











Concevoir une machine à états robuste est l’une des tâches les plus critiques dans l’architecture des systèmes. Lorsqu’elle est correctement mise en œuvre, un diagramme d’états apporte clarté, prévisibilité et maintenabilité. Cependant, lorsque la logique est défectueuse, le système peut entrer dans un état où aucune progression ultérieure n’est possible. Cela s’appelle un blocage. Dans un diagramme de machine à états, un blocage survient lorsque le système atteint un état d’où aucune transition valide ne peut être effectuée, bloquant ainsi l’exécution indéfiniment. ⏸️
Ce guide explore les mécanismes de conception des machines à états, en se concentrant spécifiquement sur l’identification et la prévention des blocages. Nous aborderons les gardes de transition, les actions d’entrée et de sortie, les régions concurrentes et les stratégies de validation. En suivant ces approches structurées, vous pouvez vous assurer que vos diagrammes d’états restent résilients dans diverses conditions. 🔒
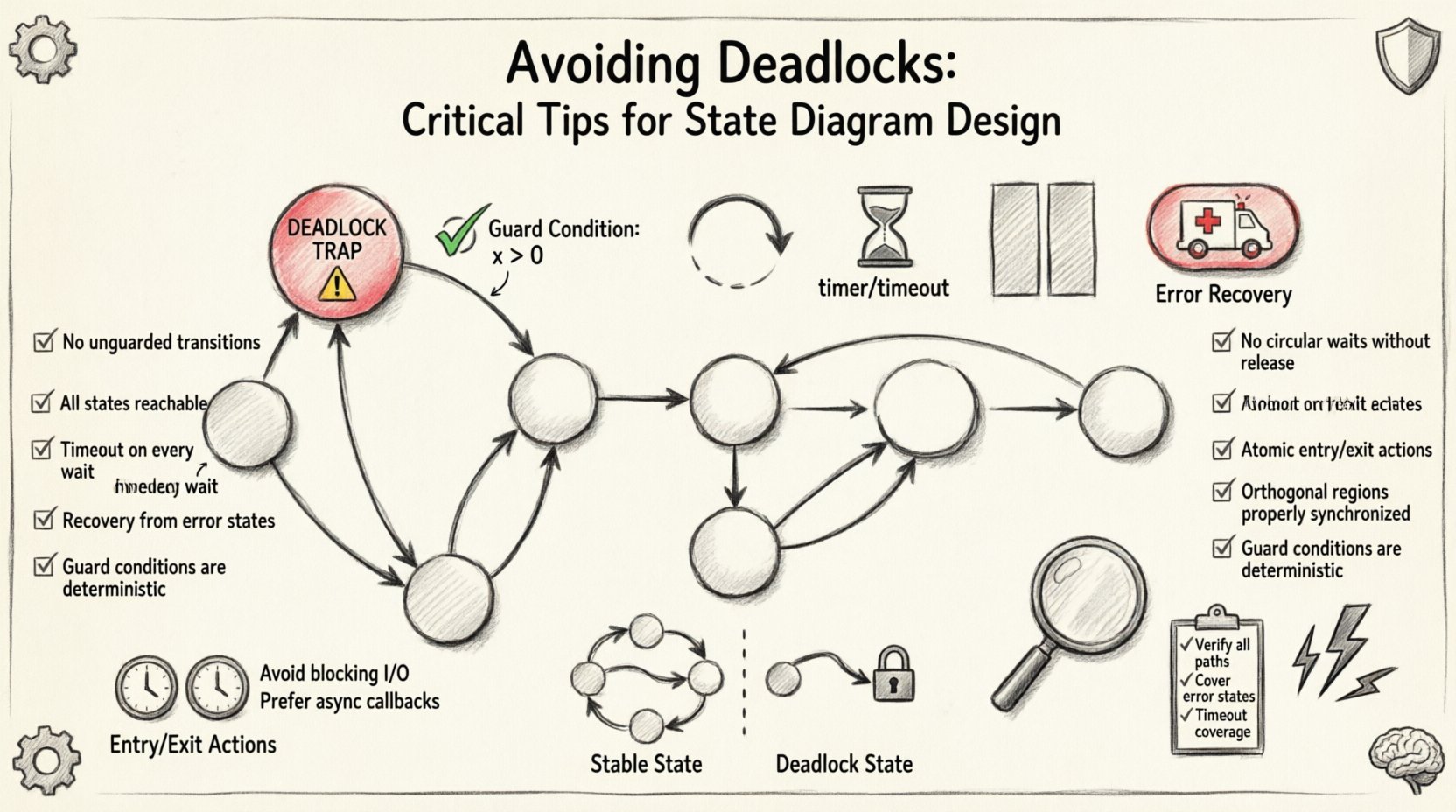
🧠 Comprendre les blocages dans les machines à états
Un blocage dans une machine à états finie (FSM) représente une interruption logique. Contrairement à une erreur d’exécution qui pourrait faire planter l’application, un blocage entraîne souvent l’apparence de gel du système tout en continuant à fonctionner. Le moteur est actif, mais il ne peut exécuter aucune commande car l’état actuel ne possède pas de transitions sortantes satisfaisant les conditions de déclenchement. 🔍
Pour concevoir efficacement, il faut comprendre l’anatomie d’un scénario de blocage. Il est rarement dû à une seule ligne de code manquante. En revanche, il résulte souvent d’interactions complexes entre plusieurs états, des gardes et des événements externes. Voici les caractéristiques fondamentales d’un état bloqué :
- Aucune transition sortante : L’état ne possède aucune flèche partant de lui.
- Transitions inaccessibles : Toutes les flèches sortantes ont des conditions de garde qui ne peuvent jamais être vraies compte tenu des données actuelles.
- Absence de chemins par défaut : Il n’existe aucune transition de secours pour gérer les entrées imprévues.
- Détention de ressources : Le système détient une ressource (comme un verrou ou une connexion) mais attend une autre condition qui ne se produira jamais.
Empêcher ces scénarios exige une philosophie de conception proactive plutôt qu’une débogage réactif. Examinons en détail les causes profondes. 📉
⚠️ Causes courantes des blocages dans la conception des états
Les blocages ne sont pas des accidents aléatoires ; ils sont des conséquences prévisibles de choix de conception spécifiques. Comprendre ces modèles vous aide à les éviter avant qu’ils n’affectent la production. Voici les principaux responsables des blocages dans les machines à états.
1. Gardes de transition manquantes
Lors de la conception des transitions, chaque flèche partant d’un état représente un chemin possible vers l’avant. Si un état a plusieurs entrées possibles (événements), mais que seules certaines sont mappées à des transitions, le système s’arrête lorsque survient un événement non mappé. Cela est souvent appelé un « état piège ». ❌
- Le problème : Une machine à états s’attend à des déclencheurs spécifiques. Si un déclencheur imprévu arrive, et qu’aucune transition ne le gère, le système reste bloqué.
- La solution : Assurez-vous que chaque état prend en compte tous les événements définis, ou mettez en œuvre un gestionnaire par défaut global pour capturer les entrées imprévues.
2. Conditions de garde conflictuelles
Les conditions de garde sont des expressions booléennes qui doivent être évaluées à vrai pour qu’une transition se déclenche. Une erreur courante survient lorsque deux transitions partagent le même état source et le même événement, mais que leurs conditions de garde sont mutuellement exclusives ou ne couvrent aucun scénario possible. 🧩
- Le problème : Vous définissez la transition A (si le score > 10) et la transition B (si le score < 5). Que se passe-t-il si le score est exactement 10 ? Si la logique est stricte, les deux pourraient échouer.
- La solution : Revoyez les conditions de garde pour les cas limites. Assurez-vous que l’union de toutes les conditions de garde pour un événement spécifique couvre l’ensemble du domaine d’entrée.
3. Dépendances circulaires
Dans les systèmes complexes, les états peuvent dépendre de l’état d’autres états ou de processus externes. Si l’état A attend que l’état B se termine, et que l’état B attend que l’état A reconnaisse, aucun des deux ne progresse. Il s’agit d’un blocage classique de synchronisation. ⏳
- Le problème :La logique est imbriquée de telle sorte qu’une reconnaissance mutuelle est requise avant toute progression.
- La solution :Rompre le cycle en introduisant des délais ou en permettant à un processus de progresser sans confirmation immédiate de l’autre.
4. Gestion incorrecte des états historiques
Les états historiques permettent à un système de se souvenir de son état précédent lors de sa réentrée. Si ce n’est pas correctement implémenté, un état historique peut pointer vers un état qui n’est plus valide ou qui a été supprimé. 🔄
- Le problème :La machine tente de passer à un état historique qui n’existe plus ou qui est inaccessible.
- La solution :Valider que les cibles historiques sont toujours actives lorsque la machine redémarre ou est réinitialisée.
🛡️ Modèles de conception pour éviter les blocages
Une fois que vous comprenez les risques, vous pouvez appliquer des modèles spécifiques pour les atténuer. Ces modèles ne sont pas spécifiques au logiciel ; ils s’appliquent à tout langage de modélisation ou cadre d’implémentation. 🛠️
1. Le modèle d’état par défaut
Chaque machine à états doit avoir un point d’entrée défini. Il s’agit généralement de l’état initial. Cependant, au-delà de l’état initial, chaque autre état devrait idéalement avoir un chemin par défaut. Si un événement ne correspond pas à une condition spécifique, le système doit revenir à un comportement par défaut sûr. 📍
- Implémentation :Créer une transition « tout capturer » pour chaque état qui gère les événements inconnus de manière fluide.
- Avantage :Empêche le système d’entrer dans un état non défini lorsqu’une entrée inattendue se produit.
2. Le modèle de garde avec délai
Parfois, un état doit attendre un événement externe qui pourrait ne jamais arriver. Pour éviter une attente indéfinie, vous pouvez introduire un minuteur. Si l’événement n’arrive pas dans une durée spécifiée, une transition de délai expire. ⏱️
- Implémentation :Ajouter une transition déclenchée par un événement basé sur le temps (par exemple, « Minuteur expiré »).
- Avantage :Assure que le système avance toujours, même si la condition principale n’est pas remplie.
3. Le modèle d’état parallèle
Dans les flux de travail complexes, un seul état ne peut pas capturer toutes les activités concurrentes. Les régions orthogonales vous permettent de diviser un état en plusieurs sous-états indépendants. Cela réduit la complexité des gardes de transition. ⚡
- Implémentation :Utiliser des états composés avec plusieurs régions qui s’exécutent simultanément.
- Avantage : Simplifie la logique en séparant les préoccupations. Si une région est en deadlock, l’autre peut continuer à fonctionner ou signaler l’erreur.
4. L’état de récupération des erreurs
Concevez un état spécifique dédié à la gestion des erreurs. Si le système détecte une anomalie, il passe immédiatement à cet état. À partir de là, il peut tenter de réinitialiser, de réessayer ou d’alerter un opérateur. 🚑
- Mise en œuvre : Ajoutez un état dédié « Erreur » ou « Récupération » accessible depuis plusieurs points.
- Avantage : Isole l’erreur et fournit une voie claire de récupération, plutôt que de laisser le système dans un état défectueux.
📊 Comparaison : Blocage vs. État stable
Pour visualiser la différence entre un état sain et un blocage, considérez le tableau de comparaison suivant. Cela met en évidence les différences structurelles dans la conception.
| Fonctionnalité | État stable | État de blocage |
|---|---|---|
| Transitions | Au moins une transition sortante valide existe. | Aucune transition sortante ne satisfait les conditions actuelles. |
| Logique de garde | Les gardes couvrent tous les scénarios d’entrée pertinents. | Les gardes sont mutuellement exclusives ou incomplètes. |
| Gestion des événements | Les événements déclenchent des actions attendues. | Les événements sont ignorés ou provoquent une interruption. |
| Récupération | Le système se corrige lui-même ou passe à la phase suivante. | Le système nécessite une intervention externe pour redémarrer. |
🧪 Stratégies de validation et de test
La conception n’est que la moitié de la bataille. Vous devez valider le diagramme pour vous assurer qu’il résiste aux contraintes. Tester les machines d’état nécessite une approche différente de celle utilisée pour tester les fonctions standards. 🧪
1. Vérification de modèle
La vérification de modèle est une méthode de vérification formelle. Elle prouve mathématiquement qu’une machine d’état satisfait certaines propriétés, telles que « aucun état n’est accessible où un blocage existe ». Cela est particulièrement efficace pour les systèmes critiques. 🔢
- Technique : Utilisez des outils de méthodes formelles pour explorer l’espace d’état entier.
- Résultat :Une garantie mathématique selon laquelle le système ne peut pas entrer dans un état de blocage.
2. Test de couverture des états
Assurez-vous que chaque état et chaque transition est testé au moins une fois. Cela s’appelle la couverture des états. Si un état n’est pas testé, vous ne pouvez pas savoir s’il contient une condition de blocage cachée. 🎯
- Technique :Écrivez des cas de test qui obligent le système à entrer dans chaque état défini.
- Résultat :Vérification que les transitions s’activent correctement à partir de chaque point d’entrée.
3. Test de charge sur les entrées
Envoyez des entrées non valides, nulles ou inattendues au système. Une machine à états robuste ne doit pas planter ou se bloquer lorsqu’elle reçoit des données erronées. Elle doit soit rejeter l’entrée, soit passer à un état sûr. 🌪️
- Technique :Générez des entrées aléatoires ou aux limites et observez le comportement.
- Résultat :Identification des cas limites qui mènent à des blocages.
4. Analyse statique
Avant d’exécuter le code, analysez la structure du diagramme. Recherchez les états sans flèches sortantes. Recherchez les boucles qui ne se terminent jamais. Les outils peuvent souvent détecter ces motifs automatiquement. 🔎
- Technique :Exécutez des scripts de vérification ou d’analyse statique sur les fichiers de définition des états.
- Résultat :Détection précoce des erreurs structurelles.
🔄 Gestion de la concurrence et des états parallèles
La concurrence ajoute de la complexité. Lorsque plusieurs régions fonctionnent simultanément, des blocages peuvent survenir à cause de problèmes de synchronisation. Vous devez vous assurer que les chemins parallèles ne se bloquent pas mutuellement. 🏗️
1. Régions indépendantes
Assurez-vous que les états parallèles sont véritablement indépendants. Si l’état A dans la région 1 a besoin de données de l’état B dans la région 2, vous introduisez une dépendance. Cette dépendance peut devenir un goulot d’étranglement. 🚧
- Meilleure pratique :Minimisez le partage de données entre les régions orthogonales.
- Alternative :Utilisez un bus d’événements pour communiquer entre les régions sans blocage direct.
2. Points de synchronisation
Parfois, les états doivent être synchronisés. Par exemple, la région A doit terminer avant que la région B ne commence. Si vous implémentez cela manuellement, vous risquez un blocage. Utilisez les constructions de synchronisation intégrées fournies par votre framework. ⚙️
- Meilleure pratique : Évitez les mécanismes de verrouillage manuels sauf si absolument nécessaires.
- Alternative : Utilisez des états de jointure qui attendent que toutes les voies entrantes se terminent naturellement.
⚙️ Actions d’entrée et de sortie
Les actions d’entrée et de sortie sont des extraits de code qui s’exécutent lors de l’entrée ou de la sortie d’un état. Ce sont des sources courantes de blocages subtils. ⚠️
1. Actions d’entrée bloquantes
Si une action d’entrée effectue une tâche longue (comme une requête réseau) sans délai, le système ne peut pas quitter cet état jusqu’à ce que la tâche soit terminée. Si la tâche bloque, la machine d’états bloque. 🕸️
- Meilleure pratique : Maintenez les actions d’entrée légères et non bloquantes.
- Alternative : Transférez les tâches lourdes vers des travailleurs en arrière-plan et passez à un état « En cours de traitement ».
2. Boucles infinies dans les actions de sortie
Une action de sortie ne doit jamais déclencher une transition qui ramène immédiatement au même état. Cela crée une boucle qui consomme des ressources sans progrès. 🔄
- Meilleure pratique : Assurez-vous que les actions de sortie ne réactivent pas la même transition d’état.
- Alternative : Utilisez des drapeaux pour empêcher le déclenchement récursif des actions.
📝 Liste de vérification pour les diagrammes d’états
Avant de déployer une machine d’états, passez en revue cette liste de vérification. Elle couvre les zones critiques où les blocages se cachent généralement. ✅
| Élément de vérification | Réussi / Échoué | Remarques |
|---|---|---|
| Tous les états sont-ils accessibles à partir de l’état initial ? | ||
| Chaque état a-t-il au moins une transition sortante ? | ||
| Toutes les conditions de garde sont-elles logiquement cohérentes (pas de lacunes) ? | ||
| Y a-t-il des mécanismes de délai pour les états d’attente ? | ||
| Les régions parallèles évitent-elles les dépendances directes sur les données ? | ||
| Existe-t-il un état de récupération d’erreur global ? | ||
| Les actions d’entrée ont-elles été testées pour un comportement bloquant ? |
🔍 Approfondissement : Scénarios de cas limites
Même avec une bonne conception, des cas limites peuvent passer inaperçus. Voici des scénarios précis où les blocages se manifestent souvent dans les environnements de production. 🌐
1. Le piège de la condition de course
Lorsque deux événements se produisent simultanément, l’ordre de traitement est crucial. Si la machine d’état traite l’Événement A avant l’Événement B, elle pourrait emprunter un chemin qui entraîne un blocage. Si elle traite B avant A, elle pourrait réussir. ⚡
- Atténuation :Mettez en file d’attente les événements et traitez-les séquentiellement. Assurez-vous que l’ordre des événements n’affecte pas la validité de l’état final.
2. Le piège de l’épuisement des ressources
Un état pourrait attendre une ressource (comme une connexion à la base de données). Si le pool est épuisé, l’attente est infinie. Cela ressemble à un blocage, mais il s’agit en réalité d’un problème de ressources. 💾
- Atténuation :Implémentez des délais d’expiration des connexions et des états de secours qui permettent une dégradation progressive des fonctionnalités.
3. Le piège de l’écart de configuration
Le diagramme pourrait être conçu pour l’État A, mais le fichier de configuration indique l’État B. Si la logique de transition dépend de valeurs de configuration manquantes, le système s’arrête.
- Atténuation :Validez la configuration par rapport au schéma du diagramme d’état au démarrage.
🚀 Considérations finales pour une conception robuste
Construire une machine d’état résistante aux blocages repose sur la discipline. Cela exige de prévoir les modes de défaillance et de concevoir des chemins pour les contourner. En vous concentrant sur des transitions claires, une logique de garde complète et une gestion robuste des erreurs, vous créez des systèmes résilients face aux changements. 🛡️
Souvenez-vous que les diagrammes d’état sont des documents vivants. À mesure que les exigences évoluent, le diagramme doit évoluer lui aussi. Des révisions et des refactorisations régulières garantissent que les nouvelles fonctionnalités n’introduisent pas d’anciens bogues. Gardez le modèle simple, la logique explicite et les chemins de récupération clairs. 🔄
Quand vous privilégiez la stabilité plutôt que la vitesse dans la phase de conception, vous économisez un temps considérable en maintenance ultérieure. Une machine d’état bien conçue est le pilier du comportement fiable du logiciel. Investissez l’effort dans la conception, et le système fonctionnera de manière cohérente. 📈