











In modernen verteilten Systemen hängt die Zuverlässigkeit eines Backend-Dienstes oft davon ab, wie gut er gleichzeitige Anfragen und gemeinsam genutzte Ressourcen verarbeitet. Eine der anhaltendsten und schwer reproduzierbaren Probleme in diesem Bereich ist der Deadlock. Ein Deadlock tritt auf, wenn zwei oder mehr Prozesse nicht weitermachen können, weil jeder auf die Freigabe einer Ressource durch den anderen wartet. Dieser Zustand dauerhafter Blockierung kann ein gesamtes System zum Stillstand bringen und zu Dateninkonsistenzen, Dienstunverfügbarkeit und Benutzerfrustration führen. Um diese Risiken zu minimieren, müssen Architekten und Ingenieure über einfache Code-Reviews hinausgehen und einen visuellen Ansatz für die Systemgestaltung anwenden. Kommunikationsdiagramme bieten eine strukturierte Möglichkeit, Interaktionen abzubilden, potenzielle Konfliktpunkte zu identifizieren und Resilienz-Muster zu implementieren, noch bevor Code geschrieben wird.
Diese Anleitung untersucht die Mechanismen von Deadlocks in Backend-Umgebungen und zeigt auf, wie Kommunikationsdiagramme als präventives Werkzeug eingesetzt werden können. Durch die Visualisierung des Steuerungsflusses und der Ressourcenbeschaffung können Teams zirkuläre Abhängigkeiten erkennen und Strategien zur Aufhebung dieser Abhängigkeiten entwickeln. Wir behandeln die theoretischen Grundlagen, praktische Visualisierungstechniken sowie spezifische architektonische Muster, die zur Resilienz eines Systems beitragen.
Verständnis der Mechanismen eines Deadlocks 🛑
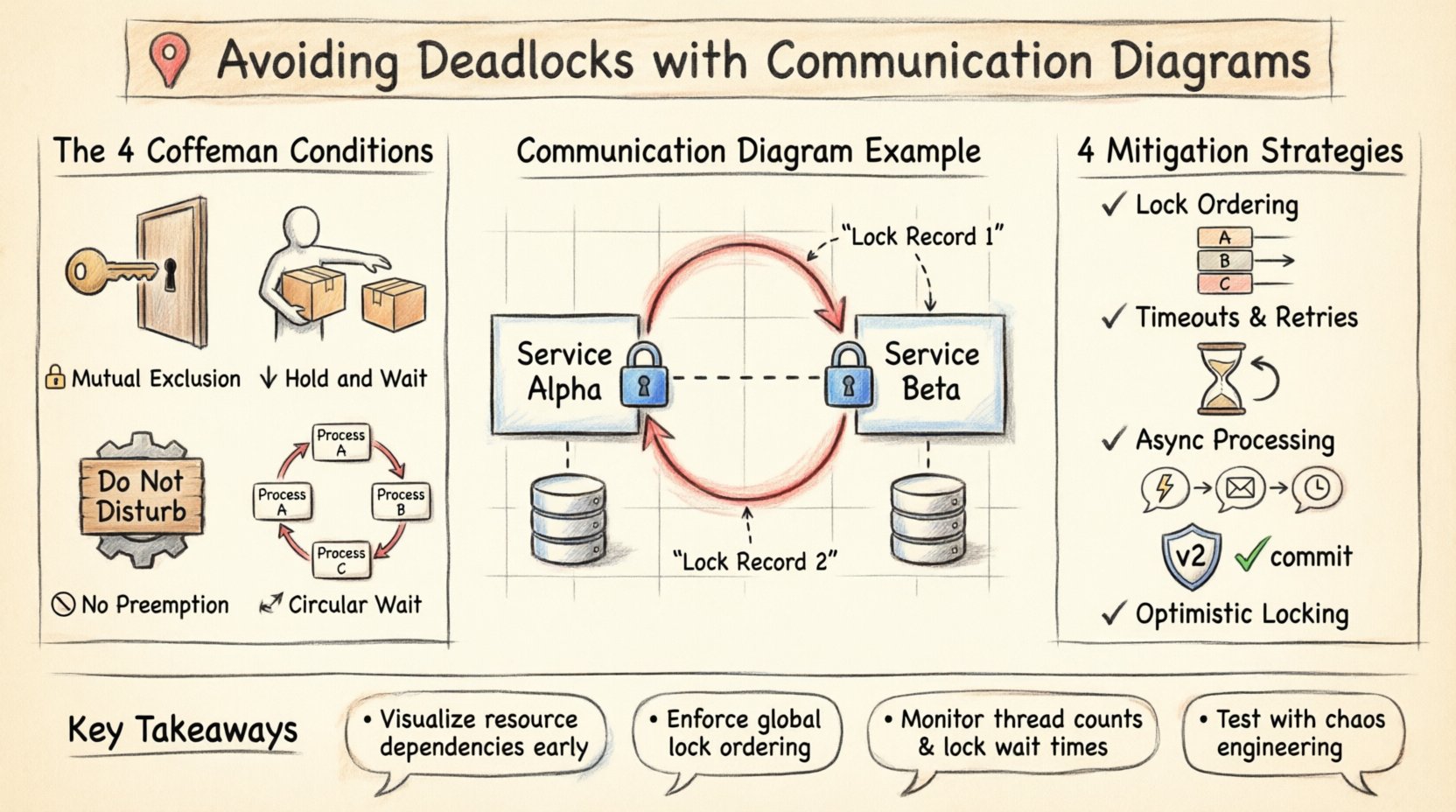
Bevor Prävention behandelt wird, ist es notwendig, die Bedingungen zu verstehen, die einen Deadlock verursachen. In der Informatik ist ein Deadlock kein zufälliges Ereignis; er ist das Ergebnis einer bestimmten Kombination von Bedingungen, die gleichzeitig auftreten. Diese werden oft als Coffman-Bedingungen bezeichnet. Für das Vorliegen eines Deadlocks müssen alle vier folgenden Bedingungen erfüllt sein:
- Wechselseitiger Ausschluss:Mindestens eine Ressource muss in einem nicht teilbaren Modus gehalten werden. Nur ein Prozess kann die Ressource zu einem bestimmten Zeitpunkt nutzen.
- Halten und Warten:Ein Prozess muss mindestens eine Ressource halten, während er auf die Beschaffung zusätzlicher Ressourcen wartet, die von anderen Prozessen gehalten werden.
- Keine Zwangsentziehung:Ressourcen können nicht zwangsweise einem Prozess entzogen werden. Sie müssen freiwillig von dem Prozess freigegeben werden, der sie hält.
- Zirkulärer Warten:Es existiert eine Menge von Prozessen, sodass P1 auf P2 wartet, P2 auf P3 wartet und so weiter, bis Pn auf P1 wartet.
In einer einthreadigen Anwendung ist ein Deadlock selten. In Backend-Systemen, die Tausende gleichzeitiger Anfragen verarbeiten, sind diese Bedingungen jedoch leicht erfüllbar. Zum Beispiel entsteht ein zirkuläres Warten, wenn Service A eine Sperrung für Ressource X hält und auf Ressource Y wartet, während Service B Ressource Y hält und auf Ressource X wartet. Ohne Zwangsentziehung oder sorgfältige Reihenfolge friert das System ein.
Die Rolle von Kommunikationsdiagrammen 📊
Kommunikationsdiagramme sind eine Art von Unified Modeling Language (UML)-Diagramm. Während Sequenzdiagramme den zeitlichen Ablauf von Nachrichten betonen, legen Kommunikationsdiagramme den Fokus auf die strukturelle Organisation von Objekten und die Verbindungen zwischen ihnen. Im Kontext der Backend-Resilienz ist diese strukturelle Sichtweise entscheidend. Sie ermöglicht es Designern zu erkennen,werspricht mitwemundwelchewelche Ressourcen ausgetauscht werden, anstatt nur die Reihenfolge, in der Nachrichten eintreffen.
Beim Entwurf einer Microservice-Architektur oder eines komplexen monolithischen Backends helfen Kommunikationsdiagramme, entscheidende Fragen zu beantworten:
- Welche Dienste benötigen exklusiven Zugriff auf dieselbe Datenbanktabelle?
- Gibt es bidirektionale Abhängigkeiten zwischen zwei Verarbeitungseinheiten?
- Läuft eine Anfragekette vor Abschluss zurück zum Ursprung?
- Wie tief ist die maximale Verschachtelung von Ressourcensperrungen?
Durch die Abbildung dieser Interaktionen bereits in der Entwurfsphase können Teams potenzielle Deadlock-Szenarien identifizieren, die bei einer rein codezentrierten Überprüfung unsichtbar bleiben könnten. Das Diagramm fungiert als Vertrag für die Interaktion und macht implizite Annahmen explizit.
Abbildung von Ressourcenabhängigkeiten 🗺️
Um Kommunikationsdiagramme effektiv zur Vermeidung von Deadlocks einzusetzen, muss das Diagramm Ressourcen darstellen, nicht nur den Datenfluss. Standardinteraktionsdiagramme zeigen oft Dienst-zu-Dienst-Aufrufe. Um Sperrungen zu analysieren, müssen wir die Verbindungen jedoch mit Ressourcenkennungen versehen. Dies erfordert eine etwas höhere Abstraktionsebene, bei der Knoten Prozesse oder Threads darstellen und Verbindungen gemeinsam genutzte Ressourcen oder Kommunikationskanäle darstellen.
Schritte zum Erstellen eines Deadlock-bewussten Diagramms
- Kritische Ressourcen identifizieren:Listen Sie alle gemeinsam genutzten Zustände auf, wie Datenbankzeilen, Dateihandler oder Speicherpuffer. Weisen Sie ihnen eindeutige Bezeichnungen zu.
- Eigentum definieren:Bestimmen Sie, welcher Dienst oder Thread derzeit welche Ressource steuert. Markieren Sie dies im Diagramm.
- Akkquisitionspfade verfolgen:Zeichnen Sie Pfeile, die die Anforderung einer Ressource anzeigen. Beschriften Sie den Pfeil mit dem Ressourcennamen.
- Wartezustände hervorheben:Verwenden Sie eine spezifische Notation, um anzuzeigen, wann ein Prozess blockiert ist und auf eine Ressource wartet.
- Zyklen analysieren:Suchen Sie nach geschlossenen Schleifen im Diagramm, bei denen Prozess A auf Prozess B wartet, der wiederum auf Prozess A wartet.
Erkennen von zirkulären Wartepatterns 🔁
Das gefährlichste Muster in der Systemgestaltung ist die zirkuläre Abhängigkeit. In einem Kommunikationsdiagramm erscheint dies als geschlossene Schleife von Interaktionen. Betrachten Sie eine Situation mit zwei Diensten, Service Alpha und Service Beta.
- Service Alpha startet eine Transaktion und sperrt Datensatz 1.
- Service Alpha bittet Service Beta um eine Sperrung von Datensatz 2.
- Service Beta hält bereits eine Sperrung von Datensatz 2, benötigt aber eine Aktualisierung von Datensatz 1, die von Alpha gehalten wird.
In einer visuellen Darstellung ist diese Schleife sofort erkennbar. Das Diagramm zeigt, dass Alpha auf Beta zeigt und Beta zurück auf Alpha, beide verlangen die Ressource, die der andere hält. Ohne ein Diagramm könnte diese Logik erst während eines Produktionsausfalls oder eines komplexen Lasttests entdeckt werden.
Häufige Szenarien, die zu Zirkularität führen
- Transaktionsweiterleitung:Wenn eine verteilte Transaktion erfordert, dass mehrere Dienste in einer bestimmten Reihenfolge committet werden, die Reihenfolge aber nicht durchgesetzt wird.
- Verschachtelte Aufrufe:Eine Funktion ruft eine andere Funktion auf, die schließlich die ursprüngliche Funktion aufruft, wodurch eine rekursive Sperrkette entsteht.
- Geteilter Cache:Mehrere Dienste versuchen gleichzeitig, denselben gecachten Eintrag zu aktualisieren, ohne dass ein Mechanismus für verteilte Sperrung vorhanden ist.
- Datenbank-Fremdschlüssel:Aktualisierungen in verwandten Tabellen, die Sperrungen in beiden Tabellen erfordern, wobei die Reihenfolge der Aktualisierungen zwischen den Diensten unterschiedlich ist.
Strategische Minderungsmaßnahmen 🛠️
Sobald ein Kommunikationsdiagramm ein potenzielles Deadlock aufzeigt, sind spezifische architektonische Änderungen erforderlich. Es gibt keine einzige Lösung, die für jedes System geeignet ist, aber mehrere bewährte Strategien existieren, um die Coffman-Bedingungen zu brechen.
1. Sperrreihenfolge
Dies ist die effektivste Methode, um zirkuläres Warten zu verhindern. Das System muss eine globale Reihenfolge der Ressourcen durchsetzen. Wenn jeder Prozess Ressourcen in derselben Reihenfolge anfordert (z. B. Ressource A vor Ressource B), kann kein Zyklus entstehen. In einem Kommunikationsdiagramm bedeutet dies, sicherzustellen, dass alle Verbindungen, die Ressource X anfordern, hergestellt sind, bevor irgendeine Verbindung Ressource Y anfordert.
2. Zeitüberschreitungen und Wiederholungen
Selbst bei einer Ordnung kann es zu Konkurrenz kommen. Die Implementierung einer Zeitüberschreitung bei der Ressourcenzuweisung stellt sicher, dass ein Prozess nicht unbegrenzt wartet. Wenn eine Sperre innerhalb einer festgelegten Dauer nicht erlangt werden kann, gibt der Prozess seine aktuellen Ressourcen frei und versucht es erneut. Dadurch wird verhindert, dass das System dauerhaft blockiert wird, obwohl dadurch möglicherweise eine Verzögerung entsteht.
3. Asynchrone Verarbeitung
Der Wechsel von synchronen Anfragen zu asynchronen ereignisgesteuerten Architekturen kann die Konkurrenz reduzieren. Anstatt auf die Freigabe einer Sperre zu warten, veröffentlicht ein Dienst ein Ereignis und setzt die Verarbeitung fort. Wenn die Ressource verfügbar ist, verarbeitet ein Verbraucher die Aktualisierung. Dadurch wird die zeitliche Abhängigkeit der Ressourcennutzung aufgelöst.
4. Optimistische Sperren
Anstatt eine Sperre vor dem Lesen oder Ändern von Daten zu erlangen, prüft das System zur Commit-Zeit auf Konflikte. Wenn ein anderer Prozess die Daten seit dem Lesen verändert hat, scheitert die Transaktion und muss erneut versucht werden. Dadurch wird die Haltezeit von Sperren reduziert und das Zeitfenster für Deadlocks minimiert.
Vergleich von Verhinderungsstrategien
| Strategie | Verhindert Bedingung | Komplexität | Leistungseinfluss |
|---|---|---|---|
| Sperrenreihenfolge | Zirkulärer Warten | Hoch | Niedrig |
| Zeitüberschreitungen | Halten und Warten (indirekt) | Niedrig | Mittel (Wiederholungen) |
| Optimistische Sperren | Wechselseitige Ausschließung (langfristig) | Mittel | Variabel |
| Asynchrone Ablauf | Halten und Warten | Hoch | Niedrig |
Implementierungsschritte für die diagrammbasierte Analyse
Um diesen Ansatz in Ihren Entwicklungsablauf zu integrieren, befolgen Sie diese Schritte:
- Durchführen einer Design-Überprüfung: Bevor Sie Code schreiben, erstellen Sie das Kommunikationsdiagramm für neue Funktionen. Konzentrieren Sie sich auf die Datenzugriffswege.
- Ressourcennutzung kennzeichnen: Kennzeichnen Sie auf dem Diagramm jede Datenbank-Write-Operation, Cache-Update-Operation oder Dateioperation.
- Ein Zyklenerkennungsalgorithmus ausführen: Wenn automatisierte Werkzeuge verwendet werden, wenden Sie Graphalgorithmen an, um Zyklen im Abhängigkeitsgraphen zu erkennen, der aus dem Diagramm abgeleitet wurde.
- Umstrukturieren zur Unabhängigkeit: Wenn ein Zyklus gefunden wird, umstrukturieren Sie den Code, um die Abhängigkeit zu brechen. Dazu könnte die Einführung eines Vermittlerdienstes oder eine Änderung des Datenmodells gehören.
- Validierung durch Lasttests: Simulieren Sie hohe Konkurrenz, um sicherzustellen, dass sich Deadlock-Muster unter Belastung nicht zeigen.
Überwachung und Beobachtbarkeit 🧪
Selbst bei sorgfältiger Gestaltung können Laufzeitbedingungen sich ändern. Überwachungstools sollten so konfiguriert werden, dass sie Anzeichen für Deadlocks erkennen. Zu den wichtigsten Metriken gehören:
- Anzahl der Threads:Ein plötzlicher Anstieg blockierter Threads kann auf Ressourcenkonkurrenz hindeuten.
- Wartezeit für Sperren: Wenn die durchschnittliche Zeit zum Erhalten einer Sperrung erheblich ansteigt, nimmt die Konkurrenz zu.
- Transaktionsrückgänge: Eine hohe Rate an Rückgängigmachungen aufgrund von Timeout oder Konflikt deutet darauf hin, dass die Sperrstrategien zu aggressiv sind.
- Logs zur Deadlock-Erkennung: Einige Datenbank-Engines und Betriebssysteme protokollieren Deadlock-Ereignisse. Diese Logs sollten in das zentrale Protokollsystem integriert werden.
Fallstudie: Ablauf der Dienstinteraktion
Betrachten Sie eine generische E-Commerce-Backend-System, das Bestellungen und Lagerbestände verwaltet. Dienst A verwaltet Bestellungen, und Dienst B verwaltet Lagerbestände.
Szenario:Dienst A erstellt eine Bestellung und sperrt die Bestell-ID. Anschließend ruft er Dienst B auf, um Lagerbestände zu reservieren. Dienst B sperrt die Lagerbestands-ID. Um den Bestellstatus zu aktualisieren, muss Dienst B eine Rückrufanforderung an Dienst A senden, was erneut die Sperrung der Bestell-ID erfordert.
Der Deadlock: Wenn Dienst A die Bestell-ID hält und auf Dienst B wartet, um die Lagerbestands-ID freizugeben, aber Dienst B nicht abschließen kann, ohne dass Dienst A die Bestell-ID freigibt (über den Rückruf), tritt ein Deadlock auf. Dies ist ein Szenario mit verschachtelten Sperren.
Die Lösung: Mit einem Kommunikationsdiagramm ist diese Schleife sichtbar. Die Lösung besteht darin, die Abhängigkeit zu brechen. Dienst B sollte den Lagerbestand asynchron aktualisieren oder eine separate Transaktions-ID verwenden, die keine erneute Sperrung der von Dienst A gehaltenen Bestell-ID erfordert. Das Diagramm würde dann einen einseitigen Fluss von A nach B zeigen, ohne Rückweg, der die ursprüngliche Sperrung erfordert.
Überlegungen zur verteilten Sperre
In verteilten Umgebungen werden Sperren oft von externen Diensten verwaltet, anstatt vom Anwendungscode selbst. Dies führt zu Netzwerkverzögerungen und dem Risiko partieller Ausfälle. Kommunikationsdiagramme müssen den Netzwerklink als potenziellen Ausfallpunkt berücksichtigen. Wenn die Verbindung zwischen Dienst A und dem Sperr-Manager ausfällt, könnte Dienst A glauben, die Sperrung zu halten, während ein anderer Dienst sie tatsächlich hält.
Um dies zu beheben, sollte das Diagramm einen „Sperr-Manager“-Knoten enthalten. Die Interaktionen mit diesem Knoten müssen idempotent und zeitlich begrenzt sein. Das Design muss sicherstellen, dass bei einem Absturz eines Dienstes die Sperrung automatisch freigegeben wird, wenn die Leasenzeit abgelaufen ist. Dadurch wird verhindert, dass der Zustand „Halten und Warten“ unbegrenzt andauert.
Testen auf Resilienz
Designdiagramme sind theoretisch. Im echten Einsatz müssen Tests durchgeführt werden, um die Resilienz zu überprüfen. Dazu gehören:
- Chaos Engineering: Absichtlich Verzögerungen oder Ausfälle in den im Diagramm dargestellten Netzwerkverbindungen einfügen, um zu prüfen, ob das System sich erholt oder sich verhängt.
- Stresstests: Gleichzeitige Anfragen ausführen, die den im Diagramm identifizierten Mustern entsprechen, um zu überprüfen, ob die Sperrreihenfolge unter Last funktioniert.
- Statische Analyse: Werkzeuge verwenden, um den Codebestand auf mögliche Verstöße gegen die Sperrreihenfolge zu prüfen, die mit der Diagrammlogik übereinstimmen.
Fazit
Das Vermeiden von Deadlocks ist keine bloße Programmieraufgabe; es ist eine Herausforderung der Systemarchitektur. Durch die Nutzung von Kommunikationsdiagrammen können Teams das komplexe Geflecht von Ressourcenabhängigkeiten visualisieren, die zu Systemeinfrierungen führen. Dieser Ansatz verlagert den Fokus von reaktiver Fehlersuche hin zu proaktiver Verhinderung. Das Verständnis der vier Bedingungen für ein Deadlock, die Abbildung der Ressourcenbeschaffungspfade sowie die Durchsetzung strenger Reihenfolgen oder asynchroner Muster sind entscheidende Schritte beim Aufbau einer resistenten Backend-Infrastruktur. Obwohl kein System vor Konkurrenzproblemen gefeit ist, reduziert ein strukturierter visueller Ansatz das Risiko und die Komplexität bei der Verwaltung gemeinsam genutzter Ressourcen erheblich. Die konsequente Anwendung dieser Prinzipien stellt sicher, dass Dienste auch unter hoher Last und bei Ausfällen reaktionsschnell bleiben und die Daten konsistent bleiben.