











In komplexen Systemen ist Effizienz nicht immer sichtbar, bis ein Verlangsamung eintritt. Wenn Prozesse stocken, Daten nachhinken oder die Durchsatzrate sinkt, liegt das zugrundeliegende Problem oft in der Bewegung von Informationen, nicht in der Speicherung oder Berechnung selbst. Die Datenflussanalyse bietet eine strukturierte Methode, um zu visualisieren, wie Informationen durch ein System fließen, wodurch es einfacher wird, die Stellen zu erkennen, an denen Reibung entsteht. Durch die Abbildung dieser Flüsse können Teams genaue Positionen identifizieren, an denen die Kapazität überschritten ist oder unnötige Verzögerungen sich ansammeln. 🧭
Dieser Ansatz erfordert ein klares Verständnis der Systemarchitektur, ohne auf proprietäre Werkzeuge angewiesen zu sein. Ziel ist es, ein logisches Framework aufzubauen, das Unzulänglichkeiten aufzeigt. Unabhängig davon, ob man eine Software-Pipeline, eine Fertigungsstraße oder einen administrativen Ablauf verwalten, bleiben die Prinzipien konsistent. Die Identifizierung dieser Einschränkungen ermöglicht gezielte Maßnahmen, die messbare Verbesserungen in Geschwindigkeit und Zuverlässigkeit bringen. ⚙️
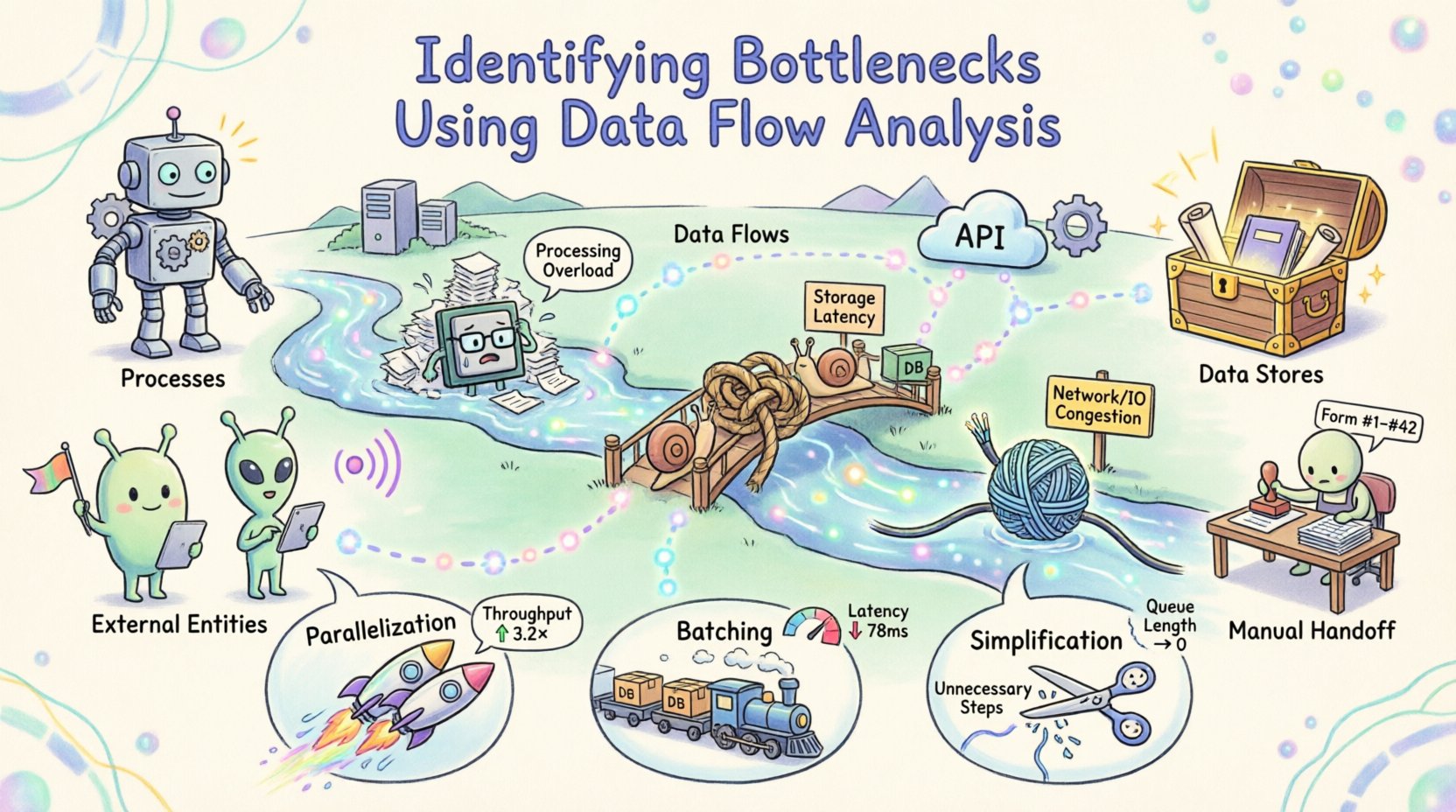
Verständnis der Grundlagen von Datenflussdiagrammen 🗺️
Bevor ein Engpass lokalisiert werden kann, muss man die Karte verstehen. Ein Datenflussdiagramm (DFD) ist eine grafische Darstellung des Datenflusses durch ein Informationssystem. Es konzentriert sich darauf, woher die Daten stammen, wohin sie gehen und wie sie sich verändern. Im Gegensatz zu Ablaufdiagrammen, die Steuerlogik darstellen, legen DFDs den Fokus auf die Bewegung und Transformation von Datenbestandteilen.
Es gibt vier primäre Komponenten in einem Standard-DFD:
- Prozesse:Transformationen, die Eingabedaten in Ausgabedaten umwandeln. Sie werden oft als Kreise oder abgerundete Rechtecke dargestellt.
- Datenbanken:Orte, an denen Daten für spätere Verwendung gespeichert werden, wie Datenbanken oder Dateien.
- Externe Entitäten:Quellen oder Ziele außerhalb der Systemgrenze, wie Benutzer oder andere Systeme.
- Datenflüsse:Die Wege, entlang derer Daten zwischen den Komponenten fließen.
Die Erstellung eines Diagramms auf hoher Ebene legt den Umfang fest. Ein Diagramm auf niedrigerer Ebene dringt dann in spezifische Prozesse ein. Diese Hierarchie ermöglicht es Analysten, das System auf verschiedenen Granularitätsstufen zu untersuchen. Wenn eine Verzögerung auf der Makroebene auftritt, zeigt das Vergrößern die spezifischen Prozesse oder Übertragungen, die die Verzögerung verursachen. 🔍
Die Anatomie eines Systemengpasses 🚦
Ein Engpass ist jeder Punkt in einem System, an dem der Datenfluss eingeschränkt ist, was zu einer Ansammlung oder Verzögerung führt. Im Kontext der Datenflussanalyse äußern sich Engpässe auf mehrere unterschiedliche Weisen. Die Erkennung der Art der Einschränkung ist der erste Schritt zur Lösung.
| Engpassart | Beschreibung | Typische Symptome |
|---|---|---|
| Verarbeitung | Berechnung oder Logik dauert länger als der eingehende Datenstrom unterstützen kann. | Warteschlangen bilden sich vor dem Prozess; hohe CPU- oder Speichernutzungsspitzen. |
| Speicher | Lesen oder Schreiben von Daten in eine Datenbank oder Dateisystem ist langsam. | Die Latenz steigt während der Datenabruf; Transaktionszeiten variieren stark. |
| Netzwerk/E/A | Die Übertragungsgeschwindigkeit zwischen Komponenten ist durch Bandbreite oder Latenz begrenzt. | Zeitüberschreitungen treten auf; große Datenübertragungen pausieren häufig. |
| Menschlich | Manuelle Eingriffe sind erforderlich, wo Automatisierung stattfinden sollte. | Aufgaben warten auf Genehmigung; Fehler treten aufgrund von Ermüdung oder Komplexität auf. |
Das Verständnis dieser Kategorien hilft bei der Priorisierung von Behebungen. Eine Netzwerkbeschränkung könnte Infrastrukturänderungen erfordern, während eine Verarbeitungsgrenze algorithmische Optimierung erfordern könnte. Ohne diese Unterscheidung könnten Bemühungen falsch gerichtet werden, in Bereichen, die das System nicht einschränken. 🛠️
Methodik zur Identifizierung 🔎
Die Identifizierung von Engpässen ist kein einmaliger Vorgang, sondern eine systematische Untersuchung. Die folgenden Schritte skizzieren einen robusten Ansatz zur Analyse von Datenflüssen und zur Lokalisierung von Beschränkungen.
1. Zustand der aktuellen Situation abbilden
Beginnen Sie damit, die bestehende Architektur zu dokumentieren. Verlassen Sie sich nicht auf Gedächtnis oder Annahmen. Befragen Sie Stakeholder und überprüfen Sie Dokumentationen, um den tatsächlichen Informationsfluss zu erfassen. Erstellen Sie ein Level-0-Diagramm, das die Systemgrenze und externe Interaktionen zeigt. Erstellen Sie anschließend Level-1-Diagramme, die die Hauptprozesse aufgliedern. Stellen Sie sicher, dass jeder Datenfluss eine definierte Eingabe und Ausgabe hat.
2. Metriken zur Messung definieren
Visuelle Karten sind qualitativ. Um Engpässe zu finden, benötigen Sie quantitative Daten. Wählen Sie Schlüsselkennzahlen (KPIs) für jeden Prozess und Datenfluss aus. Relevante Metriken umfassen:
- Durchsatz: Die Menge an Daten, die pro Zeiteinheit verarbeitet wird.
- Latenz: Die Zeit, die benötigt wird, damit Daten von der Quelle zur Zielstelle gelangen.
- Auslastung: Der Prozentsatz der Zeit, in der eine Ressource aktiv ist.
- Warteschlangenlänge: Die Anzahl der Elemente, die auf die Verarbeitung warten.
Die Sammlung dieser Daten über einen repräsentativen Zeitraum offenbart Muster. Ein Prozess könnte im Durchschnitt schnell erscheinen, zeigt aber während Spitzenlasten erhebliche Spitzen. Diese Spitzen sind oft der Ort, an dem der Engpass verborgen liegt. 📉
3. Datenübergänge analysieren
Untersuchen Sie die Verbindungen zwischen Prozessen. Suchen Sie nach Datenflüssen, die sich in mehrere Pfade verzweigen oder aus mehreren Quellen zusammenlaufen. Verzweigungsstellen erzeugen oft Konkurrenz. Wenn drei Datenströme in einen Prozessor fließen, muss dieser die kombinierte Last bewältigen. Wenn die Kapazität nicht entsprechend skaliert wird, entsteht ein Rückstand.
Überprüfen Sie ebenfalls auf Schleifen. Daten, die wiederholt durch einen Prozess zirkulieren, deuten auf Nacharbeit oder Fehlerbehandlung hin. Übermäßiges Schleifen verbraucht Ressourcen, ohne Wert hinzuzufügen. Verfolgen Sie diese Schleifen, um festzustellen, ob sie notwendig sind oder das Ergebnis einer schlechten Gestaltung sind. 🔄
4. Mit Ressourcennutzung korrelieren
Korrelieren Sie die Datenflussmetriken mit den Systemressourcen. Hohe Datenflussmengen sollten mit hoher Ressourcennutzung korrelieren. Wenn ein bestimmter Datenfluss hohe Latenz zeigt, aber ansonsten geringe Ressourcennutzung aufweist, könnte das Problem spezifisch für diesen Pfad sein. Umgekehrt könnte ein gleichzeitiges Verlangsamen aller Prozesse auf ein systemisches Problem hindeuten, wie beispielsweise eine gemeinsam genutzte Datenbank-Sperre oder Netzwerküberlastung.
Verwenden Sie Überwachungstools, um die Ressourcenverbrauchskurve parallel zum Datenfluss zu verfolgen. Diese Korrelation hilft, zwischen einem logischen Engpass (schlechte Gestaltung) und einem physischen Engpass (Hardware-Grenzen) zu unterscheiden. ⚖️
Quantifizierung der Auswirkungen von Beschränkungen 📊
Sobald ein potenzieller Engpass identifiziert ist, muss seine Auswirkung quantifiziert werden. Dieser Schritt stellt sicher, dass Ressourcen auf die kritischsten Probleme verteilt werden. Nicht alle Verzögerungen sind gleich. Eine Verzögerung in der Benutzeroberfläche könnte schädlicher sein als eine Verzögerung bei der Hintergrundgenerierung eines Berichts.
Berechnen Sie die Kosten der Verzögerung. Dazu schätzen Sie die pro Transaktion verlorene Zeit ab und multiplizieren sie mit der Transaktionsanzahl. Wenn beispielsweise ein Prozess zusätzliche 100 Millisekunden benötigt und 10.000 Transaktionen pro Stunde verarbeitet, ist die insgesamt verlorene Zeit erheblich. Wenn diese Verzögerung die Benutzererfahrung beeinträchtigt, steigen die geschäftlichen Kosten noch weiter.
Berücksichtigen Sie die Kettenreaktion. Eine Verzögerung am Anfang einer Pipeline kann sich nachfolgend ausbreiten. Wenn der erste Schritt verzögert wird, werden alle nachfolgenden Schritte nach hinten verschoben. Dies verstärkt die Gesamtauswirkung. Die Identifizierung der Ursache verhindert das Behandeln von Symptomen. Die Behebung des ersten Schritts löst oft die nachfolgenden Verzögerungen automatisch. 🌊
Strategien zur Optimierung 🛠️
Sobald die Engpässe identifiziert und quantifiziert wurden, rückt die Optimierung in den Fokus. Die Strategie hängt von der Art der Beschränkung ab. Es gibt drei Haupthebel: Parallelisierung, Batching und Vereinfachung.
Parallelisierung
Wenn ein Prozess durch Berechnungsgrenzen eingeschränkt ist, kann die Arbeit auf mehrere Ressourcen aufgeteilt werden, um die Durchsatzleistung zu erhöhen. Dies ist oft bei unabhängigen Aufgaben anwendbar. Wenn der Datenfluss eine Aufteilung zulässt, verteilen Sie die Last. Stellen Sie sicher, dass die Synchronisierungsüberhead die Gewinne nicht aufhebt. Die Parallelisierung funktioniert am besten, wenn Aufgaben nicht auf das unmittelbare Ergebnis der anderen warten müssen. 🚀
Batching
Wenn die Beschränkung mit I/O- oder Netzwerklatenz zusammenhängt, kann die Verarbeitung von Daten in Batches effizienter sein als die Verarbeitung einzelner Elemente. Dies reduziert den Overhead beim Öffnen und Schließen von Verbindungen. Allerdings führt das Batching zu einer Latenz für einzelne Elemente. Abwägen des Durchsatzgewinns gegen die akzeptable Verzögerung für den Endbenutzer. 📦
Vereinfachung
Oft ist die effektivste Optimierung die Entfernung unnötiger Schritte. Prüfen Sie den Datenfluss auf überflüssige Transformationen. Wenn Daten von einem Format in ein anderes konvertiert und dann wieder zurück konvertiert werden, kann der Zwischenschritt entfernt werden. Vereinfachen Sie die Logik, um die Verarbeitungszeit zu reduzieren. Jeder Schritt, der zu einem Fluss hinzugefügt wird, bringt potenzielle Ausfallpunkte und Verzögerungen mit sich. ✂️
Kontinuierliche Überwachung und Iteration 🔄
Optimierung ist kein Endziel. Systeme entwickeln sich weiter, und neue Engpässe entstehen, wenn sich Verkehrsstrukturen ändern. Sobald die erste Analyse abgeschlossen ist und Verbesserungen umgesetzt wurden, beginnt der Zyklus erneut. Legen Sie eine Routine für die Überprüfung der Datenflüsse fest.
Richten Sie Warnmeldungen für die zuvor definierten Metriken ein. Wenn die Durchsatzleistung sinkt oder die Latenz stark ansteigt, lösen Sie eine Untersuchung aus. Pflegen Sie die Dokumentation der DFDs. Aktualisieren Sie die Diagramme, sobald Änderungen am System vorgenommen werden. Veraltete Karten führen zu falschen Annahmen und verschwendeter Arbeit. 📝
Fördern Sie eine Kultur der kontinuierlichen Verbesserung. Teams sollten befähigt werden, ineffiziente Prozesse zu melden, die sie im täglichen Einsatz beobachten. Frontline-User erkennen oft Engpässe, die hochrangige Metriken übersehen. Ihr Feedback ist unverzichtbar, um die Analyse zu verfeinern. 👥
Fallstudie: Optimierung eines generischen Workflows 🏭
Betrachten Sie eine Situation, in der ein Bestellverarbeitungssystem während der Spitzenzeiten Verzögerungen aufwies. Die erste Analyse zeigte, dass der Schritt der Bestellüberprüfung zu lange dauerte. Das DFD ergab, dass die Überprüfung drei separate Prüfungen an unterschiedlichen externen Systemen erforderte.
Durch die Analyse des Flusses erkannte das Team, dass diese Prüfungen nacheinander erfolgten. Durch Änderung des Designs, um die Prüfungen parallel durchzuführen, wurde die Gesamtüberprüfungszeit um 60 % reduziert. Das Datenflussdiagramm wurde aktualisiert, um diese neue Struktur widerzuspiegeln. Die Überwachung bestätigte, dass die Warteschlange schneller abgearbeitet wurde und das System Spitzenlasten ohne Eingriff bewältigen konnte. Dieses Beispiel zeigt, wie strukturelle Änderungen am Fluss sofortige Ergebnisse liefern. ✅
Best Practices für nachhaltige Effizienz 🌱
Um ein gesundes System zu erhalten, halten Sie sich an diese Richtlinien:
- Halten Sie Diagramme aktuell: Eine veraltete Karte ist schlimmer als keine Karte.
- Konzentrieren Sie sich auf den Fluss, nicht nur auf die Funktion: Stellen Sie sicher, dass Daten reibungslos fließen, nicht nur, dass Funktionen funktionieren.
- Messen Sie alles: Wenn es nicht gemessen wird, kann es nicht verbessert werden.
- Überprüfen Sie regelmäßig: Planen Sie regelmäßige Audits der Datenarchitektur.
- Dokumentieren Sie Annahmen: Notieren Sie, warum bestimmte Flüsse auf eine bestimmte Weise gestaltet wurden, um zukünftige Fehlerbehebungen zu erleichtern.
Indem man den Datenfluss als kritischen Vermögenswert behandelt, können Organisationen sicherstellen, dass ihre Systeme reaktionsschnell und zuverlässig bleiben. Die Identifizierung von Engpässen geht nicht darum, Fehler zu finden, sondern darum, das System tiefgreifend zu verstehen. Diese Erkenntnis führt zu Widerstandsfähigkeit und Leistungsfähigkeit. 🛡️
Abschließende Gedanken zur Integrität des Datenflusses 🧩
Die Effizienz jedes Systems beruht auf der reibungslosen Bewegung von Informationen. Wenn Daten Widerstand erfahren, verlangsamt sich die gesamte Operation. Die Analyse des Datenflusses bietet ein klares Fenster, um zu erkennen, wo dieser Widerstand entsteht. Durch Kartierung, Messung und Anpassung des Flusses können Teams Reibung beseitigen und die Leistung steigern.
Die hier beschriebenen Techniken bieten einen Rahmen für eine nachhaltige Optimierung. Sie erfordern Disziplin und Sorgfalt, aber die Ergebnisse sind ein System, das unter Druck konstant leistungsfähig bleibt. Mit wachsenden Datenmengen wird die Fähigkeit, den Fluss zu managen, zunehmend entscheidend. Die Beherrschung dieser Disziplin sichert Langlebigkeit und Zuverlässigkeit der Architektur. 🏆