











La conception de systèmes complexes exige une carte claire du déplacement des données entre les composants. Les diagrammes de flux de données (DFD) fournissent cette carte, illustrant le flux d’information plutôt que le flux de contrôle. Cependant, lorsque les processus ne se produisent pas instantanément, le diagramme devient plus complexe. Les opérations asynchrones introduisent des délais, des tâches en arrière-plan et des déclencheurs d’événements que les modèles linéaires standards ont souvent du mal à représenter. Comprendre comment visualiser ces interactions non bloquantes est essentiel pour une architecture système précise.
Lorsqu’une tâche est asynchrone, le processus initiateur continue sans attendre de réponse. Ce découplage permet une meilleure utilisation des ressources et une plus grande réactivité, mais complique la représentation visuelle. Un diagramme plat pourrait suggérer une exécution immédiate là où aucune n’existe. Pour maintenir la clarté, les modélisateurs doivent adopter des conventions spécifiques qui mettent en évidence les écarts temporels sans surcharger le diagramme de détails d’implémentation.
Comprendre l’écart temporel 🕒
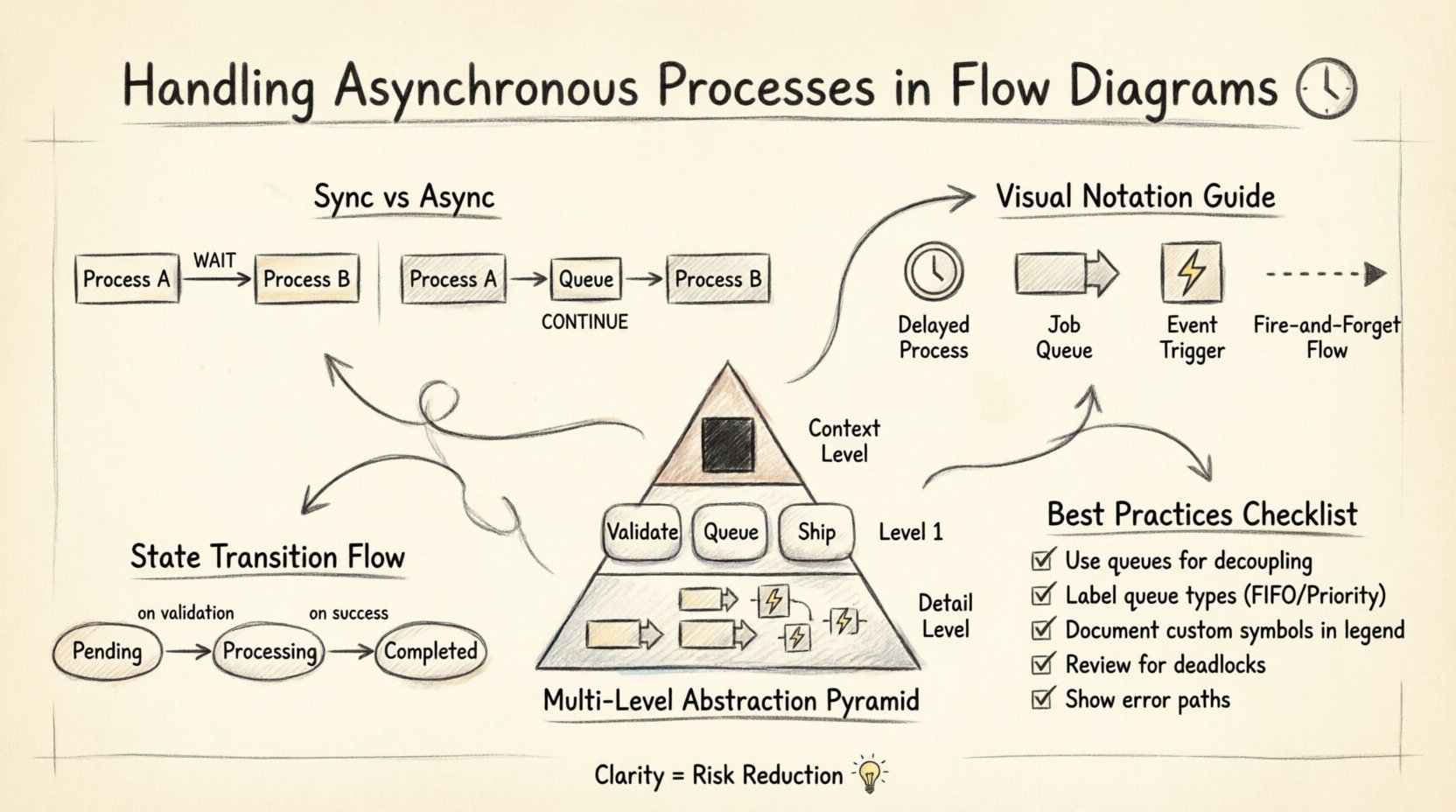
La distinction fondamentale dans ces diagrammes réside dans le moment d’exécution. Les processus synchrones attendent un signal pour continuer. Si le Processus A envoie des données au Processus B, le Processus A s’arrête jusqu’à ce que le Processus B ait terminé et renvoyé un résultat. En revanche, les processus asynchrones envoient les données et poursuivent leur exécution. Le composant récepteur traite le travail de manière indépendante, souvent en stockant les données dans une mémoire tampon jusqu’à ce qu’il soit prêt.
Visualiser cet écart est la première étape. Sans marqueurs explicites, un observateur suppose un transfert immédiat. Cette supposition entraîne des erreurs lors de l’implémentation. Les développeurs pourraient concevoir une logique bloquante là où une logique non bloquante est requise, ou inversement. Pour éviter cela, le diagramme doit montrer explicitement où le flux s’arrête ou se divise. Cela implique d’identifier les points de déconnexion où l’état du système passe de « en attente » à « en traitement ».
Prenons l’exemple d’un utilisateur qui soumet un formulaire. Si le système traite cela immédiatement, l’utilisateur voit un résultat sur le même écran. Si le système traite cela de manière asynchrone, l’utilisateur pourrait recevoir un message de confirmation et voir le résultat final plus tard. Le DFD doit refléter cette séparation. L’entrée va dans un mécanisme de stockage, et la sortie provient d’un déclencheur différent. Cette séparation garantit que le diagramme reflète la réalité, et non seulement l’intention logique.
Visualiser les flux non bloquants 🔄
Les symboles standards des DFD se concentrent sur les processus, les entrepôts de données et les entités externes. Ils ne spécifient pas intrinsèquement le temps. Pour exprimer l’asynchronie, des notations supplémentaires sont souvent nécessaires. Bien qu’une stricte adhésion aux règles traditionnelles suggère de garder les symboles simples, la modélisation pratique exige souvent des extensions pour capturer les nuances temporelles.
- Files d’attente comme entrepôts de données : Utilisez des entrepôts de données pour représenter des files d’attente de messages. Au lieu d’une flèche directe du Processus A au Processus B, acheminez les données à travers un élément de stockage. Cela implique que les données sont conservées jusqu’à ce qu’un consommateur les récupère.
- Flèches d’événement : Utilisez des styles de flèches distincts pour les événements qui déclenchent des tâches en arrière-plan. Une ligne pointillée ou une icône spécifique peut indiquer un événement qui se déclenche indépendamment du fil actuel.
- Délais temporels : Ajoutez des étiquettes aux processus pour indiquer les temps de traitement estimés ou les intervalles. Cela aide les parties prenantes à comprendre les attentes en matière de latence.
Il est important de ne pas confondre le flux de contrôle avec le flux de données. Dans un diagramme de flux de contrôle, un signal pourrait attendre. Dans un diagramme de flux de données, l’accent est mis sur le déplacement de l’information. La nature asynchrone est déduite par la présence d’un stockage intermédiaire ou par la séparation des processus d’entrée et de sortie. Une étiquette claire sur l’entrepôt de données, telle que « File d’attente de tâches » ou « Événements en attente », indique immédiatement que le processus n’est pas immédiat.
Notations standards vs. extensions personnalisées 🛠️
Il existe un équilibre entre la standardisation et la clarté. Suivre strictement une méthode spécifique peut limiter la capacité à exprimer des comportements temporels complexes. Toutefois, s’éloigner trop crée de la confusion pour quiconque lit le diagramme et s’attend à des symboles standards. L’objectif est de communiquer efficacement l’architecture aux ingénieurs et aux parties prenantes.
Certaines équipes adoptent des formes personnalisées pour les déclencheurs asynchrones. Un hexagone pourrait représenter un événement externe, tandis qu’un cylindre représente une file persistante. Ces formes ajoutent une importance visuelle à des éléments spécifiques, rendant le diagramme plus facile à lire. La clé réside dans la documentation. Une légende doit expliquer chaque forme personnalisée utilisée. Sans légende, le diagramme devient un puzzle plutôt qu’une aide.
| Élément | Symbole standard | Représentation asynchrone | Objectif |
|---|---|---|---|
| Processus | Cercle ou rectangle arrondi | Cercle avec une icône d’horloge | Indique une exécution retardée |
| Entrepôt de données | Rectangle ouvert | Rectangle ouvert étiqueté « File » | Implique le tamponnage et le découplage |
| Entité externe | Carré | Carré avec une foudre | Indique un déclencheur d’événement |
| Flux de données | Flèche pleine | Flèche pointillée | Suggère une communication de type « déclencher et oublier » |
Utiliser un tableau comme celui-ci dans la documentation aide à aligner l’équipe. Cela garantit qu’un développeur voyant une flèche pointillée comprend qu’elle n’implique pas de valeur de retour synchrone. La cohérence sur l’ensemble des diagrammes d’un projet est essentielle. Si une équipe utilise des traits pointillés pour les opérations asynchrones, elle doit le faire partout.
Gérer la cohérence des données 📊
Lorsque les processus s’exécutent en parallèle ou avec des délais, la cohérence des données devient une préoccupation majeure. Le diagramme doit indiquer où les données sont écrites et où elles sont lues. Dans les systèmes asynchrones, une lecture peut avoir lieu avant que l’écriture ne soit pleinement validée. Cela s’appelle une condition de course.
Pour modéliser cela, définissez clairement l’état des données à chaque étape. Si un processus met à jour un enregistrement puis passe à l’étape suivante, le diagramme doit montrer l’état intermédiaire. Le processus suivant voit-il la mise à jour immédiatement ? Ou attend-il un événement de confirmation ? Les DFD montrent généralement le flux de données, mais ajouter des notes sur les verrous d’état ou la versioning aide à clarifier les contraintes.
Prenons un scénario où une notification est envoyée après la fin d’une transaction. Le processus de transaction écrit dans la base de données. Le processus de notification lit dans un journal ou une file séparée. Le diagramme doit montrer le lien entre ces deux éléments. Si la notification dépend des données de la transaction, il doit y avoir un magasin de données les reliant. Si elle dépend d’un événement, il doit y avoir un chemin de signalisation. L’absence de ce lien suggère une perte de données ou une logique incorrecte.
Abstraction multi-niveaux 📄
La complexité augmente rapidement lorsqu’on traite la logique asynchrone. Un diagramme de contexte de haut niveau pourrait montrer un seul processus pour « Traitement de commande ». Toutefois, en descendant au niveau 1, on découvre que ce processus se divise en « Validation », « File d’attente » et « Expédition ». La nature asynchrone pourrait n’exister que dans l’étape « File d’attente ».
Utiliser différents niveaux d’abstraction aide à gérer cette complexité. Le niveau supérieur montre le système comme une boîte noire. Le niveau intermédiaire montre les composants principaux. Le niveau détaillé montre les files d’attente et les déclencheurs spécifiques. Cette hiérarchie empêche le diagramme principal de devenir illisible. Les parties prenantes consultant le niveau élevé n’ont pas besoin de voir chaque tâche en arrière-plan. Les développeurs consultant le niveau détaillé doivent voir les files d’attente.
Lors du lien entre les niveaux, assurez-vous que les points asynchrones sont conservés. Si un processus est asynchrone au niveau 1, il ne doit pas être simplifié en une étape synchrone au niveau 2 sans explication. Le détail doit révéler le mécanisme de temporisation. Cela pourrait signifier ajouter un sous-processus qui gère explicitement la période d’attente.
Documenter les changements d’état 📝
Les flux asynchrones reposent souvent sur des machines à états. Une tâche peut passer de « En attente » à « En cours de traitement » à « Terminé ». Ces états sont cruciaux pour le débogage. Si une tâche est bloquée, connaître son état actuel aide à identifier le goulot d’étranglement. Le diagramme doit refléter ces états, soit dans les bulles de processus, soit dans du texte complémentaire.
Une méthode efficace consiste à annoter les flux de données avec des transitions d’état. Une étiquette sur la flèche peut indiquer « Statut : En attente ». Cela rend le flux d’information sur l’état aussi visible que le flux des données elles-mêmes. Cela clarifie que le système suit l’évolution même lorsque le processus principal est inactif.
La documentation doit également couvrir le traitement des erreurs. Que se passe-t-il si le processus asynchrone échoue ? Les données sont-elles retournées dans la file d’attente ? Sont-elles déplacées vers un magasin de lettres mortes ? Inclure ces chemins dans le diagramme garantit que les modes d’échec sont compris. Cela évite l’hypothèse que tout processus réussit toujours.
Éviter l’ambiguïté dans les files d’attente 📥
Les files d’attente sont la représentation la plus courante de l’asynchronie, mais elles sont aussi les plus ambigües. Une file d’attente peut être une liste simple, une pile à priorité ou un cluster distribué. Le diagramme doit préciser la nature de la file d’attente si cela affecte la logique. Par exemple, une file FIFO garantit l’ordre, tandis qu’une file à priorité ne le fait pas.
Si l’ordre est important, étiquetez le magasin de données avec « File FIFO ». Si le système permet un traitement hors ordre, étiquetez-le « File à priorité ». Cette distinction influence la manière dont les processus en aval traitent les données. Elle affecte également la conception du système. Une file FIFO peut nécessiter plus de mécanismes de verrouillage qu’une file à priorité.
En outre, considérez la capacité de la file d’attente. A-t-elle une limite ? Que se passe-t-il quand elle est pleine ? Ce sont des décisions architecturales qui doivent figurer dans le diagramme ou ses notes. Une file limitée empêche les plantages du système mais introduit une pression arrière. Une file illimitée évite la pression arrière mais expose au risque d’épuisement de la mémoire. Le diagramme doit suggérer ces contraintes.
Vérification de l’intégrité logique 🔍
Une fois le diagramme terminé, une revue rigoureuse est nécessaire. L’objectif est de vérifier que le flux a un sens logique. Chaque entrée a-t-elle une sortie ? Y a-t-il des processus orphelins qui ne reçoivent pas de données ? Y a-t-il des cycles pouvant entraîner des boucles infinies ?
Dans les systèmes asynchrones, vérifiez les dépendances circulaires. Le processus A attend le processus B, et le processus B attend le processus A. C’est un blocage. Le diagramme ne doit pas montrer cela. Si le système est conçu pour y faire face, le diagramme doit montrer le mécanisme de délai ou de réessai. Une simple flèche de A vers B et retour à A est insuffisante.
Une autre vérification porte sur l’intégrité des données. Le processus asynchrone modifie-t-il des données lues par un autre processus ? Si oui, il doit y avoir un mécanisme pour éviter la corruption. Le diagramme doit montrer un magasin de données versionné ou un mécanisme de verrouillage. Cela garantit que le modèle visuel correspond aux exigences techniques.
Affinement itératif 🔄
La modélisation est rarement une tâche ponctuelle. Au fur et à mesure que le système évolue, le diagramme doit évoluer lui aussi. De nouvelles fonctionnalités peuvent introduire de nouveaux chemins asynchrones. Des files d’attente anciennes peuvent être supprimées. Des mises à jour régulières maintiennent la documentation précise. Cela est particulièrement important pour les flux asynchrones, qui sont sujets à un écart entre la conception et l’implémentation.
Lors de modifications, mettez à jour la légende et les notes. Si un nouveau symbole est ajouté, assurez-vous que toute l’équipe sait ce qu’il signifie. La cohérence est la base d’un diagramme utile. Si le diagramme est confus, il échoue à sa fonction principale : la communication. Un diagramme qui nécessite une longue explication contredit l’objectif même de la modélisation visuelle.
Des revues régulières avec l’équipe de développement aident à repérer les lacunes. Les développeurs découvrent souvent des cas limites que la conception initiale a manqués. Ils peuvent signaler un scénario où la file d’attente est bloquée. Ils peuvent proposer un autre modèle pour gérer les délais d’attente. Intégrer ces retours améliore le modèle et le système final.
Pensées finales sur la clarté 🌟
Gérer les processus asynchrones dans les diagrammes de flux consiste à gérer les attentes. Il s’agit de rendre visible l’invisible. En utilisant des files d’attente, des événements et des étiquettes claires, vous créez une carte qui guide l’équipe à travers des scénarios de temporisation complexes. L’objectif n’est pas de capturer chaque milliseconde d’exécution, mais de capturer la structure logique du délai.
Lorsqu’elle est correctement réalisée, le diagramme devient un outil de réduction des risques. Il met en évidence les endroits où les données pourraient être bloquées. Il montre où des goulets d’étranglement de performance pourraient survenir. Il garantit que tout le monde comprend les exigences de temporisation. Cette compréhension partagée est la clé pour construire des systèmes robustes et réactifs.