











Les systèmes distribués dépendent fortement du déplacement d’informations entre des composants isolés. Lors de la construction de microservices, l’architecture ne consiste pas seulement à séparer le code ; elle consiste à orchestrer la manière dont les données circulent au sein d’un réseau. Comprendre la logique du flux de données est essentiel pour maintenir l’intégrité, les performances et la fiabilité du système. Sans une carte claire indiquant d’où proviennent les données, où elles sont transformées et où elles se stabilisent, les systèmes deviennent opaques et difficiles à dépanner.
Ce guide explore la méthodologie de cartographie de ces flux. Nous examinerons les composants structurels, la logique du déplacement des données, ainsi que les modèles régissant la communication entre les services. L’objectif est de créer une architecture transparente où chaque transaction est prise en compte.
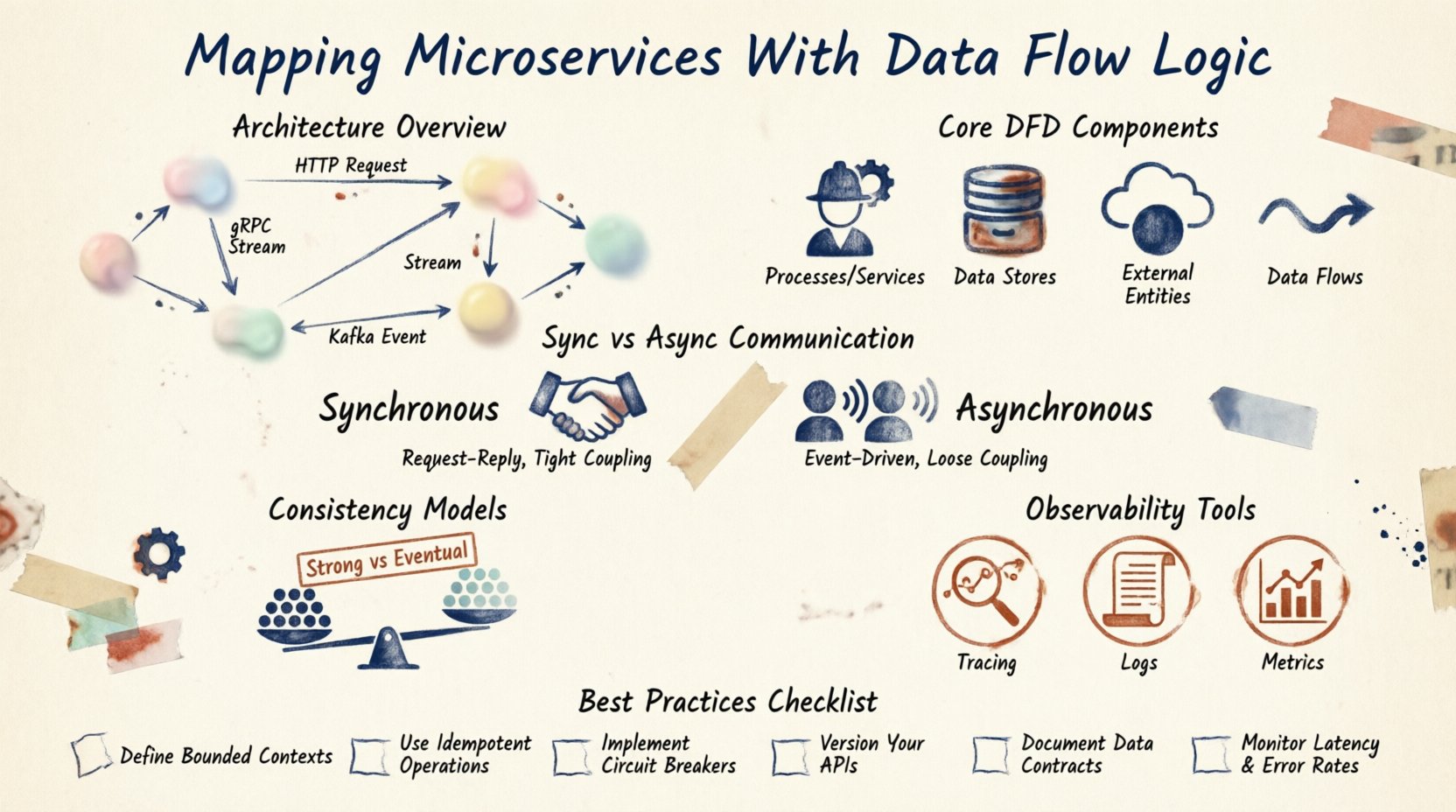
Comprendre l’architecture 🏗️
L’architecture des microservices décompose une application monolithique en unités plus petites et indépendantes. Chaque unité gère une fonctionnalité métier spécifique. Toutefois, cette indépendance introduit une complexité en matière de gestion d’état et de communication. Les données n’existent pas dans le vide ; elles circulent.
Lorsque vous cartographiez ces services, vous dessinez essentiellement un plan directeur du système nerveux. Vous devez identifier les producteurs de données et les consommateurs. Vous devez comprendre les protocoles utilisés pour la transmission. Les services communiquent-ils directement via HTTP ? Utilisent-ils une file de messages ? Accèdent-ils à une base de données partagée ?
Une clarté dans ce domaine prévient le couplage. Si le Service A dépend du Service B pour fonctionner, cette dépendance doit être explicite dans vos cartes. Les dépendances cachées entraînent des défaillances en chaîne. En visualisant le flux, vous pouvez identifier les goulets d’étranglement avant qu’ils n’affectent les performances en production.
Principaux moteurs de la cartographie
- Observabilité : Vous ne pouvez pas déboguer ce que vous ne voyez pas. Une carte claire aide à suivre les requêtes à travers l’environnement distribué.
- Sécurité : Comprendre le flux de données vous permet d’appliquer le chiffrement et les contrôles d’accès aux bonnes frontières.
- Performance : Identifier les chemins à forte latence aide à optimiser les appels réseau et les requêtes de base de données.
- Conformité : Les réglementations exigent souvent de savoir où se trouvent les données sensibles et comment elles circulent.
Composants fondamentaux des diagrammes de flux de données 📊
Un diagramme de flux de données (DFD) fournit une méthode normalisée pour représenter ces interactions. Dans le contexte des microservices, les composants sont légèrement différents de ceux des DFD traditionnels en génie logiciel.
1. Processus (services)
Ce sont les éléments actifs. Chaque microservice représente un processus qui transforme les données d’entrée en données de sortie. Par exemple, un service de commande reçoit les détails de la commande et les transforme en réservation de stock.
2. Magasins de données
Les données ne restent pas toujours en mémoire. Elles persistent souvent dans des bases de données, des caches ou des stockages d’objets. Dans un environnement de microservices, les services ont généralement des magasins de données privés. Cela garantit un couplage lâche. Si le schéma de base de données change, seul le service propriétaire doit s’adapter.
3. Entités externes
Ce sont des acteurs en dehors du système. Il peut s’agir d’une passerelle de paiement tierce, d’une application mobile ou d’un utilisateur. Ils initient des requêtes ou reçoivent des notifications. Cartographier ces frontières est crucial pour la conception de passerelles API.
4. Flux de données
Ce sont les flèches reliant les composants. Elles représentent le déplacement des informations. Chaque flux doit être étiqueté pour décrire les données transférées. S’agit-il d’un payload JSON ? D’un fichier binaire ? D’une notification d’événement ?
Processus de cartographie étape par étape 🗺️
Créer une carte est un exercice systématique. Il nécessite de décomposer le système couche par couche. Voici une approche logique pour construire ces diagrammes.
- Identifier la frontière : Définissez ce qui est à l’intérieur du système et ce qui est à l’extérieur. Cela fixe le périmètre de votre diagramme.
- Lister les services : Énumérez chaque microservice impliqué dans le processus métier spécifique que vous analysez.
- Définir les points d’entrée des données : Où les données entrent-elles dans le système ? S’agit-il d’un point de terminaison API ? D’un travail planifié ? D’un consommateur de file d’attente de messages ?
- Suivez le parcours : Suivez un seul morceau de données depuis son entrée jusqu’à sa sortie. Notez chaque service qu’il touche.
- Identifiez le stockage : Indiquez où les données sont lues ou écrites à chaque étape.
- Validez la logique : Revoyez la carte avec l’équipe de développement pour vous assurer qu’elle correspond à l’implémentation réelle.
Modèles de communication 📡
La manière dont les services communiquent entre eux détermine la logique de flux. Il existe deux modes principaux : synchrone et asynchrone.
Communication synchrone
Le service A appelle le service B et attend une réponse. Cela est souvent mis en œuvre via REST ou gRPC. Cela fournit un retour immédiat, mais crée un couplage étroit. Si le service B est lent, le service A bloque.
Communication asynchrone
Le service A envoie un message et continue son travail. Le service B le récupère lorsqu’il est prêt. Cela utilise des brokers de messages ou des flux d’événements. Cela améliore la résilience, mais rend le suivi de l’état plus difficile.
| Aspect | Synchrone | Asynchrone |
|---|---|---|
| Latence | Élevée (bloquante) | Basse (non bloquante) |
| Couplage | Étroit | Lâche |
| Complexité | Facile à suivre | Exige le sourcing d’événements |
| Gestion des erreurs | Réessayer immédiatement | Files de lettres mortes |
Modèles de cohérence 🤝
Dans un système distribué, la cohérence des données est une préoccupation majeure. Vous ne pouvez pas compter sur une seule transaction à travers plusieurs bases de données. Vous devez choisir un modèle de cohérence.
Consistance forte
Chaque lecture reçoit l’écriture la plus récente. Il est difficile d’atteindre cela entre plusieurs microservices sans blocage. Cela nécessite souvent des mécanismes de verrouillage distribué.
Consistance éventuelle
Les données deviendront cohérentes après un certain délai. Les mises à jour se propagent de manière asynchrone. C’est la norme pour la plupart des microservices. Cela permet une haute disponibilité, mais nécessite que l’application gère les incohérences temporaires des données.
Observabilité et traçage 🔍
Une fois la carte dessinée, vous avez besoin d’outils pour la surveiller. Le traçage distribué vous permet de suivre un identifiant de requête à travers chaque service. Cela est essentiel pour le débogage.
Les journaux doivent être corrélés. Si une requête échoue, les journaux provenant de la passerelle, du service de commande et du service de paiement doivent être liés. Cette liaison est le jumeau numérique de votre diagramme de flux de données.
Les métriques font également partie du flux. Vous devez suivre le volume des messages, la latence des appels et les taux d’erreurs. Ces métriques valident l’état de santé des chemins de données que vous avez conçus.
Meilleures pratiques pour la maintenance 🛠️
Un diagramme n’est utile que s’il reste précis. Les systèmes évoluent, et la carte doit évoluer avec eux.
- Génération automatisée : Lorsque c’est possible, générez les diagrammes à partir du code ou de l’infrastructure définie en code. Cela réduit les erreurs manuelles.
- Contrôle de version : Stockez vos diagrammes dans le même dépôt que votre code. Revoyez-les lors des demandes de fusion.
- Audits réguliers : Programmez des revues trimestrielles pour vous assurer que la carte correspond au système en cours d’exécution.
- Documentation des protocoles : Définissez clairement les formats de données. Utilisez des schémas pour imposer une structure entre les services.
Défis des flux distribués ⚠️
Cartographier ces systèmes n’est pas sans difficultés. Les réseaux tombent en panne. Les services redémarrent. Les données sont perdues.
Latence du réseau : La distance physique entre les services peut impacter les performances. Vous devez tenir compte de cela dans votre logique de temporisation.
Fragmentation des données : Les données sont réparties sur de nombreux magasins. Reconstituer une vue complète d’une entité nécessite de joindre des données provenant de sources différentes. Cela ajoute de la complexité aux requêtes.
Orchestration versus chorégraphie : Vous devez décider qui contrôle le flux. L’orchestration utilise un coordinateur central. La chorégraphie repose sur des événements. Les deux présentent des compromis en matière de visibilité et de contrôle.
Concevoir pour l’avenir 🔮
La technologie évolue. Les protocoles évoluent. Votre carte doit être suffisamment abstraite pour résister à ces changements.
Concentrez-vous sur la logique métier plutôt que sur les détails d’implémentation. Décrivez ce que signifient les données, et non seulement comment elles sont encodées. Cette abstraction vous permet d’échanger les technologies sous-jacentes sans réécrire l’ensemble de l’architecture.
Pensez à la scalabilité. Le flux peut-il supporter dix fois la charge ? La carte indique-t-elle où des goulets d’étranglement pourraient survenir ? Concevez pour la croissance dès le départ.
Réflexions finales sur la logique des données
Cartographier les microservices avec la logique de flux de données est une compétence fondamentale pour les architectes. Cela déplace la conversation du code abstrait vers un mouvement concret. En visualisant le flux, les équipes peuvent prendre de meilleures décisions concernant la résilience, la sécurité et les performances.
Il faut de la discipline pour maintenir les cartes à jour. Il faut de la collaboration pour s’assurer que tout le monde comprend les chemins. Mais le résultat est un système plus facile à construire, plus facile à déboguer et plus facile à mettre à l’échelle. Les données circulent clairement, et le système reste stable sous pression.
Investissez du temps dans ces diagrammes. Ils servent de documentation pour le sang vital de votre système. Lorsque les lumières s’éteignent sur un serveur de production, ce sont ces cartes qui guident la récupération.