











このチュートリアルでは、AIが翻訳テキストを元の画像に完璧に適合させるために用いる先進的な技術を紹介します。これらの手順に従うことで、画像の視覚的整合性を保ちながら、自然で文脈に適した翻訳を実現できます。
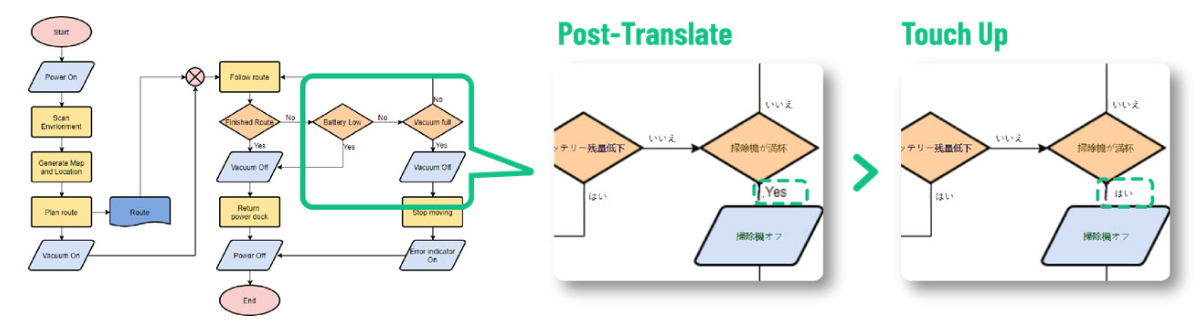
翻訳テキストの完璧な適合を実現する手順
1. 精確なテキスト検出と位置特定
目的:画像内のテキストの正確な位置と境界を明確に特定する。
ツールと技術:
- PP-OCRなど最先端のOCR(光学文字認識)モデルを活用して、テキスト領域を検出および位置特定する。
- 編集および翻訳のための正確な領域を定義し、AIが元のテキストの位置を正確に把握できるようにする。
参考: AI画像翻訳のコツとテクニック
2. 言語モデルを用いた文脈認識翻訳
目的:テキストおよび視覚的要素の全体的な文脈を考慮しながら、抽出されたテキストを翻訳する。
ツールと技術:
- 文脈翻訳に大型言語モデル(LLM)および視覚言語モデル(VLM)を活用する。
- 特に画像内の断片的または複雑なテキストに対して、言語的な正確性と適切さを維持する。
参考: 翻訳におけるAIの役割
3. テキスト長に基づいた適応型テキストボックスのサイズ調整
目的:検出された元のテキストと翻訳後の目標テキストの長さに応じて、予想されるテキストボックスのサイズを調整する。
ツールと技術:
- 異なる言語(例:ドイツ語 vs. 英語)で一般的なテキストの拡張や収縮に対応できるように、バウンディングボックスを動的に調整する。
- 翻訳テキストが溢れ出たり、余分な空白が生じたりしないようにし、画像レイアウト内の比例性とバランスを保つ。
参考: AI生成画像の拡張と編集方法
4. ディフュージョンモデルを用いたシームレスなテキスト統合
目的:翻訳されたテキストを元の画像に滑らかに統合し、フォントスタイル、色、周囲の視覚的文脈を保持する。
ツールと技術:
- 画像内の自然なテキスト編集に拡散モデルを使用する。
- 画像の調和を損なう鋭いエッジ、色の不一致、または視覚的アーティファクトを避ける。
参考: AI画像翻訳
5. フォントの一致とスタイルの保持
目的:元のテキストのフォントタイプ、サイズ、色、スタイルを一致させ、翻訳されたテキストが画像デザインと視覚的に統合されるようにする。
ツールと技術:
- 多言語のタイポグラフィのニュアンスを処理し、読み方向が異なる言語(例:右から左への script)に合わせてレイアウトを調整する。
- 元の画像の視覚的一貫性と美的整合性を保持する。
参考: 正確なAI翻訳
6. 後処理と手動による微調整
目的:最終出力を向上させ、プロフェッショナルな品質の結果を確保する。
ツールと技術:
- 色補正、ノイズ低減、解像度の拡大などの後処理技術を適用する。
- テキスト配置の微調整やアーティファクトの修復に手動編集ツールを使用する。
参考: AIローカリゼーション
従来の手法との比較
従来の画像翻訳ツールは、翻訳されたテキストを固定された長方形領域に貼り付けることが多く、色の不一致や背景の乱れ、不自然なテキストの外観を引き起こすが、ここに記載されたAI駆動のアプローチは、元の画像と視覚的に整合性があり、スタイル的にも一貫した翻訳を生成する。人間およびAIによる評価により、この方法がMicrosoftやApple Image Translationなどの商用製品よりも、真正性とスタイルの保持において顕著に優れていることが示された。
参考: AI画像翻訳
結論
要するに、AIはテキスト領域を正確に検出することで、文脈に基づいてコンテンツを翻訳し、テキストの長さに応じてテキストボックスを動的にサイズ調整し、拡散モデルを用いて滑らかでスタイル一貫性のあるテキスト統合を実現することで、翻訳されたテキストが元の画像に完璧に適合することを保証する。この高度なプロセスは、複数の言語にわたり、元の画像の意味と視覚的調和を両方保持する。
参考: AI画像翻訳
追加リソース
- 手動で未翻訳テキストを認識する
- 翻訳におけるAIの役割
- AI生成画像の拡張と編集方法
- AI画像翻訳
- 正確なAI翻訳
- AIローカリゼーション
- 最高のAI翻訳品質保証ツール
- 小説翻訳におけるAI
- 多言語画像翻訳
このチュートリアルに従うことで、元の視覚的および文脈的整合性を保った高品質な画像翻訳を実現できます。