










信頼性の高いソフトウェアシステムを構築するには、機能的なコードを書くこと以上に、データおよびプロセスのライフサイクルを管理するための構造的なアプローチが必要です。ステートマシンは、システムが一つの状態から別の状態へどのように移行するかを明確に示す基本的なツールです。ステート図を永続的ストレージおよび外部サービスと統合する際、複雑性は顕著に増加します。このガイドでは、ステートロジックをデータベース操作およびAPI連携に効果的に接続するために必要な技術的パターンについて探求します。
ステートマシンは単なる理論的構造ではなく、データの流れを規定する実用的な実装です。注文処理、ユーザーのオンボーディング、ワークフロー自動化のいずれを管理するにせよ、ステートの整合性は極めて重要です。このロジックをデータベースと統合することで、ステートの変更が永続的になることを保証します。APIと接続することで、システムは外部のトリガーに反応できるようになります。この文書では、この統合におけるアーキテクチャ上の考慮事項、実装パターン、リスク軽減戦略について詳述します。
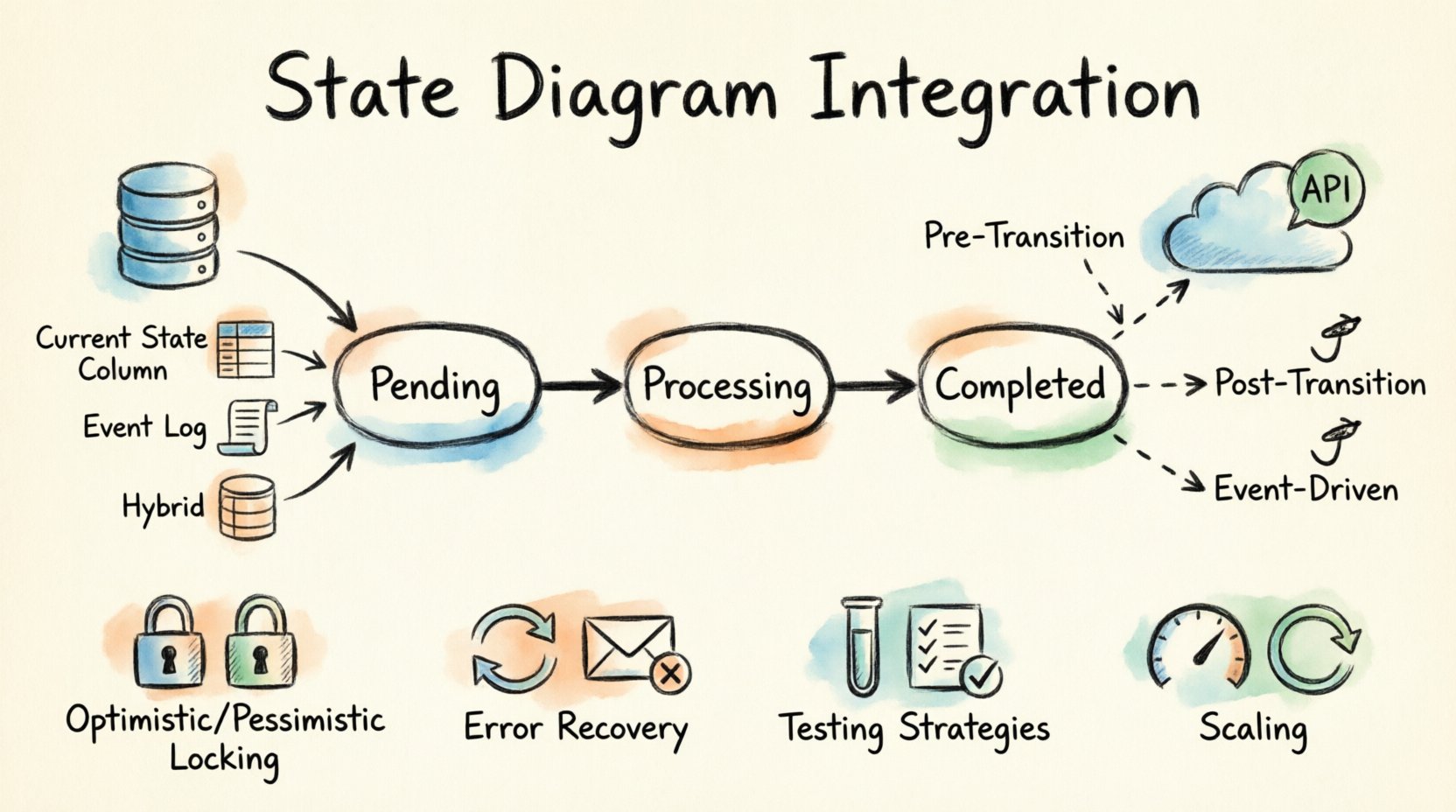
コアアーキテクチャの理解 🧩
永続化やネットワークロジックに突入する前に、関与するコンポーネントを明確に定義することが不可欠です。ステートマシンは、3つの主要な要素から構成されています:ステート、遷移、イベントです。これらの要素が外部システムとどのように相互作用するかを理解することが、統合の基盤となります。
- ステート:特定の瞬間におけるエンティティの状態を表します。例として保留中, 処理中、または完了.
- 遷移:イベントによって引き起こされる、一つのステートから別のステートへの移動です。ここにロジックが適用されます。
- イベント:遷移を引き起こすシグナルです。これらは内部システムのアクションや外部API呼び出しから発生する可能性があります。
統合を行う際、ステートはデータベースから可視である必要があり、遷移はAPI呼び出しを発行できる必要があります。これにより、データベースが真実を保持し、APIが副作用を処理するという依存関係の連鎖が生じます。
データベースの永続化戦略 🗄️
永続化とは、システムの再起動や障害後も状態が保持されるように、現在の状態を保存するプロセスです。状態の保存方法は、パフォーマンス、整合性、復旧能力に影響を与えます。ステート図のノードをデータベースの行にマッピングするためのいくつかのパターンがあります。
現在のステートの保存
最も一般的なアプローチは、主記録テーブル内の専用カラムに現在のステート識別子を保存することです。これにより、ログのスキャンをせずに迅速に取得が可能になります。
- 実装方法: 主エンティティテーブルに
statusまたはstate_codeカラムを追加する。 - 利点:現在のステータスを確認する際の高速な読み取りパフォーマンス。
- リスク: 状態論理が複雑な場合、1つのカラムではすべての必要なコンテキストを把握できない可能性がある。
イベントログストレージ
一部のアーキテクチャでは、現在の状態は直接保存されない。代わりに、イベントのシーケンスがログに保存される。現在の状態は、イベントを再再生することで導出される。
- 実装: 状態遷移が発生するたびに、イベントをテーブルに追加する。
- 利点: 完全な監査トレールと、履歴を再構築できる能力。
- リスク: 現在の状態を計算するには、ログ全体を処理する必要があり、遅くなる可能性がある。
ストレージモデルの比較
| モデル | 読み取り性能 | 書き込みの複雑さ | 監査機能 |
|---|---|---|---|
| 現在の状態カラム | 高 | 低 | 低 |
| イベントログ | 中程度(再再生が必要) | 中程度 | 高 |
| ハイブリッド | 高 | 中程度 | 中程度 |
ハイブリッドモデルはしばしば好まれる。現在の状態を迅速にアクセスできるように保存しつつ、監査のためにイベントのログを維持する。これにより、システムは現在の状態を把握しているだけでなく、それがどのように達成されたのかも把握できる。
データベースの制約と整合性
データの整合性を確保することは重要である。データベースは、無効な状態遷移を防ぐルールを強制すべきである。アプリケーションロジックが主な守備門であるが、データベースの制約は安全網を提供する。
- 制約の確認:状態カラムの有効な値を定義する。
- 外部キー:状態ログをメインエンティティにリンクして参照整合性を確保する。
- トランザクション:状態の更新と関連データの変更を1つのトランザクションで囲み、原子性を確保する。
APIおよび外部ロジックの統合 🔗
状態遷移はしばしばアクションを要する。システムが「保留中」から「処理中」へ移行する際、通知を送信する、支払いを請求する、または在庫システムを更新する必要がある場合がある。これらのアクションはAPIを介して処理される。
外部呼び出しのトリガー
API呼び出しは遷移ロジックに基づいてトリガーされるべきである。これにより、状態変更が有効な場合にのみ副作用が発生することを保証する。
- 遷移前フック:状態変更を許可する前に外部条件を検証する。
- 遷移後フック:状態が正常にコミットされた後にロジックを実行する。
- イベント駆動型フック:状態変更イベントを監視し、非同期に反応する。
APIの障害処理
ネットワーク呼び出しは信頼性が低い。状態遷移中にAPI呼び出しが失敗した場合、システムはどのように進めるかを決定しなければならない。状態を曖昧な位置に放置すると、データの破損が発生する可能性がある。
- 補償トランザクション:アクションが失敗した場合、ロールバックをトリガーするか、失敗を示す特定の状態(例:失敗または再試行).
- 再試行ロジック:一時的なエラーに対して指数バックオフを実装する。
- 冪等性: APIコールの再試行が重複レコードや重複料金を生成しないことを保証する。
リクエストパターン
| パターン | 使用ケース | 複雑さ |
|---|---|---|
| 同期的 | 即時フィードバックが必要 | 低 |
| 非同期的 | 長時間実行タスク | 中 |
| 発射して忘却 | 通知 | 低 |
同期呼び出しは、APIの応答を待つまで状態遷移をブロックする。これはシンプルだが、タイムアウトを引き起こす可能性がある。非同期呼び出しは、状態を即座に更新でき、後でワーカーが外部リクエストを処理する。これにより、状態ロジックと外部依存の遅延が分離される。
並行処理とレースコンディション 🔄
複数のプロセスが同じエンティティの状態を同時に変更しようとする場合、レースコンディションが発生する可能性がある。これは、リクエストが異なるAPIエンドポイントを経由して到着する分散システムで一般的な現象である。
楽観的ロック
楽観的ロックは、競合が稀であると仮定する。バージョン番号またはタイムスタンプを使用して変更を検出する。
- ロジック: 現在のバージョンを読み取る。新しい状態とインクリメントされたバージョンでレコードを更新する。
- 競合: 更新が0行に影響した場合、他のプロセスがレコードを変更した。トランザクションはロールバックされる。
- 利点: 競合が少ないシステムにおける高いスループット。
悲観的ロック
悲観的ロックは、競合が起こりやすいと仮定する。読み取り前にレコードをロックする。
- ロジック: 行に対して排他的ロックを取得する。更新を実行する。ロックを解放する。
- 競合: 他のプロセスはロックが解放されるまで待機する。
- 利点: 操作の順序を保証する。
- リスク: 注意深く管理しないとデッドロックを引き起こす可能性がある。
キュー基準の状態管理
同時実行の問題を完全に回避するため、すべての状態変更要求を単一のキューを通じてルーティングする。
- 実装: すべてのAPIリクエストはイベントをメッセージキューにプッシュする。
- 処理: 単一のワーカーが特定のエンティティIDに対してイベントを順次処理する。
- 利点: 機械的にレースコンディションを排除する。
エラー処理と回復 🛡️
エラーは避けられない。統合層は状態マシンを破損した状態に放置せずに処理しなければならない。
トランザクションの境界
トランザクションの開始と終了を定義する。よくあるミスは、APIコールが成功する前にデータベースの状態をコミットすることである。これにより、データベースは「完了」と言うが、外部サービスはリクエストを受信していない状態になる。完了 しかし外部サービスはリクエストを受信していない。
- 2段階コミット: データベースと外部サービスの両方が結果に合意することを保証する。
- 最終的整合性: 整合性が遅れる可能性を受け入れるが、それを修正する仕組みを確保する。
デッドレターキュー
APIコールが繰り返し失敗した場合、イベントをデッドレターキューに移動する。これにより、システムが無限にリトライループに陥るのを防ぐ。
- アラート: アイテムがデッドレターキューに入ると、エンジニアに通知する。
- 手動介入: 操作者が失敗したイベントを再試行または破棄できるようにする。
テストと検証 🧪
状態機械のテストは、可能な経路の数が指数関数的に増加するため、複雑です。堅牢なテスト戦略は、論理、統合ポイント、および障害シナリオをカバーする必要があります。
単体テスト:状態ロジック
データベースやAPIから分離して、状態機械をテストする。
- 入力/出力:イベントを入力し、結果として得られる状態を検証する。
- 無効な遷移:無効なイベントが拒否されることを確認する。
- コードカバレッジ:状態遷移ルールの100%カバレッジを目指す。
統合テスト
データベースとAPIモックを使って、フローをテストする。
- データベーススキーマ:状態の更新がスキーマと一致することを検証する。
- APIモック:エラー処理をテストするために、APIの応答(成功、失敗、タイムアウト)をシミュレートする。
- エンドツーエンド:テスト環境で、ワークフロー全体を開始から終了まで実行する。
変異テスト
意図的にコードを破壊し、テストがエラーを検出できるかどうかを確認する。
- ロジックの変更:状態遷移を削除し、テストが失敗することを検証する。
- データの変更:データベースの状態を変更し、システムがそれを拒否することを検証する。
スケーリングとパフォーマンス 🚀
システムが拡大するにつれて、状態機械はパフォーマンスを低下させることなく、より多くの負荷を処理しなければならない。
状態のキャッシュ
すべてのリクエストでデータベースから状態を読み取るのは遅い可能性がある。メモリ内キャッシュは遅延を低減できる。
- 戦略:特定のエンティティIDの現在の状態をキャッシュする。
- 無効化: 状態変更後、キャッシュを即座に無効化することを確保する。
- 一貫性: キャッシュヒット率が高い場合は、一時的な不整合を許容する。
データベースシャーディング
エンティティ数が大きい場合は、エンティティIDに基づいてデータベースを複数のシャードに分割する。
- 利点: 複数のサーバーに負荷を分散する。
- 課題: シャードをまたぐ複雑なクエリは難しくなる。
保守とバージョン管理 📝
ステートマシンは進化する。新しいステートが追加され、古いステートは非推奨になる。この進化を管理することは、長期的な安定性にとって重要である。
ステートロジックのバージョン管理
ステートマシンのロジックのバージョンをステートデータと一緒に保存する。
- 互換性: 新バージョンが古いデータを読み取れるようにすることを確保する。
- 移行: 既存のレコードを新しいスキーマに更新するスクリプトを書く。
非推奨化戦略
ステートを削除する際は、すぐに削除しないこと。
- 非推奨としてマークする: ステートが古くなっていることを示すフラグを追加する。
- 遷移をブロックする: 非推奨ステートへの新しい遷移を防止する。
- クリーンアップ: すべてのデータが移行された後、初めてステート定義を削除する。
ドキュメント
コードと一致する視覚的な図を維持する。これにより、新規開発者がシステムを理解しやすくなる。
- 図作成ツール: コードや設定から図を生成できるツールを使用する。
- 変更履歴: バージョン履歴に、状態図のすべての変更を記録する。
セキュリティ上の考慮事項 🔐
状態遷移はしばしば機密データを含む。セキュリティは統合レイヤーに組み込まれるべきである。
- 承認: 状態変更を要求するユーザーが、その特定の遷移に対して許可を持っていることを確認する。
- データ検証: 状態変更を処理する前に、すべての入力データをクリーニングする。
- ログ記録: セキュリティ監査のために状態変更をログに記録するが、機密データがマスクされていることを確認する。
ベストプラクティスの要約
- 高速なアクセスを可能にするために、現在の状態をデータベースに保存する。
- 監査可能性と再構築のために、すべてのイベントをログに記録する。
- 状態更新とAPI呼び出しの間で原子性を確保するために、トランザクションを使用する。
- APIの障害に対して、指数バックオフを用いたリトライロジックを実装する。
- 並行更新を効率的に処理するために、オプティミスティックロックを使用する。
- 無効な遷移を含む、すべての状態遷移をテストする。
- 状態ロジックをバージョン管理して、時間の経過に伴う進化を管理する。
これらのパターンに従うことで、開発者は耐障害性があり、スケーラブルで保守可能な状態機械を構築できる。状態ロジック、データベース、APIの統合は、信頼性の高いビジネスプロセスの基盤である。このレベルでの適切な設計により、データの破損を防ぎ、システムが負荷下でも予測可能な動作を保証できる。