










Der Aufbau robuster Software-Systeme erfordert mehr als nur funktionale Code-Schreibweise. Es erfordert einen strukturierten Ansatz zur Verwaltung des Lebenszyklus von Daten und Prozessen. Eine Zustandsmaschine ist ein grundlegendes Werkzeug dafür und bietet eine klare Karte, wie ein System von einem Zustand zum anderen wechselt. Bei der Integration von Zustandsdiagrammen mit dauerhafter Speicherung und externen Diensten steigt die Komplexität erheblich. Dieser Leitfaden untersucht die technischen Muster, die erforderlich sind, um Zustandslogik effektiv mit Datenbankoperationen und API-Interaktionen zu verbinden.
Zustandsmaschinen sind nicht bloß theoretische Konstrukte; sie sind praktische Implementierungen, die den Datenfluss bestimmen. Unabhängig davon, ob die Auftragsverarbeitung, die Benutzer-Onboarding-Prozesse oder die Workflow-Automatisierung verwaltet werden, ist die Integrität des Zustands von entscheidender Bedeutung. Die Integration dieser Logik mit Datenbanken stellt sicher, dass Zustandsänderungen dauerhaft sind. Die Verbindung mit APIs ermöglicht es dem System, auf externe Auslöser zu reagieren. Dieses Dokument beschreibt die architektonischen Überlegungen, Implementierungsmuster und Strategien zur Risikominderung für diese Integration.
Verständnis der Kernarchitektur 🧩
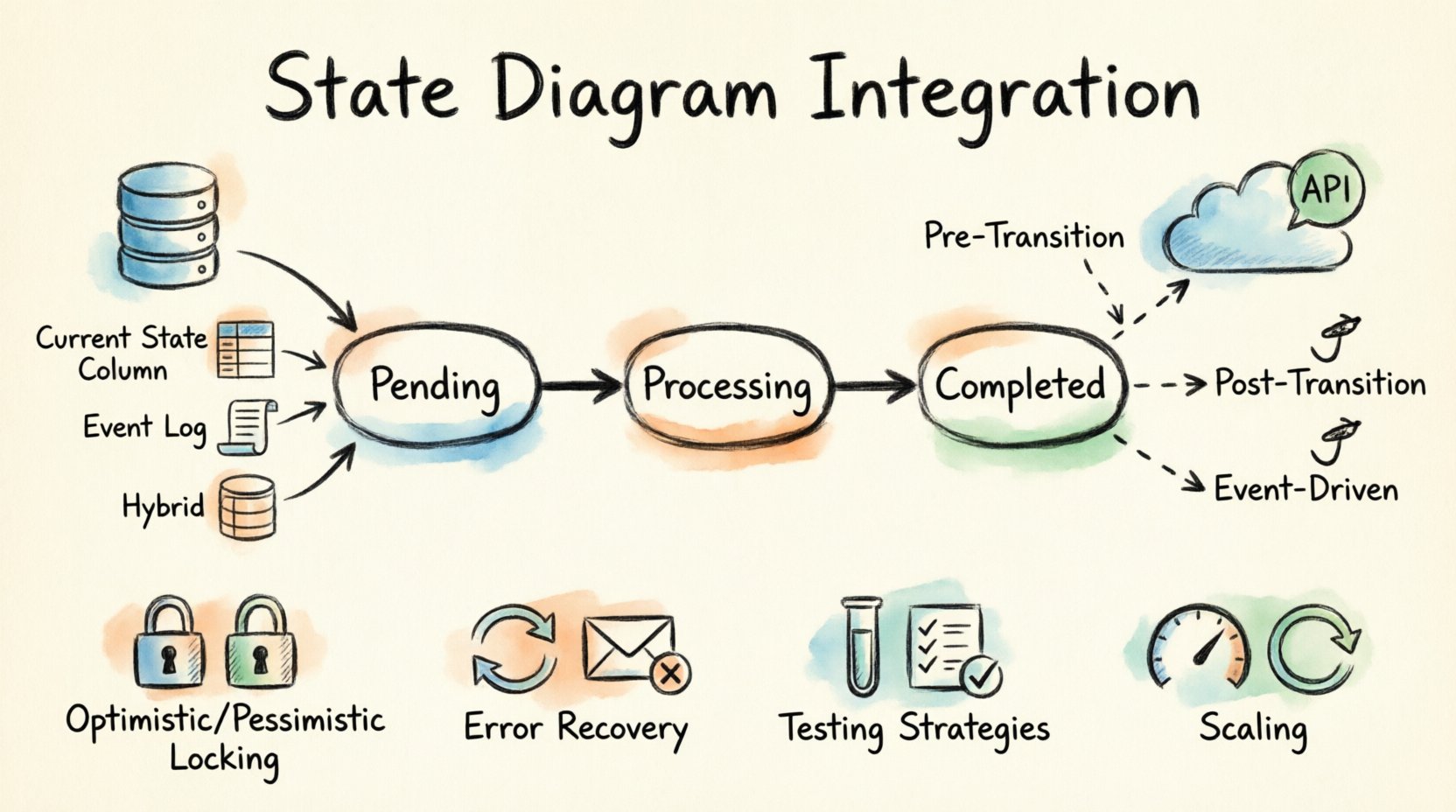
Bevor man sich mit Persistenz und Netzwerkkonzepten beschäftigt, ist es unerlässlich, die beteiligten Komponenten zu definieren. Eine Zustandsmaschine besteht aus drei Hauptelementen: Zuständen, Übergängen und Ereignissen. Das Verständnis der Wechselwirkungen dieser Elemente mit externen Systemen bildet die Grundlage der Integration.
- Zustände: Stellen den Zustand der Entität zu einem bestimmten Zeitpunkt dar. Beispiele hierfür sind Ausstehend, In Bearbeitung, oder Abgeschlossen.
- Übergänge: Die Bewegung von einem Zustand zum anderen, ausgelöst durch ein Ereignis. Hier wird die Logik angewendet.
- Ereignisse: Signale, die einen Übergang auslösen. Diese können von internen Systemaktionen oder externen API-Aufrufen stammen.
Bei der Integration muss der Zustand für die Datenbank sichtbar sein, und die Übergänge müssen in der Lage sein, API-Aufrufe auszulösen. Dies schafft eine Abhängigkeitskette, in der die Datenbank die Wahrheit hält und die API die Nebenwirkungen verwaltet.
Strategien zur Datenbank-Persistenz 🗄️
Persistenz ist der Prozess, den aktuellen Zustand zu speichern, sodass er einem System-Neustart oder einem Ausfall standhält. Wie Sie den Zustand speichern, beeinflusst Leistung, Konsistenz und Wiederherstellungsfähigkeit. Es gibt mehrere Muster, um Zustandsdiagramm-Knoten mit Datenbankzeilen zu verknüpfen.
Speicherung des aktuellen Zustands
Der häufigste Ansatz besteht darin, den aktuellen Zustands-Bezeichner in einer speziellen Spalte innerhalb der Haupt-Record-Tabelle zu speichern. Dadurch ist eine schnelle Abfrage ohne das Durchsuchen von Protokollen möglich.
- Implementierung: Fügen Sie eine
statusoderstate_codeSpalte zur Haupt-Entitätstabelle hinzu. - Vorteil: Schnelle Leseleistung zur Überprüfung des aktuellen Status.
- Risiko: Wenn die Zustandslogik komplex ist, kann eine einzelne Spalte nicht alle notwendigen Kontextinformationen erfassen.
Ereignisprotokoll-Speicherung
In einigen Architekturen wird der aktuelle Zustand nicht direkt gespeichert. Stattdessen wird die Folge von Ereignissen in einem Protokoll gespeichert. Der aktuelle Zustand wird durch Wiedergabe der Ereignisse ermittelt.
- Implementierung: Füge ein Ereignis jederzeit dann einer Tabelle hinzu, wenn ein Übergang stattfindet.
- Vorteil: Vollständiger Prüfungsverlauf und die Fähigkeit, die Vergangenheit wiederherzustellen.
- Risiko: Die Berechnung des aktuellen Zustands erfordert die Verarbeitung des gesamten Protokolls, was langsamer sein kann.
Vergleich von Speichermodellen
| Modell | Lesegeschwindigkeit | Schreibkomplexität | Prüffähigkeit |
|---|---|---|---|
| Spalte für aktuellen Zustand | Hoch | Niedrig | Niedrig |
| Ereignisprotokoll | Mittel (erfordert Wiedergabe) | Mittel | Hoch |
| Hybrid | Hoch | Mittel | Mittel |
Das Hybrid-Modell wird oft bevorzugt. Es speichert den aktuellen Zustand für schnellen Zugriff, während es ein Ereignisprotokoll für die Prüfung beibehält. Dadurch ist sichergestellt, dass das System weiß, wo es sich gerade befindet, aber auch, wie es dorthin gelangt ist.
Datenbankbeschränkungen und Integrität
Die Gewährleistung der Datenintegrität ist entscheidend. Die Datenbank sollte Regeln durchsetzen, die ungültige Zustandsübergänge verhindern. Während die Anwendungslogik der primäre Schutz ist, bieten Datenbankbeschränkungen eine Sicherheitsnetz.
- Prüfbedingungen: Definieren Sie gültige Werte für die Statusspalte.
- Fremdschlüssel: Verknüpfen Sie Statusprotokolle mit der Hauptentität, um die Referenzintegrität zu gewährleisten.
- Transaktionen: Umgeben Sie Statusaktualisierungen und zugehörige Datenänderungen in einer einzigen Transaktion, um die Atomarität zu gewährleisten.
API- und externe Logikintegration 🔗
Statusübergänge erfordern oft Aktionen. Wenn ein System von Ausstehendzu Verarbeitung, könnte es notwendig sein, eine Benachrichtigung zu senden, eine Zahlung zu verrechnen oder ein Bestandsverwaltungssystem zu aktualisieren. Diese Aktionen werden über APIs behandelt.
Auslösen externer Aufrufe
API-Aufrufe sollten basierend auf der Übergangslogik ausgelöst werden. Dies stellt sicher, dass Nebenwirkungen nur auftreten, wenn der Statuswechsel gültig ist.
- Vor-Übergangshooks: Überprüfen Sie externe Bedingungen, bevor der Statuswechsel zugelassen wird.
- Nach-Übergangshooks: Führen Sie Logik aus, nachdem der Status erfolgreich festgeschrieben wurde.
- ereignisgesteuerte Hooks: Hören Sie auf Statusänderungsereignisse und reagieren Sie asynchron.
Behandlung von API-Fehlern
Netzwerkaufrufe sind unzuverlässig. Wenn ein API-Aufruf während eines Statusübergangs fehlschlägt, muss das System entscheiden, wie weiter verfahren wird. Ein Zustand in einer mehrdeutigen Position kann zu Datenkorruption führen.
- Kompensierende Transaktionen: Wenn eine Aktion fehlschlägt, lösen Sie eine Rücksetzung oder einen spezifischen Zustand aus, um den Fehler zu markieren (z. B. Fehlgeschlagen oder Wiederholen).
- Wiederholungslogik: Implementieren Sie eine exponentielle Backoff-Strategie für vorübergehende Fehler.
- Idempotenz: Stellen Sie sicher, dass das erneute Ausführen eines API-Aufrufs keine doppelten Datensätze oder Gebühren erzeugt.
Anfrage-Muster
| Muster | Anwendungsfall | Komplexität |
|---|---|---|
| Synchron | Sofortige Rückmeldung erforderlich | Niedrig |
| Asynchron | Langlaufende Aufgaben | Mittel |
| Feuern und Vergessen | Benachrichtigungen | Niedrig |
Synchronen Aufrufe blockieren die Zustandsänderung, bis die API antwortet. Dies ist einfach, kann aber zu Zeitüberschreitungen führen. Asynchrone Aufrufe ermöglichen eine sofortige Zustandsaktualisierung, wobei ein Worker die externe Anfrage später verarbeitet. Dadurch wird die Zustandslogik von der Latenz der externen Abhängigkeit entkoppelt.
Konkurrenz und Rennbedingungen 🔄
Wenn mehrere Prozesse gleichzeitig versuchen, den Zustand derselben Entität zu ändern, können Rennbedingungen auftreten. Dies ist bei verteilten Systemen üblich, bei denen Anfragen über verschiedene API-Endpunkte eintreffen.
Optimistisches Sperren
Optimistisches Sperren geht davon aus, dass Konflikte selten sind. Es verwendet eine Versionsnummer oder einen Zeitstempel, um Änderungen zu erkennen.
- Logik: Lesen Sie die aktuelle Version. Aktualisieren Sie den Datensatz mit dem neuen Zustand und der erhöhten Version.
- Konflikt: Wenn die Aktualisierung keine Zeilen betrifft, hat ein anderer Prozess den Datensatz geändert. Die Transaktion wird rückgängig gemacht.
- Vorteil: Hoher Durchsatz für Systeme mit geringer Konkurrenz.
Pessimistisches Sperren
Pessimistisches Sperren geht davon aus, dass Konflikte wahrscheinlich sind. Es sperrt den Datensatz, bevor er gelesen wird.
- Logik: Erwerben Sie eine exklusive Sperrung für die Zeile. Führen Sie die Aktualisierung aus. Heben Sie die Sperrung auf.
- Konflikt: Andere Prozesse warten, bis die Sperrung freigegeben wird.
- Vorteil: Gewährleistet die Reihenfolge der Operationen.
- Risiko: Kann zu Verklemmungen führen, wenn sie nicht sorgfältig verwaltet werden.
Zustandsverwaltung basierend auf Warteschlangen
Um Konkurrenzprobleme vollständig zu vermeiden, leiten Sie alle Anfragen zur Zustandsänderung über eine einzige Warteschlange weiter.
- Implementierung: Alle API-Anfragen stellen ein Ereignis in eine Nachrichtenwarteschlange.
- Verarbeitung: Ein einzelner Worker verarbeitet Ereignisse sequenziell für eine bestimmte Entitäts-ID.
- Vorteil: Beseitigt Rennbedingungen durch die Architektur.
Fehlerbehandlung und Wiederherstellung 🛡️
Fehler sind unvermeidlich. Die Integrations-Schicht muss sie behandeln, ohne den Zustandsautomaten in einem beschädigten Zustand zu lassen.
Transaktionsgrenzen
Definieren Sie, wo die Transaktion beginnt und endet. Ein häufiger Fehler ist das Committen des Datenbankzustands, bevor der API-Aufruf erfolgreich war. Dadurch befindet sich das System in einem Zustand, in dem die Datenbank “Abgeschlossen” sagt, aber der externe Dienst die Anfrage nie erhalten hat.Abgeschlossen, aber der externe Dienst hat die Anfrage nie erhalten.
- Zwei-Phasen-Commit: Stellen Sie sicher, dass sowohl die Datenbank als auch der externe Dienst sich auf das Ergebnis einigen.
- Eventuelle Konsistenz: Akzeptieren Sie, dass die Konsistenz verzögert sein kann, aber stellen Sie sicher, dass ein Mechanismus zur Behebung vorhanden ist.
Dead Letter Warteschlangen
Wenn ein API-Aufruf wiederholt fehlschlägt, verschieben Sie das Ereignis in eine Dead Letter Warteschlange. Dadurch wird verhindert, dass das System endlos in einer Wiederholungsschleife verharrt.
- Benachrichtigung: Benachrichtigen Sie Ingenieure, wenn Elemente in die Dead Letter Warteschlange gelangen.
- Manuelle Intervention: Erlauben Sie Betreibern, fehlgeschlagene Ereignisse erneut zu versuchen oder zu löschen.
Testen und Validierung 🧪
Das Testen von Zustandsmaschinen ist komplex, da die Anzahl möglicher Pfade exponentiell wächst. Eine robuste Teststrategie deckt die Logik, die Integrationspunkte und die Fehlerfälle ab.
Einheitstests für Zustandslogik
Testen Sie die Zustandsmaschine unabhängig von der Datenbank und der API.
- Eingabe/Ausgabe:Geben Sie ein Ereignis ein und überprüfen Sie den resultierenden Zustand.
- Ungültige Übergänge:Stellen Sie sicher, dass ungültige Ereignisse abgelehnt werden.
- Codeabdeckung:Ziel ist eine Abdeckung von 100 % der Zustandsübergangsregeln.
Integrationstests
Testen Sie den Ablauf mit Datenbank- und API-Simulationen.
- Datenbank-Schema:Stellen Sie sicher, dass Zustandsaktualisierungen dem Schema entsprechen.
- API-Simulationen:Simulieren Sie API-Antworten (Erfolg, Fehler, Timeout), um die Fehlerbehandlung zu testen.
- Ende-zu-Ende:Führen Sie den gesamten Ablauf von Anfang bis Ende in einer Testumgebung aus.
Mutationstests
Brechen Sie absichtlich den Code ab, um zu sehen, ob die Tests den Fehler erkennen.
- Logikänderungen:Entfernen Sie einen Zustandsübergang und stellen Sie sicher, dass der Test fehlschlägt.
- Datenänderungen:Ändern Sie den Datenbankzustand und stellen Sie sicher, dass das System ihn ablehnt.
Skalierung und Leistung 🚀
Wenn das System wächst, muss die Zustandsmaschine eine höhere Last verarbeiten, ohne dass die Leistung abnimmt.
Zustand zwischenspeichern
Das Lesen des Zustands aus der Datenbank bei jeder Anfrage kann langsam sein. In-Memory-Caches können die Latenz reduzieren.
- Strategie:Speichern Sie den aktuellen Zustand für eine bestimmte Entitäts-ID im Cache.
- Invaliderung: Stellen Sie sicher, dass der Cache unmittelbar nach einer Zustandsänderung ungültig gemacht wird.
- Konsistenz: Akzeptieren Sie vorübergehende Inkonsistenzen, wenn die Cache-Trefferquote hoch ist.
Datenbank-Sharding
Wenn die Anzahl der Entitäten groß ist, teilen Sie die Datenbank basierend auf der Entitäts-ID auf mehrere Shards auf.
- Vorteil: Verteilt die Last auf mehrere Server.
- Herausforderung: Komplexe Abfragen, die mehrere Shards umfassen, werden schwierig.
Wartung und Versionierung 📝
Zustandsmaschinen entwickeln sich weiter. Neue Zustände werden hinzugefügt, und alte werden abgeschaltet. Die Verwaltung dieser Entwicklung ist für die langfristige Stabilität entscheidend.
Versionierung der Zustandslogik
Speichern Sie die Version der Zustandsmaschinenlogik zusammen mit den Zustandsdaten.
- Kompatibilität: Stellen Sie sicher, dass ältere Daten von neuen Versionen gelesen werden können.
- Migration: Schreiben Sie Skripte, um bestehende Datensätze auf das neue Schema zu aktualisieren.
Ablaufstrategie
Löschen Sie einen Zustand beim Entfernen nicht sofort.
- Als veraltet markieren: Fügen Sie einen Flag hinzu, um anzuzeigen, dass der Zustand veraltet ist.
- Übergänge blockieren: Verhindern Sie neue Übergänge in den veralteten Zustand.
- Aufräumen: Entfernen Sie die Zustandsdefinition erst, nachdem alle Daten migriert wurden.
Dokumentation
Führen Sie ein visuelles Diagramm auf, das dem Code entspricht. Dies hilft neuen Entwicklern, das System zu verstehen.
- Diagramm-Tools: Verwenden Sie Tools, die Diagramme aus Code oder Konfiguration generieren können.
- Änderungsprotokolle: Dokumentieren Sie jede Änderung am Zustandsdiagramm in der Versionsgeschichte.
Sicherheitsüberlegungen 🔐
Zustandsübergänge beinhalten oft sensible Daten. Die Sicherheit muss in die Integrations-Schicht eingebettet werden.
- Berechtigungen:Stellen Sie sicher, dass der Benutzer, der den Zustandswechsel anfordert, die Berechtigung für diesen spezifischen Übergang hat.
- Datenvalidierung:Bereinigen Sie alle Eingabedaten, bevor Sie den Zustandswechsel verarbeiten.
- Protokollierung:Protokollieren Sie Zustandsänderungen zur Sicherheitsprüfung, stellen Sie jedoch sicher, dass sensible Daten maskiert werden.
Zusammenfassung der Best Practices
- Speichern Sie den aktuellen Zustand in der Datenbank für schnellen Zugriff.
- Protokollieren Sie alle Ereignisse zur Nachvollziehbarkeit und Rekonstruktion.
- Verwenden Sie Transaktionen, um die Atomarität zwischen Zustandsaktualisierungen und API-Aufrufen sicherzustellen.
- Implementieren Sie Wiederholungslogik mit exponentiellem Backoff bei API-Fehlern.
- Verwenden Sie optimistisches Locking, um gleichzeitige Aktualisierungen effizient zu behandeln.
- Testen Sie alle Zustandsübergänge, einschließlich ungültiger.
- Versionieren Sie Ihre Zustandslogik, um die Entwicklung im Laufe der Zeit zu verwalten.
Durch die Einhaltung dieser Muster können Entwickler Zustandsmaschinen erstellen, die widerstandsfähig, skalierbar und wartbar sind. Die Integration zwischen Zustandslogik, Datenbanken und APIs ist die Grundlage zuverlässiger Geschäftsprozesse. Eine ordentliche Gestaltung auf dieser Ebene verhindert Datenkorruption und stellt sicher, dass das System unter Last vorhersehbar reagiert.