











En los sistemas distribuidos modernos, la confiabilidad de un servicio de backend depende en gran medida de la forma en que maneja las solicitudes concurrentes y los recursos compartidos. Una de las cuestiones más persistentes y difíciles de reproducir en este ámbito es el interbloqueo. Un interbloqueo ocurre cuando dos o más procesos no pueden continuar porque cada uno espera que el otro libere un recurso. Este estado de bloqueo permanente puede detener todo un sistema, causando inconsistencia de datos, indisponibilidad del servicio y frustración del usuario. Para mitigar estos riesgos, los arquitectos e ingenieros deben ir más allá de revisiones simples de código y adoptar un enfoque visual en el diseño del sistema. Los diagramas de comunicación proporcionan una forma estructurada para mapear interacciones, identificar puntos de posible contención y aplicar patrones de resiliencia antes incluso de escribir código.
Esta guía explora la mecánica de los interbloqueos dentro de entornos de backend y demuestra cómo los diagramas de comunicación pueden servir como una herramienta preventiva. Al visualizar el flujo de control y la adquisición de recursos, los equipos pueden detectar dependencias circulares e implementar estrategias para romperlas. Cubriremos las bases teóricas, técnicas prácticas de visualización y patrones arquitectónicos específicos que contribuyen a un sistema resiliente.
Comprender la mecánica de un interbloqueo 🛑
Antes de abordar la prevención, es necesario comprender las condiciones que generan un interbloqueo. En ciencias de la computación, un interbloqueo no es un evento aleatorio; es el resultado de un conjunto específico de condiciones que ocurren simultáneamente. A menudo se les conoce como las condiciones de Coffman. Para que exista un interbloqueo, deben cumplirse simultáneamente las cuatro siguientes condiciones:
- Exclusión mutua: Al menos un recurso debe mantenerse en un modo no compartible. Solo un proceso puede usar el recurso en cualquier momento dado.
- Retener y esperar: Un proceso debe estar reteniendo al menos un recurso mientras espera adquirir recursos adicionales que poseen otros procesos.
- Sin preemción: Los recursos no pueden ser retirados forzosamente de un proceso. Deben liberarse voluntariamente por el proceso que los posee.
- Espera circular: Existe un conjunto de procesos de tal forma que P1 está esperando a P2, P2 está esperando a P3, y así sucesivamente, hasta que Pn está esperando a P1.
En una aplicación de un solo hilo, los interbloqueos son raros. Sin embargo, en sistemas de backend que manejan miles de solicitudes concurrentes, estas condiciones son fáciles de cumplir. Por ejemplo, si el Servicio A posee un bloqueo sobre el Recurso X y espera el Recurso Y, mientras que el Servicio B posee el Recurso Y y espera el Recurso X, se forma una espera circular. Sin preemción o un ordenamiento cuidadoso, el sistema se congela.
El papel de los diagramas de comunicación 📊
Los diagramas de comunicación son un tipo de diagrama del Lenguaje Unificado de Modelado (UML). Mientras que los diagramas de secuencia se centran en la cronología de los mensajes, los diagramas de comunicación enfatizan la organización estructural de los objetos y los enlaces entre ellos. En el contexto de la resiliencia del backend, esta visión estructural es crucial. Permite a los diseñadores verquién está hablando con quién y quérecursos se están intercambiando, más que simplemente el orden en que llegan los mensajes.
Al diseñar una arquitectura de microservicios o un backend monolítico complejo, los diagramas de comunicación ayudan a responder preguntas críticas:
- ¿Qué servicios requieren acceso exclusivo a la misma tabla de base de datos?
- ¿Existen dependencias bidireccionales entre dos unidades de procesamiento?
- ¿La cadena de solicitudes vuelve al origenador antes de completarse?
- ¿Cuál es la profundidad máxima de bloqueo anidado de recursos?
Al mapear estas interacciones desde una fase temprana del diseño, los equipos pueden identificar escenarios potenciales de interbloqueo que podrían pasar desapercibidos en una revisión puramente centrada en código. El diagrama actúa como un contrato de interacción, haciendo explícitas las suposiciones implícitas.
Mapeo de dependencias de recursos 🗺️
Para utilizar eficazmente los diagramas de comunicación en la prevención de interbloqueos, el diagrama debe representar recursos, no solo el flujo de datos. Los diagramas de interacción estándar suelen mostrar llamadas entre servicios. Sin embargo, para analizar bloqueos, debemos anotar los enlaces con identificadores de recursos. Esto requiere un nivel ligeramente más alto de abstracción, donde los nodos representan procesos o hilos, y los enlaces representan recursos compartidos o canales de comunicación.
Pasos para crear un diagrama consciente de bloqueos
- Identifique los recursos críticos: Liste todos los estados compartidos, como filas de base de datos, manejadores de archivos o búferes de memoria. Asigne identificadores únicos a ellos.
- Defina la propiedad: Determine qué servicio o hilo controla actualmente cada recurso. Marque esto en el diagrama.
- Rastree las rutas de adquisición: Dibuje flechas que indiquen la solicitud de un recurso. Etiquete la flecha con el nombre del recurso.
- Resalte los estados de espera: Use una notación específica para mostrar cuándo un proceso está bloqueado esperando un recurso.
- Analice los ciclos: Busque bucles cerrados en el diagrama donde el Proceso A espera al Proceso B, que a su vez espera al Proceso A.
Identificación de patrones de espera circular 🔁
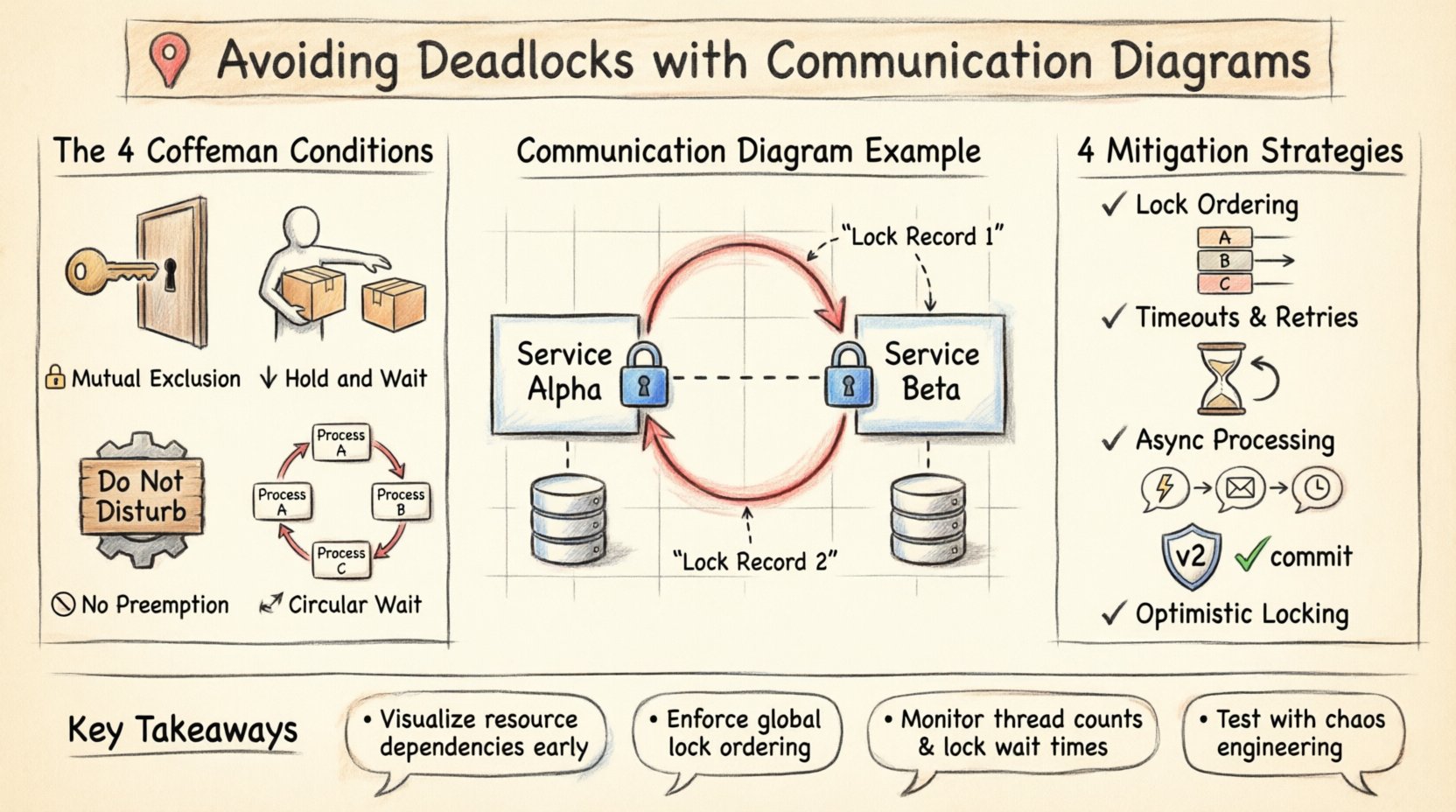
El patrón más peligroso en el diseño de sistemas es la dependencia circular. En un diagrama de comunicación, esto aparece como un bucle cerrado de interacciones. Considere una escena que involucra dos servicios, el Servicio Alfa y el Servicio Beta.
- El Servicio Alfa inicia una transacción y bloquea el Registro 1.
- El Servicio Alfa solicita un bloqueo sobre el Registro 2 al Servicio Beta.
- El Servicio Beta ya posee un bloqueo sobre el Registro 2, pero necesita actualizar el Registro 1, que está bloqueado por Alfa.
En una representación visual, este bucle es inmediatamente evidente. El diagrama muestra a Alfa apuntando a Beta, y Beta apuntando de vuelta a Alfa, ambos exigiendo el recurso poseído por el otro. Sin un diagrama, esta lógica solo podría detectarse durante una interrupción en producción o una prueba de estrés compleja.
Escenarios comunes que conducen a circularidad
- Propagación de transacciones: Cuando una transacción distribuida requiere que múltiples servicios se comprometan en un orden específico, pero ese orden no se aplica.
- Llamadas anidadas: Una función llama a otra función que finalmente vuelve a llamar a la función original, creando una cadena de bloqueos recursiva.
- Caché compartida: Múltiples servicios que intentan actualizar la misma entrada en caché simultáneamente sin un mecanismo de bloqueo distribuido.
- Claves foráneas de base de datos: Actualizaciones en tablas relacionadas que requieren bloqueos en ambas tablas, donde el orden de las actualizaciones difiere entre servicios.
Técnicas estratégicas de mitigación 🛠️
Una vez que un diagrama de comunicación revela un posible bloqueo, se requieren cambios arquitectónicos específicos. No existe una única solución que se adapte a todos los sistemas, pero existen varias estrategias comprobadas para romper las condiciones de Coffman.
1. Ordenamiento de bloqueos
Este es el método más efectivo para prevenir la espera circular. El sistema debe imponer un orden global de recursos. Si cada proceso solicita recursos en el mismo orden (por ejemplo, el Recurso A antes que el Recurso B), no puede formarse un ciclo. En un diagrama de comunicación, esto significa asegurarse de que todos los enlaces que solicitan el Recurso X se establezcan antes de que cualquier enlace solicite el Recurso Y.
2. Tiempos de espera y reintentos
Incluso con ordenamiento, es posible la contención. Implementar un tiempo de espera en la adquisición de recursos asegura que un proceso no espere indefinidamente. Si un bloqueo no puede adquirirse dentro de una duración especificada, el proceso libera sus recursos actuales y vuelve a intentarlo. Esto evita que el sistema se congele permanentemente, aunque podría introducir latencia.
3. Procesamiento asíncrono
Cambiar de solicitudes síncronas a arquitecturas asíncronas basadas en eventos puede reducir la contención. En lugar de esperar a que se libere un bloqueo, un servicio publica un evento y continúa el procesamiento. Cuando el recurso queda disponible, un consumidor maneja la actualización. Esto desacopla el momento del uso del recurso.
4. Bloqueo optimista
En lugar de adquirir un bloqueo antes de leer o modificar datos, el sistema verifica conflictos en el momento del commit. Si otro proceso ha modificado los datos desde la lectura, la transacción falla y debe reintentarse. Esto reduce el tiempo de retención de bloqueos, minimizando la ventana para un bloqueo.
Comparación de estrategias de prevención
| Estrategia | Prevención de condición | Complejidad | Impacto en el rendimiento |
|---|---|---|---|
| Ordenamiento de bloqueos | Espera circular | Alta | Baja |
| Tiempo de espera | Retener y esperar (de forma indirecta) | Baja | Media (reintentos) |
| Bloqueo optimista | Exclusión mutua (a largo plazo) | Media | Variable |
| Flujo asíncrono | Retener y esperar | Alta | Baja |
Pasos de implementación para el análisis basado en diagramas
Para integrar este enfoque en su flujo de trabajo de desarrollo, siga estos pasos:
- Realice una revisión de diseño: Antes de escribir código, crea el diagrama de comunicación para las nuevas características. Enfócate en las rutas de acceso a los datos.
- Anota el uso de recursos:Marca cada escritura en la base de datos, actualización de caché o operación de archivo en el diagrama.
- Ejecuta un algoritmo de detección de ciclos:Si se utilizan herramientas automatizadas, aplica algoritmos de grafos para detectar ciclos en el grafo de dependencias derivado del diagrama.
- Refactoriza para lograr independencia:Si se encuentra un ciclo, refactoriza el código para romper la dependencia. Esto podría implicar la introducción de un servicio mediador o el cambio del modelo de datos.
- Valida con pruebas de carga:Simula alta concurrencia para asegurarte de que los patrones de interbloqueo no se manifiesten bajo estrés.
Monitoreo y observabilidad 🧪
Aunque se cuente con un diseño cuidadoso, las condiciones en tiempo de ejecución pueden cambiar. Las herramientas de monitoreo deben configurarse para detectar señales de interbloqueo. Las métricas clave incluyen:
- Cantidad de hilos:Un aumento repentino en los hilos bloqueados puede indicar contención de recursos.
- Tiempo de espera para bloqueos:Si el tiempo promedio para adquirir un bloqueo aumenta significativamente, la contención está creciendo.
- Reversiones de transacción:Una tasa alta de reversiones debido a tiempo de espera o conflictos sugiere que las estrategias de bloqueo son demasiado agresivas.
- Registros de detección de interbloqueos:Algunos motores de bases de datos y sistemas operativos registran eventos de interbloqueo. Estos registros deben integrarse en el sistema central de registro.
Estudio de caso: Flujo de interacción entre servicios
Considera una plataforma de comercio electrónico genérica que maneja pedidos e inventario. El servicio A maneja pedidos, y el servicio B maneja inventario.
Escenario:El servicio A crea un pedido y bloquea el ID del pedido. Luego llama al servicio B para reservar inventario. El servicio B bloquea el ID del inventario. Para actualizar el estado del pedido, el servicio B necesita enviar una llamada de retorno al servicio A, lo que requiere bloquear nuevamente el ID del pedido.
El interbloqueo:Si el servicio A posee el ID del pedido y espera a que el servicio B libere el ID del inventario, pero el servicio B no puede completarse sin que el servicio A libere el ID del pedido (mediante la llamada de retorno), se produce un interbloqueo. Este es un escenario de bloqueo anidado.
La solución:Utilizando un diagrama de comunicación, este bucle es visible. La solución consiste en romper la dependencia. El servicio B debería actualizar el inventario de forma asíncrona o usar un ID de transacción separado que no requiera volver a bloquear el ID del pedido mantenido por el servicio A. El diagrama mostraría entonces un flujo unidireccional desde A hasta B, sin ruta de retorno que requiera el bloqueo original.
Consideraciones sobre bloqueos distribuidos
En entornos distribuidos, los bloqueos suelen gestionarse mediante servicios externos en lugar de la propia aplicación. Esto introduce latencia de red y el riesgo de fallos parciales. Los diagramas de comunicación deben tener en cuenta el enlace de red como un posible punto de fallo. Si el enlace entre el servicio A y el gestor de bloqueos falla, el servicio A podría pensar que posee el bloqueo mientras que otro servicio lo tiene.
Para abordar este problema, el diagrama debe incluir un nodo de “Gestor de bloqueos”. Las interacciones con este nodo deben ser idempotentes y con límite de tiempo. El diseño debe garantizar que si un servicio falla, el bloqueo se libere automáticamente después de que expire el tiempo de arrendamiento. Esto evita que la condición de “mantener y esperar” persista indefinidamente.
Pruebas para la resiliencia
Los diagramas de diseño son teóricos. Se requieren pruebas en el mundo real para validar la resiliencia. Esto incluye:
- Ingeniería de caos:Introducir intencionalmente latencia o fallos en los enlaces de red mostrados en el diagrama para ver si el sistema se recupera o entra en estado de bloqueo.
- Pruebas de estrés:Ejecutar solicitudes concurrentes que coincidan con los patrones identificados en el diagrama para verificar que el orden de bloqueo funcione bajo carga.
- Análisis estático:Utilizar herramientas para analizar la base de código en busca de posibles violaciones del orden de bloqueo que coincidan con la lógica del diagrama.
Conclusión
Evitar los bloqueos no es meramente un ejercicio de programación; es un desafío de diseño de sistemas. Mediante el uso de diagramas de comunicación, los equipos pueden visualizar la compleja red de dependencias de recursos que provocan congelamientos del sistema. Este enfoque desplaza la atención del depurado reactivo hacia la prevención proactiva. Comprender las cuatro condiciones de un bloqueo, mapear los caminos de adquisición de recursos y aplicar órdenes estrictas o patrones asíncronos son pasos esenciales para construir una infraestructura de backend resiliente. Aunque ningún sistema es inmune a los problemas de concurrencia, un enfoque visual estructurado reduce significativamente el riesgo y la complejidad de gestionar recursos compartidos. La aplicación constante de estos principios garantiza que los servicios permanezcan responsivos y los datos sigan siendo consistentes, incluso bajo cargas elevadas y condiciones de fallo.