











複雑なシステムでは、効率性が遅延が発生するまで明らかにならないことがある。プロセスが停止し、データが遅延し、スループットが低下すると、根本的な問題は情報の移動にあることが多く、ストレージや計算そのものにあるわけではない。データフローアナリシスは、情報がシステム内でどのように移動するかを可視化する構造的な手法を提供し、摩擦が生じる場所を特定しやすくする。これらのフローをマッピングすることで、容量が超過している場所や、不要な遅延が蓄積している場所を正確に特定できる。 🧭
このアプローチは、独自のツールに依存せずにシステムアーキテクチャを明確に理解することが必要である。目的は、非効率を明らかにする論理的なフレームワークを構築することである。ソフトウェアパイプライン、製造ライン、または事務ワークフローを管理する場合でも、原則は一貫している。これらの制約を特定することで、スピードと信頼性の向上という明確な成果をもたらす的確な対策が可能になる。 ⚙️
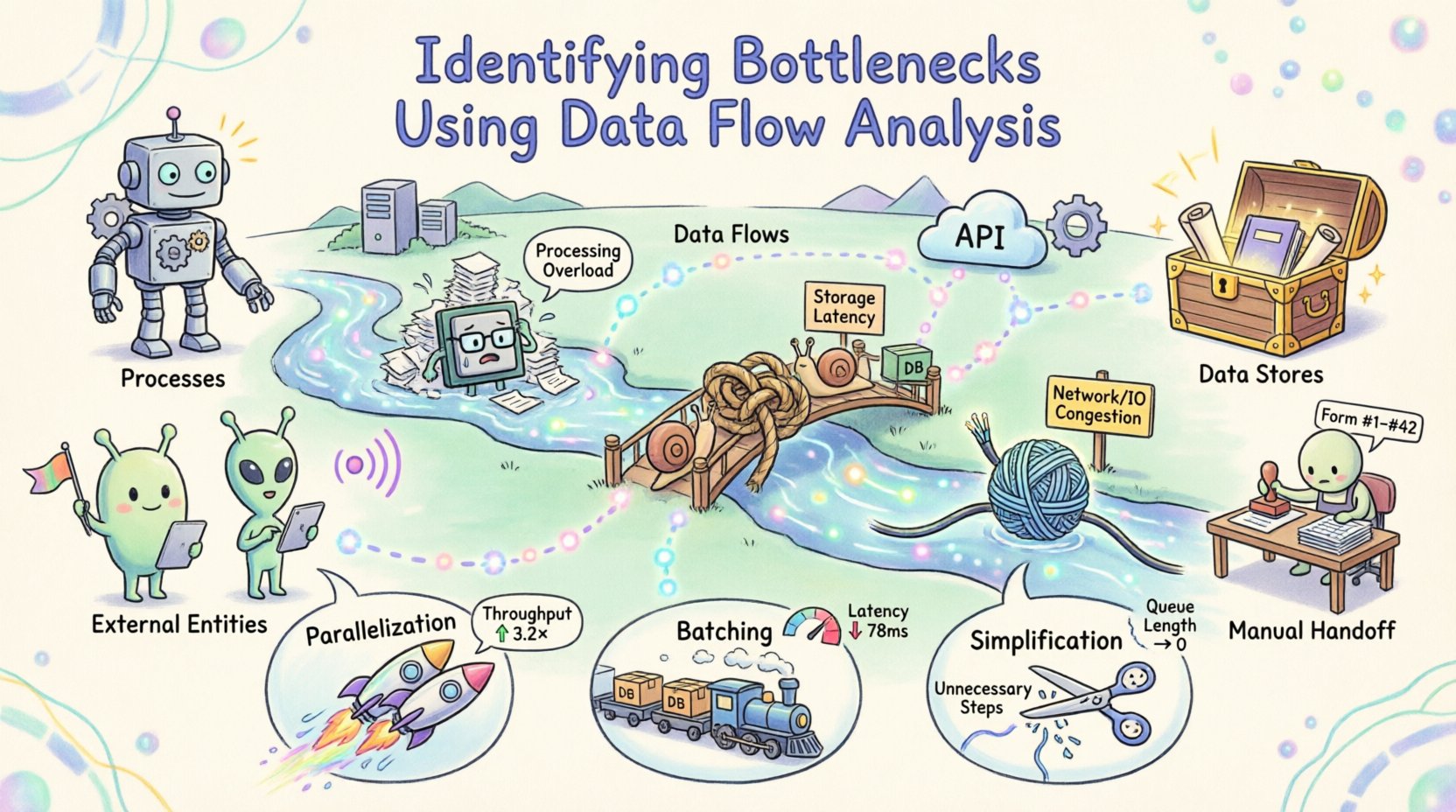
データフローダイアグラムの基礎を理解する 🗺️
ボトルネックを特定する前に、地図を理解する必要がある。データフローダイアグラム(DFD)は、情報システム内を流れているデータの流れを図式化したものである。データがどこから来ているか、どこへ向かっているか、どのように変化するかに焦点を当てる。制御論理を示すフローチャートとは異なり、DFDはデータ要素の移動と変換に重点を置く。
標準的なDFDには4つの主要な構成要素がある:
- プロセス:入力データを出力データに変換する処理。通常、円または角丸長方形で表される。
- データストア:後で使用するためにデータを保持する場所。データベースやファイルなどが該当する。
- 外部エンティティ:システム境界外の情報源または目的地。ユーザー、他のシステムなどが該当する。
- データフロー:データがコンポーネント間を移動する経路。
高レベルの図を作成することで、範囲を明確にする。次に、低レベルの図で特定のプロセスに詳細に焦点を当てる。この階層構造により、分析者はシステムを異なる粒度で検討できる。マクロレベルで遅延が発生した場合、ズームインすることで、具体的に遅延を引き起こしているプロセスやデータ転送を特定できる。 🔍
システムボトルネックの構造 🚦
ボトルネックとは、システム内のどこかでデータの流れが制限され、バックログや遅延を引き起こす点を指す。データフローアナリシスの文脈では、ボトルネックはいくつかの明確な形で現れる。制約の種類を認識することが、解決への第一歩である。
| ボトルネックの種類 | 説明 | 典型的な症状 |
|---|---|---|
| 処理 | 計算や論理処理が、入ってくるデータストリームの対応能力を超えて長時間かかる。 | プロセスの前にキューが蓄積する;CPUやメモリ使用率が急上昇する。 |
| ストレージ | データベースやファイルシステムへのデータ読み書きが遅い。 | データ取得時に遅延が増加する;トランザクション時間に大きなばらつきが生じる。 |
| ネットワーク/I/O | コンポーネント間の転送速度が帯域幅や遅延によって制限される。 | タイムアウトが発生する;大容量のデータ転送が頻繁に一時停止する。 |
| 人間 | 自動化すべき場所で、手動による対応が必要になる。 | タスクが承認待ちになる;疲労や複雑さのためエラーが発生する。 |
これらのカテゴリを理解することで、修正の優先順位をつけるのに役立ちます。ネットワークの制限はインフラ構成の変更を必要とする場合があり、処理の制限はアルゴリズムの最適化を必要とする場合があります。この区別がなければ、システムの制約要因ではない領域に無駄な努力が向けられる可能性があります。 🛠️
識別手法 🔎
ボトルネックの特定は一度限りの出来事ではなく、体系的な調査です。以下のステップは、データフローの分析と制約の特定に向けた堅実なアプローチを示しています。
1. 現状のマッピング
まず、既存のアーキテクチャを文書化することから始めましょう。記憶や仮定に頼ってはいけません。ステークホルダーにインタビューを行い、ドキュメントを確認して、情報の実際の流れを把握しましょう。システムの境界と外部との相互作用を示すレベル0の図を作成します。その後、主要なプロセスを分解するレベル1の図を作成してください。すべてのデータフローが明確な入力と出力を備えていることを確認してください。
2. 測定に使用する指標の定義
視覚的なマップは定性的です。ボトルネックを特定するには、定量的なデータが必要です。各プロセスおよびデータフローに対して、重要なパフォーマンス指標(KPI)を選定してください。関連する指標には以下が含まれます:
- スループット: 単位時間あたりに処理されるデータ量。
- ラテンシー: データが送信元から宛先まで到達するまでの時間。
- 利用率: リソースが稼働している時間の割合。
- キュー長: 処理を待っているアイテムの数。
代表的な期間にわたりこのデータを収集することで、パターンが明らかになります。プロセスは平均的には速く見えても、ピーク負荷時に顕著なスパイクを示すことがあります。このようなスパイクの場所にボトルネックが隠れていることが多いです。 📉
3. データ遷移の分析
プロセス間の接続を検討しましょう。複数のパスに分岐するデータフロー、または複数のソースから合流するデータフローを探してください。合流ポイントはしばしば競合を引き起こします。3つのストリームが1つのプロセッサに流入する場合、そのプロセッサは合計負荷を処理しなければなりません。容量が適切にスケーリングされていないと、バックログが発生します。
同様に、ループがないか確認してください。プロセスを繰り返し通過するデータは、再作業やエラー処理を示している可能性があります。過度なループは価値を生まないままリソースを消費します。これらのループを追跡し、必要かどうか、あるいは設計の不備によるものかを判断しましょう。 🔄
4. リソース使用状況との相関分析
データフローの指標をシステムリソースと照合しましょう。高いデータフロー量は、高いリソース使用率と相関するべきです。特定のデータフローでラテンシーが高いが、他の場所ではリソース使用率が低い場合、問題はそのパスに特有のものかもしれません。逆に、すべてのプロセスが同時に遅くなる場合は、共有データベースのロックやネットワークの混雑など、システム全体の問題である可能性があります。
モニタリングツールを用いて、フローと並行してリソース消費を追跡しましょう。この相関関係は、論理的なボトルネック(設計の問題)と物理的なボトルネック(ハードウェアの限界)を区別するのに役立ちます。 ⚖️
制約の影響を定量化する 📊
潜在的なボトルネックが特定されたら、その影響を定量化する必要があります。このステップにより、リソースが最も重要な問題に割り当てられることが保証されます。すべての遅延が同じではありません。ユーザーインターフェースの遅延は、バックグラウンドでのレポート生成の遅延よりも深刻な影響を及ぼす可能性があります。
遅延のコストを計算しましょう。これは、1トランザクションあたりに失われる時間を推定し、トランザクション数で乗算することで行います。たとえば、プロセスが100ミリ秒余分にかかり、1時間あたり10,000件のトランザクションを処理する場合、失われる時間は有意です。この遅延がユーザー体験に影響するなら、ビジネスコストはさらに高くなります。
リップル効果を考慮しましょう。パイプラインの初期段階での遅延は、下流に伝搬します。最初のステップが遅れると、すべての後続ステップが遅延します。これにより、全体の影響が拡大します。根本原因を特定することで、症状の対処にとどまらず、本質的な問題を解決できます。最初のステップを修正すると、多くの場合、下流の遅延が自動的に解消されます。 🌊
最適化の戦略 🛠️
ボトルネックが特定され、定量化された後は、最適化に注力します。戦略は制約の性質によって異なります。主な3つのアプローチは、並列化、バッチ処理、簡素化です。
並列化
プロセスが計算能力で制限されている場合、作業を複数のリソースに分割することでスループットを向上させられます。これは主に独立したタスクに適用されます。データフローが分割可能であれば、負荷を分散しましょう。同期のオーバーヘッドが利益を相殺しないように注意してください。タスクが互いの即時出力に依存しない場合、並列化は最も効果的です。 🚀
バッチ処理
制約がI/Oやネットワークのラテンシーに関連している場合、個々のアイテムを処理するよりも、データをバッチ単位で処理する方が効率的です。これにより、接続のオープン・クローズのオーバーヘッドが削減されます。ただし、バッチ処理は個々のアイテムに対してラテンシーを引き起こします。スループットの向上と、エンドユーザーが許容できる遅延のバランスを取ることが重要です。 📦
簡素化
多くの場合、最も効果的な最適化は、不要なステップを削除することです。データフローに重複する変換がないか確認しましょう。データが1つのフォーマットから別のフォーマットに変換され、その後再び元に戻される場合、中間ステップを削除できる可能性があります。ロジックを簡素化して処理時間を短縮しましょう。フローに1ステップ追加するたびに、障害や遅延の潜在的な原因が増加します。 ✂️
継続的なモニタリングと反復 🔄
最適化は最終的な目的地ではありません。システムは進化し、トラフィックパターンの変化に伴って新たなボトルネックが生じます。初期の分析が完了し、改善策が実施された後、このサイクルは再び始まります。データフローのレビューを定期的に行う習慣を確立しましょう。
以前に定義したメトリクスに対してアラートを設定してください。スループットが低下したり、レイテンシが急上昇したりした場合は、調査を開始します。DFDのドキュメントを維持してください。システムに変更が加えられるたびに、図を更新しましょう。古くなったマップは誤った仮定を生み出し、無駄な作業につながります。 📝
継続的な改善を促進する文化を育てましょう。チームは日々の業務で見つける非効率な点を報告できるようにするべきです。現場のユーザーは、高レベルなメトリクスでは見逃されがちなボトルネックをよく把握しています。彼らのフィードバックは分析の精緻化に不可欠です。 👥
事例研究:一般的なワークフローの最適化 🏭
注文処理システムがピーク時間帯に遅延を経験した状況を考えてみましょう。初期の分析で、注文検証ステップが長すぎる原因が判明しました。DFDから、検証には異なる外部システムに対する3つの別々のチェックが必要であることが明らかになりました。
フローを分析した結果、これらのチェックが順次行われていたことがわかりました。この設計を並列処理に変更することで、合計の検証時間は60%短縮されました。データフロー図もこの新しい構造を反映するように更新されました。モニタリングにより、バックログがより速く解消され、システムが干渉なしにピーク負荷を処理できることを確認しました。この例は、フローの構造的変更が即効性のある結果をもたらすことを示しています。 ✅
持続可能な効率性のためのベストプラクティス 🌱
健全なシステムを維持するためには、以下のガイドラインに従いましょう:
- 図を最新の状態に保つ: 古いマップは、何もマップがないよりも悪いものです。
- 機能だけでなく、フローに注目する: 機能が動作するだけでなく、データがスムーズに移動することを確認する。
- すべてを測定する: 測定されていないことは、改善できない。
- 定期的に見直す: データアーキテクチャの定期的な監査をスケジュールする。
- 仮定を文書化する: 特定のフローが特定の方法で設計された理由を記録し、将来のトラブルシューティングを支援する。
データフローを重要な資産として扱うことで、組織はシステムが応答性と信頼性を保ち続けることを確実にできます。ボトルネックを特定するプロセスは、欠陥を見つけることではなく、システムを深く理解することにあります。その理解が、レジリエンスとパフォーマンスをもたらします。 🛡️
データフロー整合性についての最終的な考察 🧩
あらゆるシステムの効率性は、情報のスムーズな移動に依存しています。データに抵抗が生じると、全体の運用が遅くなります。データフロー分析は、その抵抗がどこに生じているかを明確に見ることのできるレンズを提供します。マッピングし、測定し、フローを修正することで、チームは摩擦を排除し、パフォーマンスを向上させることができます。
ここで説明した技術は、持続可能な最適化のためのフレームワークを提供します。厳密さと細部への注意が求められますが、その報酬は、圧力下でも一貫して動作するシステムです。データ量が増加するにつれ、フローを管理する能力はますます重要になります。この分野を習得することで、アーキテクチャの持続可能性と信頼性が保証されます。 🏆