











現代の分散システムにおいて、バックエンドサービスの信頼性は、同時に処理されるリクエストや共有リソースをいかに適切に扱うかにかかっていることが多い。この分野で最も根強い、再現が難しい問題の一つがデッドロックである。デッドロックとは、2つ以上のプロセスが互いに相手がリソースを解放するのを待っているため、どちらも進行できなくなる状態を指す。この永久的なブロッキング状態は、システム全体を停止させ、データの不整合、サービスの利用不能、ユーザーの不満を引き起こす可能性がある。こうしたリスクを軽減するためには、単なるコードレビューを超えて、システム設計に視覚的なアプローチを採用する必要がある。通信図は、相互作用をマッピングし、潜在的な競合ポイントを特定し、コードが書かれる前からレジリエンスパターンを強制する構造的な方法を提供する。
このガイドでは、バックエンド環境におけるデッドロックのメカニズムを検討し、通信図が予防的ツールとしてどのように機能するかを示す。制御の流れやリソース取得を可視化することで、チームは循環依存を発見し、それを解消する戦略を実装できる。理論的基盤、実践的な可視化技術、レジリエントなシステムを構築する上で寄与する特定のアーキテクチャパターンについても取り上げる。
デッドロックのメカニズムを理解する 🛑
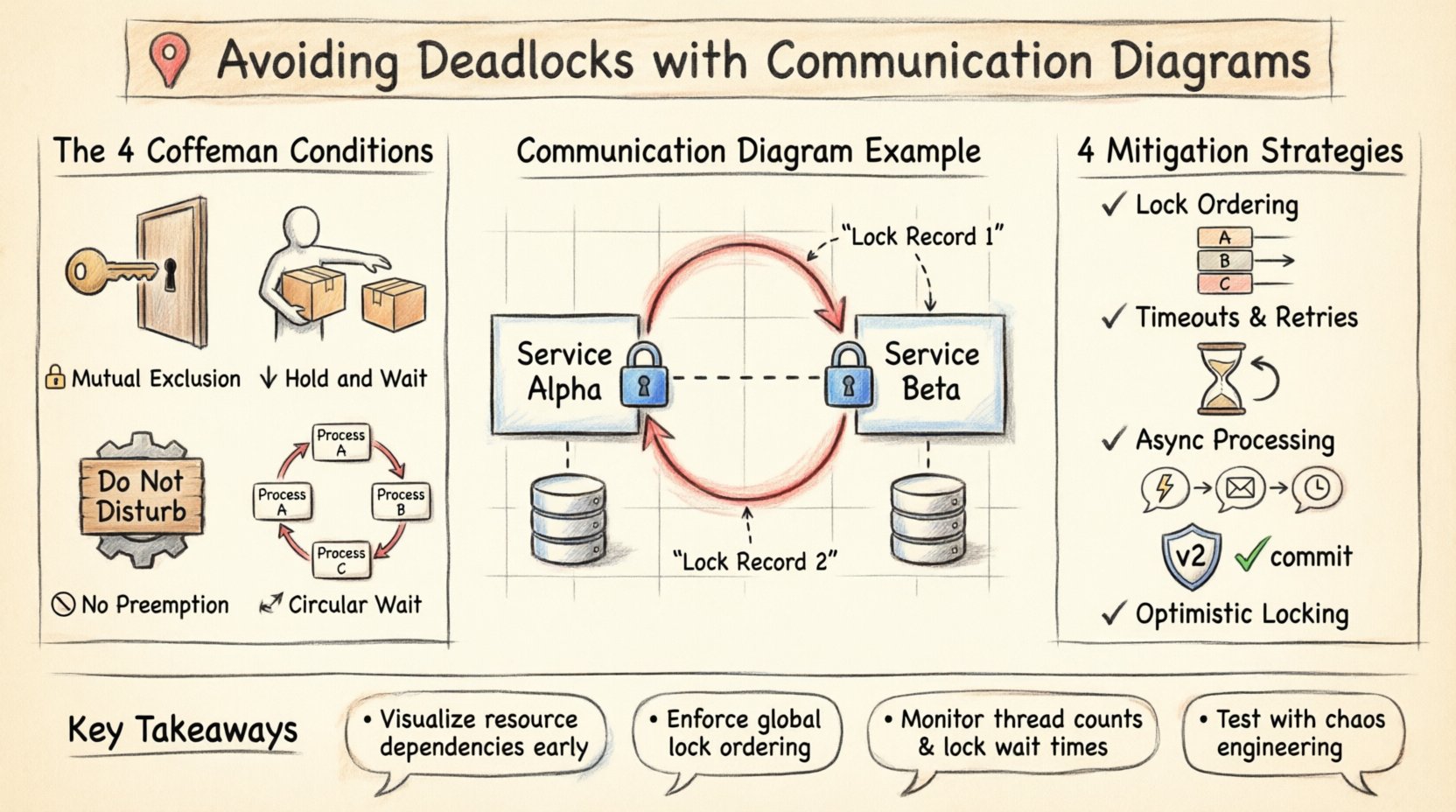
予防策を講じる前に、デッドロックを引き起こす条件を理解することが必要である。コンピュータサイエンスにおいて、デッドロックはランダムな出来事ではない。特定の条件が同時に発生した結果である。これらはしばしばコフマン条件と呼ばれる。デッドロックが存在するためには、以下の4つの条件がすべて満たされている必要がある。
- 相互排他:少なくとも1つのリソースは共有できないモードで保持されなければならない。ある時点で1つのプロセスしかそのリソースを使用できない。
- 保持と待機:プロセスは、他のプロセスが保持している追加のリソースを取得しようとしている間、少なくとも1つのリソースを保持している必要がある。
- 強制解放なし:リソースはプロセスから強制的に取り上げることはできない。プロセスが保持しているリソースは、自発的に解放されなければならない。
- 循環待機:P1がP2を待機し、P2がP3を待機し、以下同様にPnがP1を待機するというプロセスの集合が存在する。
シングルスレッドアプリケーションでは、デッドロックは稀である。しかし、数千もの同時リクエストを処理するバックエンドシステムでは、これらの条件は容易に満たされる。たとえば、Service AがリソースXのロックを保持し、リソースYを待機している一方、Service BがリソースYを保持し、リソースXを待機している場合、循環待機が発生する。強制解放や慎重な順序付けがなければ、システムはフリーズする。
通信図の役割 📊
通信図は、統一モデリング言語(UML)の一種である。シーケンス図がメッセージのタイムラインに注目するのに対し、通信図はオブジェクトの構造的組織とそれらの間のリンクに注目する。バックエンドのレジリエンスという文脈において、この構造的視点は極めて重要である。設計者は、誰が誰と話しているか、そしてどのどのようなリソースが交換されているかを把握できる。メッセージが到着する順序だけではなく、その関係性を可視化できる。
マイクロサービスアーキテクチャや複雑なモノリシックバックエンドを設計する際、通信図は重要な問いに答えるのを助ける。
- どのサービスが、同じデータベーステーブルに対して排他的なアクセスを必要としているか?
- 2つの処理ユニットの間に双方向の依存関係があるか?
- リクエストチェーンが完了する前に、元の発信者に戻るループが存在するか?
- ネストされたリソースロックの最大の深さはどれくらいか?
設計段階の初期にこれらの相互作用をマッピングすることで、コード中心のレビューでは見えにくい潜在的なデッドロック状況を特定できる。図は相互作用の契約として機能し、暗黙の仮定を明確にする。
リソース依存関係のマッピング 🗺️
通信図をデッドロック回避に効果的に活用するためには、図はデータフローだけでなく、リソースを表現しなければならない。標準的な相互作用図はしばしばサービス間の呼び出しを示す。しかし、ロックを分析するためには、リンクにリソース識別子を付加しなければならない。これは、ノードがプロセスやスレッドを表し、リンクが共有リソースや通信チャネルを表す、やや高いレベルの抽象化を必要とする。
デッドロックを認識できる図を作成する手順
- 重要なリソースを特定する:データベースの行、ファイルハンドル、メモリバッファなど、共有される状態をすべてリストアップする。それぞれに固有の識別子を割り当てる。
- 所有権を定義する:どのサービスやスレッドが現在、どのリソースを制御しているかを特定する。その情報を図にマークする。
- 取得経路を追跡する:リソースの要求を示す矢印を描く。矢印にリソース名をラベル付けする。
- 待機状態を強調する:プロセスがリソースを待機してブロックされている状態を、特定の記号で示す。
- サイクルを分析する:プロセスAがプロセスBを待機し、プロセスBがプロセスAを待機する閉じたループが図に存在するかを確認する。
循環待機パターンの特定 🔁
システム設計において最も危険なパターンは循環依存である。通信図では、相互のやり取りが閉じたループとして現れる。サービスAlphaとサービスBetaの2つのサービスを含む状況を考えてみよう。
- サービスAlphaがトランザクションを開始し、レコード1をロックする。
- サービスAlphaが、サービスBetaに対してレコード2のロックを要求する。
- サービスBetaはすでにレコード2のロックを保持しているが、Alphaが保持しているレコード1を更新する必要がある。
視覚的な表現では、このループはすぐに明らかになる。図ではAlphaがBetaを指し、BetaがAlphaを指しており、お互いが相手が保持するリソースを要求している状態が示される。図がなければ、この論理はプロダクション障害や複雑なストレステストの際にしか発見されないかもしれない。
循環性を引き起こす代表的な状況
- トランザクションの伝播:分散トランザクションが複数のサービスが特定の順序でコミットする必要があるが、その順序が強制されていない場合。
- ネストされた呼び出し:関数が別の関数を呼び出し、最終的に元の関数を呼び出すことで、再帰的なロックチェーンが作られる。
- 共有キャッシュ:複数のサービスが、分散ロックメカニズムなしに同時に同じキャッシュエントリを更新しようとする。
- データベースの外部キー:関連するテーブルに対する更新で、両方のテーブルにロックが必要となるが、サービス間で更新順序が異なる場合。
戦略的な緩和技術 🛠️
通信図が潜在的なデッドロックを明らかにした後は、特定のアーキテクチャの変更が必要となる。すべてのシステムに当てはまる単一の解決策は存在しないが、コフマン条件を破るためのいくつかの検証済み戦略が存在する。
1. ロック順序
循環待機を防ぐために最も効果的な方法である。システムはリソースのグローバルな順序を強制しなければならない。すべてのプロセスが同じ順序(例:リソースAをリソースBより先に)でリソースを要求すれば、サイクルは形成されない。通信図では、リソースYを要求するリンクが存在する前に、すべてのリソースXを要求するリンクが確立されていることを保証することを意味する。
2. タイムアウトと再試行
順序付けがあっても、競合は発生する可能性があります。リソース取得にタイムアウトを設定することで、プロセスが無限に待機することを防ぎます。指定された期間内にロックを取得できなかった場合、プロセスは現在保持しているリソースを解放して再試行します。これにより、システムが永久に停止するのを防ぎますが、遅延が発生する可能性があります。
3. 非同期処理
同期リクエストから非同期イベント駆動型アーキテクチャに切り替えることで、競合を軽減できます。ロックの解放を待つ代わりに、サービスはイベントを発行して処理を継続します。リソースが利用可能になると、コンシューマーが更新を処理します。これにより、リソース使用のタイミングが分離されます。
4. 極めて楽観的なロック
データの読み取りや変更の前にロックを取得するのではなく、コミット時に競合を確認します。読み取り以降に他のプロセスがデータを変更していた場合、トランザクションは失敗し、再試行する必要があります。これによりロックの保持時間が短縮され、デッドロックの発生可能性が最小限に抑えられます。
予防戦略の比較
| 戦略 | 防止する状態 | 複雑さ | パフォーマンスへの影響 |
|---|---|---|---|
| ロック順序付け | 循環待機 | 高 | 低 |
| タイムアウト | 保持と待機(間接的に) | 低 | 中(再試行) |
| 楽観的ロック | 相互排除(長期的) | 中 | 可変 |
| 非同期フロー | 保持と待機 | 高 | 低 |
図に基づく分析のための実装手順
このアプローチを開発ワークフローに統合するには、以下の手順に従ってください:
- 設計レビューを実施する: コードを書く前に、新機能用の通信図を作成する。データアクセス経路に注目する。
- リソース使用状況を注記する: 図上に、すべてのデータベース書き込み、キャッシュ更新、ファイル操作をマークする。
- サイクル検出アルゴリズムを実行する: 自動化ツールを使用する場合、図から導出された依存関係グラフ内のサイクルを検出するために、グラフアルゴリズムを適用する。
- 独立性を確保するための再設計: サイクルが検出された場合、依存関係を断つためにコードを再設計する。メディエータサービスの導入やデータモデルの変更が含まれる可能性がある。
- 負荷テストで検証する: 高度な並行処理をシミュレートし、ストレス状態でもデッドロックパターンが発生しないことを確認する。
モニタリングと可視性 🧪
慎重な設計を行っても、実行時環境は変化する可能性がある。モニタリングツールはデッドロックの兆候を検出できるように設定すべきである。主なメトリクスには以下が含まれる:
- スレッド数: ブロッキングされたスレッド数が急激に増加した場合は、リソース競合を示している可能性がある。
- ロック待機時間: ロック取得にかかる平均時間が著しく増加した場合、競合が増加している。
- トランザクションのロールバック: タイムアウトや衝突によるロールバック率が高い場合、ロック戦略がやりすぎている可能性がある。
- デッドロック検出ログ: 一部のデータベースエンジンやオペレーティングシステムはデッドロックイベントをログに記録する。これらのログは中央ログシステムに統合されるべきである。
事例研究:サービス間のやり取りフロー
注文と在庫を処理する一般的なECバックエンドを検討する。Service Aは注文を担当し、Service Bは在庫を担当する。
シナリオ: Service Aは注文を作成し、注文IDをロックする。その後、在庫を予約するためにService Bを呼び出す。Service Bは在庫IDをロックする。注文ステータスを更新するために、Service BはService Aにコールバックを送信する必要があるが、これには注文IDを再びロックする必要がある。
デッドロックの状態: Service Aが注文IDを保持し、Service Bが在庫IDを解放するのを待っているが、Service BがService Aが注文IDを解放(コールバック経由)しない限り完了できない場合、デッドロックが発生する。これはネストされたロックの状況である。
修正策: 通信図を使用することで、このループが可視化される。修正は依存関係を断つことにある。Service Bは在庫を非同期に更新するか、Service Aが保持する注文IDを再ロックしなくてもよい別のトランザクションIDを使用すべきである。その場合、図上ではAからBへの一方向のフローが示され、元のロックを必要とする戻りパスは存在しなくなる。
分散ロックの考慮事項
分散環境では、ロックはアプリケーション自身ではなく外部サービスによって管理されることが多い。これによりネットワーク遅延や部分的な障害のリスクが生じる。通信図はネットワークリンクを障害の潜在的ポイントとして考慮すべきである。Service Aとロックマネージャー間のリンクが障害した場合、Service Aはロックを保持していると誤って認識するが、他のサービスが実際にロックを保持している可能性がある。
これを解決するため、図には「ロックマネージャー」ノードを含めるべきである。このノードとのやり取りは、再実行可能(idempotent)かつ時間制限付きでなければならない。設計上、サービスがクラッシュした場合、リース期間が経過するとロックが自動的に解放されるようにする。これにより、「保持して待機」状態が無期限に続くことを防ぐ。
レジリエンスのためのテスト
設計図は理論的なものである。レジリエンスの検証には現実世界でのテストが必要である。これには以下が含まれる:
- チャオスエンジニアリング: 図に示されたネットワークリンクに意図的に遅延や障害を導入し、システムが回復するか、デッドロックするかを確認する。
- ストレステスト: 図で特定されたパターンに一致する同時リクエストを実行し、ロックの順序が負荷下でも正しく動作することを検証する。
- 静的解析: 図の論理と一致する可能性のあるロック順序違反をコードベースで検出するためにツールを使用する。
結論
デッドロックを避けることは単なるコーディング作業ではない。それはシステム設計の課題である。通信図を活用することで、システムのフリーズを引き起こす複雑なリソース依存関係のネットワークを可視化できる。このアプローチは、反応的なデバッグから予防的な対策への焦点の移行を可能にする。デッドロックの4つの条件を理解し、リソース取得経路をマッピングし、厳格な順序付けまたは非同期パターンを強制することは、レジリエントなバックエンドインフラを構築する上で不可欠なステップである。あらゆるシステムが並行処理の問題から完全に免疫であるわけではないが、構造的な視覚的アプローチを取ることで、共有リソースの管理におけるリスクと複雑さを著しく低減できる。これらの原則を一貫して適用することで、高負荷や障害状態下でもサービスの応答性が維持され、データの一貫性が保たれる。