne techniki łagodzenia 🛠️
Gdy diagram komunikacji ujawni potencjalne zakleszczenie, wymagane są konkretne zmiany architektoniczne. Nie ma jednej uniwersalnej metody pasującej do każdego systemu, ale istnieje kilka sprawdzonych strategii umożliwiających złamanie warunków Coffmana.
1. Porządkowanie blokad
Jest to najskuteczniejsza metoda zapobiegania cyklicznemu oczekiwaniu. System musi wymuszać globalne uporządkowanie zasobów. Jeśli każdy proces żąda zasobów w tej samej kolejności (np. Zasób A przed Zasobem B), cykl nie może się utworzyć. Na diagramie komunikacji oznacza to zapewnienie, że wszystkie połączenia żądające Zasobu X są ustanowione przed jakimkolwiek połączeniem żądającym Zasobu Y.
2. Limitowanie czasu i ponowne próby
Nawet przy ustalonym porządku może dojść do zawierania. Wprowadzenie limitu czasu przy nabywaniu zasobu zapewnia, że proces nie czeka bez końca. Jeśli blokada nie może zostać nabyta w określonym czasie, proces zwalnia aktualne zasoby i ponawia próbę. Zapobiega to trwałemu zablokowaniu systemu, choć może wprowadzić opóźnienia.
3. Przetwarzanie asynchroniczne
Przejście od synchronicznych żądań do architektury asynchronicznej opartej na zdarzeniach może zmniejszyć zawieranie. Zamiast czekać na zwolnienie blokady, usługa publikuje zdarzenie i kontynuuje przetwarzanie. Gdy zasób stanie się dostępny, odbiorca przetwarza aktualizację. Dzięki temu rozłącza się czas używania zasobu.
4. Optymistyczne blokowanie
Zamiast nabywać blokadę przed odczytem lub modyfikacją danych, system sprawdza konflikty w momencie zatwierdzenia. Jeśli inny proces zmodyfikował dane od momentu odczytu, transakcja kończy się niepowodzeniem i musi zostać ponowiona. Zmniejsza to czas trzymania blokad, minimalizując okno wystąpienia zakleszczenia.
Porównanie strategii zapobiegania
| Strategia | Zapobiega warunkowi | Złożoność | Wpływ na wydajność |
|---|---|---|---|
| Kolejność blokad | Cykliczne oczekiwanie | Wysoka | Niska |
| Limit czasu | Trzymanie i oczekiwanie (pośrednio) | Niska | Średnia (ponowne próby) |
| Optymistyczne blokowanie | Wyłączność wzajemna (długoterminowa) | Średnia | Zmienne |
| Przepływ asynchroniczny | Trzymanie i oczekiwanie | Wysoka | Niska |
Kroki wdrożenia analizy opartej na diagramie
Aby zintegrować tę metodę z procesem tworzenia oprogramowania, wykonaj następujące kroki:
- Przeprowadź przeglądarkę projektu: Przed napisaniem kodu utwórz diagram komunikacji dla nowych funkcji. Skup się na ścieżkach dostępu do danych.
- Zaznacz użycie zasobów:Zaznacz każde zapisywanie do bazy danych, aktualizację pamięci podręcznej lub operację plikową na diagramie.
- Uruchom algorytm wykrywania cykli:Jeśli używasz narzędzi automatycznych, zastosuj algorytmy grafowe do wykrywania cykli w grafie zależności pochodzących z diagramu.
- Przepisz kod dla niezależności:Jeśli wykryto cykl, przepisz kod w celu zerwania zależności. Może to obejmować wprowadzenie usługi mediatora lub zmianę modelu danych.
- Weryfikuj przy użyciu testów obciążeniowych:Symuluj wysoką konkurencję, aby upewnić się, że wzorce zakleszczenia nie pojawiają się pod obciążeniem.
Monitorowanie i obserwacja 🧪
Nawet przy starannym projekcie warunki uruchomieniowe mogą się zmieniać. Narzędzia monitorowania powinny być skonfigurowane w celu wykrywania objawów zakleszczenia. Kluczowe metryki obejmują:
- Liczba wątków:Nagle zwiększenie liczby zablokowanych wątków może wskazywać na konkurencję o zasoby.
- Czas oczekiwania na blokadę:Jeśli średni czas uzyskania blokady znacznie wzrasta, konkurencja rośnie.
- Anulowania transakcji:Wysoka liczba anulowań transakcji z powodu przekroczenia limitu czasu lub konfliktu wskazuje, że strategie blokowania są zbyt agresywne.
- Dzienniki wykrywania zakleszczeń:Niektóre silniki baz danych i systemy operacyjne rejestrują zdarzenia zakleszczeń. Te dzienniki powinny być zintegrowane z centralnym systemem logowania.
Przykład studium przypadku: przepływ interakcji między usługami
Zastanów się nad ogólnym backendem e-commerce obsługującym zamówienia i zapasy. Usługa A obsługuje zamówienia, a Usługa B obsługuje zapasy.
Scenariusz:Usługa A tworzy zamówienie i blokuje identyfikator zamówienia. Następnie wywołuje usługę B w celu zarezerwowania zapasów. Usługa B blokuje identyfikator zapasu. Aby zaktualizować status zamówienia, usługa B musi wysłać wywołanie zwrotne do usługi A, co wymaga ponownego zablokowania identyfikatora zamówienia.
Zakleszczenie:Jeśli usługa A trzyma identyfikator zamówienia i czeka na zwolnienie identyfikatora zapasu przez usługę B, ale usługa B nie może zakończyć działania bez zwolnienia identyfikatora zamówienia przez usługę A (poprzez wywołanie zwrotne), następuje zakleszczenie. Jest to scenariusz zagnieżdżonej blokady.
Rozwiązanie:Używając diagramu komunikacji, ten cykl jest widoczny. Rozwiązanie polega na zerwaniu zależności. Usługa B powinna aktualizować zapas asynchronicznie lub używać osobnego identyfikatora transakcji, który nie wymaga ponownego zablokowania identyfikatora zamówienia trzymanego przez usługę A. Diagram pokazywałby wtedy jednokierunkowy przepływ od A do B, bez drogi powrotnej wymagającej pierwotnej blokady.
Rozważania dotyczące blokowania rozproszonego
W środowiskach rozproszonych blokady są często zarządzane przez zewnętrzne usługi, a nie samą aplikację. Oznacza to wprowadzenie opóźnień sieciowych oraz ryzyko częściowych awarii. Diagramy komunikacji muszą uwzględniać połączenie sieciowe jako potencjalny punkt awarii. Jeśli połączenie między usługą A a menedżerem blokad ulegnie awarii, usługa A może myśleć, że trzyma blokadę, podczas gdy inną usługę ją trzyma.
Aby temu zaradzić, diagram powinien zawierać węzeł „Menedżer blokad”. Interakcje z tym węzłem muszą być idempotentne i ograniczone czasowo. Projekt musi zapewnić, że w przypadku awarii usługi blokada zostanie automatycznie zwolniona po wygaśnięciu okresu wynajmu. Zapobiega to niekończącemu się stanowi „Trzymaj i czekaj”.
Testowanie odporności
Diagramy projektowe są teoretyczne. Wymagane jest testowanie w świecie rzeczywistym w celu zweryfikowania odporności. Obejmuje to:
- Inżynieria chaosu: Celowo wprowadzaj opóźnienia lub awarie w łącza sieciowe pokazane na diagramie, aby sprawdzić, czy system odzyskuje się, czy zawiesza się.
- Testowanie obciążeniowe: Uruchamiaj równoległe żądania odpowiadające wzorcom zidentyfikowanym na diagramie, aby zweryfikować, czy kolejność blokad działa pod obciążeniem.
- Analiza statyczna: Używaj narzędzi do analizy kodu pod kątem potencjalnych naruszeń kolejności blokad, które odpowiadają logice diagramu.
Wnioski
Unikanie zakleszczeń to nie tylko ćwiczenie programistyczne; to wyzwanie związane z projektowaniem systemu. Wykorzystując diagramy komunikacji, zespoły mogą wizualizować skomplikowaną sieć zależności zasobów prowadzących do zamarznięcia systemu. Ten podejście przesuwa uwagę z reaktywnej diagnostyki na zapobieganie. Zrozumienie czterech warunków zakleszczenia, mapowanie ścieżek nabycia zasobów oraz wprowadzanie ściśle określonej kolejności lub wzorców asynchronicznych to istotne kroki w budowaniu odpornego zaplecza. Choć żaden system nie jest odporny na problemy współbieżności, strukturalny podejście wizualne znacznie zmniejsza ryzyko i złożoność zarządzania współdzielonymi zasobami. Spójne stosowanie tych zasad zapewnia, że usługi pozostają reaktywne, a dane pozostają spójne, nawet pod dużym obciążeniem i warunkami awarii.