










In der modernen Informationsarchitektur steht die Datenintegrität als Grundlage für zuverlässiges Systemverhalten. Wenn Daten in eine Verarbeitungsumgebung eintreten, bergen sie potenzielle Risiken, die den Betrieb stören, die Sicherheit gefährden oder nachgelagerte Ausgaben beschädigen können. Die Überprüfung von Systemeingaben ist nicht nur eine Sicherheitskontrolle; sie ist eine grundlegende logische Anforderung, die in die Systemgestaltung eingebettet ist. Durch die Nutzung von Flusslogik innerhalb von Datenflussdiagrammen (DFDs) können Ingenieure genau darstellen, wo die Überprüfung stattfindet, wie Fehler behandelt werden und wie Daten durch die Architektur fließen. Dieser Ansatz stellt sicher, dass jedes Informationen, das das System betritt, die erforderlichen Kriterien erfüllt, bevor es die Geschäftslogik beeinflusst.
Dieser Artikel untersucht die Mechanismen der Eingabeverifizierung aus der Perspektive der Flusslogik. Wir werden untersuchen, wie Überprüfungsregeln visuell dargestellt werden können, wie Entscheidungspunkte für die Datenakzeptanz strukturiert werden und wie Fehlerzustände behandelt werden können, ohne die Flusskontinuität zu unterbrechen. Das Verständnis dieser Mechanismen ermöglicht Architekten, Systeme zu entwickeln, die widerstandsfähig gegenüber fehlerhaften Daten und externen Bedrohungen sind.
Verständnis von Datenflussdiagrammen in der Validierung 📊
Datenflussdiagramme bieten eine visuelle Darstellung, wie Informationen durch ein System fließen. Sie zeigen Prozesse, Datenbanken, externe Entitäten und die Daten selbst. Im Kontext der Validierung wird das DFD zu einer Karte des Vertrauens. Es zeigt, wo Daten empfangen werden, wo sie überprüft werden und wo sie gespeichert oder verworfen werden.
Ein Standard-DFD besteht aus vier primären Elementen:
- Prozess: Eine Umwandlung von Daten. Hier befindet sich typischerweise die Validierungslogik.
- Datenbank: Ein Speicherort, an dem Daten gespeichert werden. Die Validierung muss erfolgen, bevor Daten in eine Datenbank gelangen.
- Externe Entität: Eine Quelle oder Ziel von Daten außerhalb der Systemgrenzen. Die Eingabe stammt hierher.
- Datenfluss: Die Bewegung von Daten zwischen Elementen. Validierungsprüfungen finden entlang dieser Pfade statt.
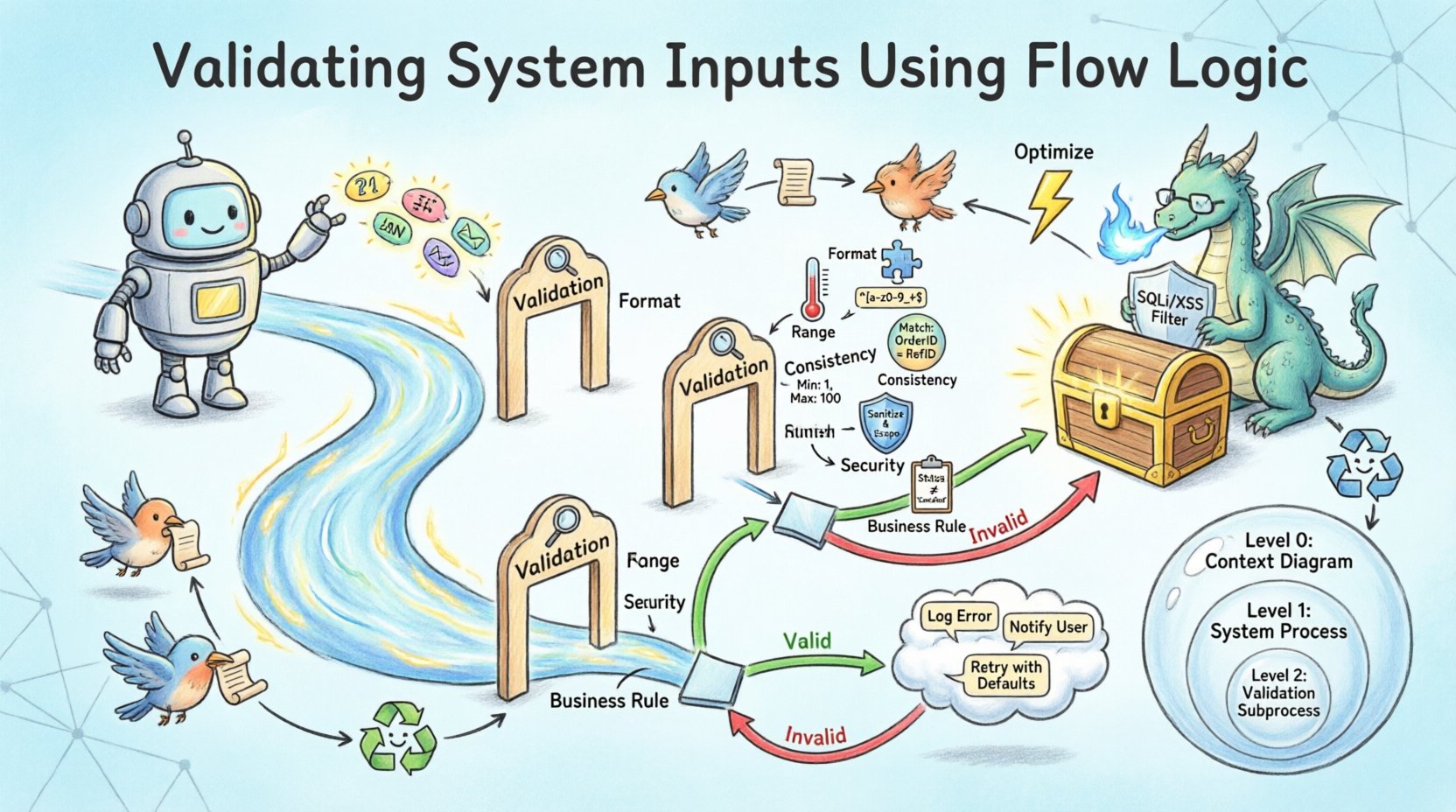
Beim Entwurf für die Validierung wird das Prozesselement entscheidend. Es reicht nicht aus, Daten einfach von Punkt A nach Punkt B zu bewegen. Der Prozess muss die Daten anhand einer Reihe von Regeln bewerten. In der Darstellung wird dies oft durch einen spezifischen Unterprozess dargestellt, der als „Validierung“ oder „Säuberung“ bezeichnet ist. Dieser visuelle Hinweis erinnert Entwickler daran, dass hier Logik existiert, um die Eingaben zu filtern.
Zuordnung der Validierungslogik zu Flussstrukturen 🧠
Flusslogik bezeichnet die Abfolge von Operationen, die den Pfad der Daten bestimmen. Bei der Validierung legt diese Logik fest, ob die Daten zur nächsten Stufe weitergeleitet werden oder an einen Fehlerhandler umgeleitet werden. Die Umsetzung erfordert ein klares Verständnis der Entscheidungspunkte.
Betrachten Sie ein Dateneingabefeld, das Benutzerinformationen sammelt. Die Flusslogik muss die folgenden Attribute überprüfen:
- Vorhandensein:Ist das Feld ausgefüllt?
- Typ:Ist die Eingabe der richtige Datentyp (z. B. Ganzzahl gegenüber Zeichenkette)?
- Bereich:Liegt der Wert innerhalb akzeptabler Grenzen?
- Format:Stimmt die Zeichenkette mit einem erforderlichen Muster überein (z. B. E-Mail-Adresse)?
Im DFD erzeugen diese Überprüfungen Verzweigungen. Wenn die Daten alle Prüfungen bestehen, fließt der Datenstrom weiter zum Hauptprozess. Wenn sie fehlschlagen, wird der Datenstrom an einen Fehlerbehandlungsprozess umgeleitet. Diese Verzweigung ist für eine robuste Architektur unerlässlich. Ohne sie könnte fehlerhafte Daten stillschweigend weitergeleitet werden, was zu Berechnungsfehlern oder Sicherheitslücken führen könnte.
Der Entscheidungsmechanismus
Entscheidungspunkte sind die Stellen, an denen der Fluss sich teilt. In Flusslogik-Diagrammen wird dies oft als Raute oder ein spezifischer Prozessknoten dargestellt, der zwei unterschiedliche Datenströme ausgibt: einen mit der Bezeichnung „Gültig“ und einen mit der Bezeichnung „Ungültig“. Der „Gültige“-Fluss setzt die Hauptverarbeitungskette fort. Der „Ungültige“-Fluss löst eine Fehlerantwort oder eine Korrekturschleife aus.
Es ist wichtig, zwischen Client-seitiger und Server-seitiger Validierung im Diagramm zu unterscheiden. Während die Client-seitige Validierung die Benutzererfahrung verbessert, ist die Server-seitige Validierung der echte Schutzwall. Im DFD sollte die Server-seitige Prüfung die letzte Barriere vor dem Zugriff auf die Datenbank sein. Dadurch wird sichergestellt, dass selbst wenn die Oberfläche umgangen wird, das Kernsystem geschützt bleibt.
Arten von Eingabeverifizierungsregeln 🛡️
Validierung ist kein monolithischer Begriff. Sie umfasst mehrere Schichten der Überprüfung. Jede Schicht dient einem anderen Zweck und erfordert unterschiedliche Implementierungsstrategien innerhalb der Flusslogik.
| Validierungstyp | Zweck | Beispiellogik |
|---|---|---|
| Formatüberprüfung | Stellt sicher, dass die Daten der erwarteten Struktur entsprechen | Regex-Abgleich für Telefonnummern |
| Bereichsüberprüfung | Stellt sicher, dass die Daten innerhalb numerischer Grenzen liegen | Das Alter muss zwischen 18 und 120 liegen |
| Konsistenzüberprüfung | Stellt sicher, dass die Daten mit anderen Eingaben übereinstimmen | Das Enddatum muss nach dem Startdatum liegen |
| Sicherheitsüberprüfung | Verhindert die Einschleusung von schadhafter Code | Bereinigt HTML-Tags in Textfeldern |
| Geschäftsregel-Überprüfung | Stellt sicher, dass die Daten den operativen Einschränkungen entsprechen | Der Rabatt darf 50 % nicht überschreiten |
Die Integration dieser Regeln in die Flusslogik erfordert eine sorgfältige Abfolge. Die Sicherheitsüberprüfung sollte in der Regel früh im Prozess erfolgen, um die kostspielige Verarbeitung schädlicher Datenpakete zu verhindern. Die Formatüberprüfung ist in der Regel der erste Schritt, um sicherzustellen, dass die Datentypen korrekt sind, bevor logische Vergleiche durchgeführt werden. Die Überprüfung der Geschäftsregeln erfolgt oft zuletzt, da sie möglicherweise auf Daten angewiesen ist, die bereits normalisiert wurden.
Behandlung von Fehlerflüssen und Rückkopplungsschleifen 🔄
Ein robustes System lehnt ungültige Daten nicht nur ab; es verarbeitet die Ablehnung reibungslos. Hier kommt der „Ungültig“-Zweig der Flusslogik ins Spiel. Der Fehlerfluss muss zu einer Mechanismus führen, der den Benutzer oder den Systemadministrator über das Problem informiert, ohne sensible interne Details preiszugeben.
Im DFD sollte der Fehlerbehandlungsprozess Folgendes enthalten:
- Protokollierung: Erfasst die Fehlerdetails zur Fehlersuche. Dieser Fluss geht in einen Audit-Log-Datenspeicher.
- Benachrichtigung: Informiert den Benutzer. Dieser Fluss geht an die externe Entität (Benutzeroberfläche).
- Korrektur: Bietet einen Mechanismus zur Korrektur der Daten. Dies schafft eine Rückkopplungsschleife, bei der die Daten zur Eingabestufe zurückkehren.
Rückkopplungsschleifen sind für die Benutzerfreundlichkeit entscheidend. Wenn ein Benutzer ein Formular mit einer ungültigen E-Mail-Adresse absendet, sollte das System ihm erlauben, diese sofort zu korrigieren. In Flussbegriffen verlässt die Datenphase die Eingabephase nicht dauerhaft. Sie wird erneut anhand der Validierungslogik überprüft, bis sie bestanden wird oder der Benutzer die Aktion abbricht. Dies verhindert Sackgassen im Benutzerpfad.
Fehlerprotokollierung und Audit-Protokolle
Sicherheit und Compliance erfordern oft, dass Validierungsfehler protokolliert werden. Selbst wenn die Eingabe abgelehnt wird, könnte der Versuch selbst ein Hinweis auf einen Angriff sein. Daher sollte ein separater Datenfluss vom Validierungsprozess zum Audit-Log existieren. Dieser Fluss erfasst Zeitstempel, Quell-IP-Adressen und Art des Fehlers. Er arbeitet unabhängig vom Hauptdatenfluss, um sicherzustellen, dass Protokollierungsfehler die legale Verarbeitung nicht blockieren.
Integration der Validierung in Prozessstufen 🏗️
Datenflussdiagramme existieren oft auf verschiedenen Abstraktionsstufen. Ebene 0 bietet eine Übersicht auf hoher Ebene, während Ebene 1 und Ebene 2 spezifische Prozesse aufschlüsseln. Die Validierungslogik muss auf diesen Ebenen konsistent sein.
Ebene 0: Systemgrenze
Auf der höchsten Ebene wird die Validierung als Schleuse dargestellt. Die externe Entität sendet Daten, und das System akzeptiert oder lehnt sie ab. Das DFD zeigt die Eingangs- und Ausgangsgrenzen. Jegliche Daten, die an dieser Stufe der Validierung fehlschlagen, betreten niemals das interne System.
Ebene 1: Prozessaufsplitting
Beim Aufteilen des Systems erhalten bestimmte Prozesse Validierungsunterflüsse. Zum Beispiel könnte ein „Benutzerregistrierungs“-Prozess in „Identitätsprüfung“, „Passwortvalidierung“ und „Kontaktüberprüfung“ aufgeteilt werden. Jeder dieser Unterprozesse verfügt über eine eigene Flusslogik. Das DFD auf dieser Ebene zeigt die interne Datenbewegung, die zur Durchführung dieser Prüfungen erforderlich ist.
Ebene 2: Detaillierte Logik
Auf der tiefsten Ebene ist die Logik vollständig definiert. Hier wird aus dem Diagramm die eigentliche Codestruktur abgeleitet. Die Flusslogik beschreibt hier die genaue Reihenfolge der Operationen. Zum Beispiel muss geprüft werden, ob ein Benutzername in der Datenbank existiert, bevor geprüft wird, ob das Format gültig ist, um zu verhindern, dass Informationen über vorhandene Benutzer preisgegeben werden.
Optimierung der Leistung während der Validierung ⚡
Die Validierungslogik fügt rechnerischen Overhead hinzu. Jede Prüfung erfordert Verarbeitungszeit. In Systemen mit hoher Datenmenge kann übermäßige Validierung zu einer Engstelle werden. Das DFD hilft dabei, wo Optimierungen erforderlich sind.
Strategien zur Optimierung umfassen:
- Frühes Beenden: Wenn eine grundlegende Prüfung fehlschlägt (z. B. leeres Feld), beenden Sie die Verarbeitung sofort. Führen Sie keine komplexen Logiken aus.
- Caching: Wenn die Validierung von externen Daten abhängt (z. B. Überprüfung einer Benutzer-ID gegen eine Liste gesperrter Konten), speichern Sie diese Daten im Cache, um Datenbankaufrufe zu reduzieren.
- Asynchrone Verarbeitung: Für nicht kritische Validierungen verschieben Sie die Prüfung in eine Hintergrundwarteschlange. Dadurch bleibt der primäre Datenfluss schnell.
Wenn Sie diese Optimierungen im DFD darstellen, verwenden Sie unterschiedliche Datenflüsse für synchrone und asynchrone Aufgaben. Dies macht deutlich, welche Validierungen den Benutzer blockieren und welche im Hintergrund laufen. Es hilft auch bei Lasttestszenarien, bei denen das Systemverhalten unter Belastung verstanden werden muss.
Sicherheitsaspekte der Flusslogik 🔒
Ungültige Eingaben sind ein primärer Angriffsvektor für Angriffe wie SQL-Injection, Cross-Site Scripting und Pufferüberläufe. Die Flusslogik, die für die Validierung konzipiert ist, wirkt wie eine Firewall. Die Gestaltung muss jedoch korrekt sein.
Eine häufige Herausforderung bei der Gestaltung ist die Annahme, dass die Eingaben von einer vertrauenswürdigen Quelle stammen. Im DFD sollte jede externe Entität als potenziell feindlich betrachtet werden. Der Validierungsprozess muss die Daten säubern, bevor sie mit Datenbanken oder Befehlszeilen interagieren. Diese Säuberung ist ein spezifischer Prozessknoten im Diagramm.
Zusätzlich muss die Flusslogik Informationssicherheitsverluste verhindern. Wenn eine Validierungsfehlermeldung offenbart, dass ein Benutzername existiert, kann ein Angreifer dies nutzen, um Konten aufzulisten. Der Fehlerfluss sollte generische Nachrichten (z. B. „Ungültige Anmeldeinformationen“) liefern, anstatt spezifische Gründe (z. B. „Benutzername nicht gefunden“). Diese Feinheit sollte in der Beschreibung des Fehlerbehandlungsprozesses erfasst werden.
Testen und Überprüfen von Validierungsflüssen ✅
Sobald die Flusslogik entworfen ist, muss sie überprüft werden. Der Test umfasst das Senden von Daten über die DFD-Pfade, um sicherzustellen, dass die Logik korrekt ist. Dies geschieht oft mithilfe von Einheitstests für einzelne Validierungsregeln und Integrations-Tests für den gesamten Fluss.
Testfälle sollten folgendes abdecken:
- Glücklicher Pfad: Gültige Daten bestehen alle Prüfungen und erreichen den Datenspeicher.
- Randfälle: Daten an den Grenzen von Bereichen (z. B. Minimal- und Maximalwerte).
- Falsch formatierte Daten: Daten mit falschen Typen oder unerwarteten Zeichen.
- Fehlende Daten: Daten, bei denen erforderliche Felder fehlen.
Wenn das DFD korrekt ist, sollten die Testergebnisse mit den visualisierten Flüssen übereinstimmen. Wenn ein Testfall auf eine Weise fehlschlägt, die vom Diagramm nicht vorhergesagt wurde, muss das DFD aktualisiert werden. Dieser iterativen Prozess stellt sicher, dass die Dokumentation eine wahre Abbildung des Systemverhaltens bleibt.
Fazit zur strukturierten Validierung 📝
Die Validierung von Systemeingaben mithilfe von Flusslogik wandelt eine Sicherheitsanforderung in einen strukturellen Bestandteil der Architektur um. Durch die Abbildung von Validierungsregeln in Datenflussdiagrammen können Teams visualisieren, wo Daten überprüft werden, wie Fehler behandelt werden und wie Informationen durch das System fließen. Diese Klarheit reduziert Mehrdeutigkeiten, verbessert die Kommunikation zwischen Designern und Entwicklern und führt letztendlich zu stabilerer Software. Die Integration von Entscheidungspunkten, Fehlerflüssen und Sicherheitsprüfungen stellt sicher, dass das System widerstandsfähig gegenüber dem unvermeidlichen Rauschen der externen Welt bleibt.
Je komplexer die Systeme werden, desto kritischer wird die Abhängigkeit von strukturierter Flusslogik. Sie dient als Bauplan zur langfristigen Aufrechterhaltung der Datenintegrität. Indem Architekten den hier aufgezeigten Prinzipien folgen, können sie Pipelines aufbauen, die nichts vertrauen und alles überprüfen, wodurch die Langlebigkeit und Zuverlässigkeit des Datenökosystems gewährleistet wird.