











分布式系统严重依赖于孤立组件之间的信息流动。在构建微服务时,架构不仅仅是代码的分离;更在于协调数据在网络中的传输方式。理解数据流逻辑对于保持系统的完整性、性能和可靠性至关重要。如果没有清晰的地图来标明数据的来源、转换位置以及最终的归宿,系统就会变得不透明,难以排查问题。
本指南探讨了映射这些数据流的方法。我们将分析结构组件、数据移动背后的逻辑,以及服务间通信所遵循的模式。目标是构建一个透明的架构,确保每一笔事务都可追溯。
理解架构 🏗️
微服务架构将单体应用分解为更小、独立的单元。每个单元负责特定的业务能力。然而,这种独立性也带来了状态管理和通信方面的复杂性。数据并非孤立存在;它始终在流动。
当你映射这些服务时,实际上是在绘制系统神经系统的蓝图。你需要识别数据的生产者和消费者。必须理解数据传输所使用的协议。服务之间是通过HTTP直接通信吗?是否使用了消息队列?是否访问了共享数据库?
在此领域保持清晰可以避免耦合。如果服务A依赖服务B才能运行,这种依赖关系必须在你的地图中明确体现。隐藏的依赖会导致级联故障。通过可视化数据流,你可以在其影响生产性能之前识别出瓶颈。
映射的关键驱动力
- 可观测性:你无法调试看不见的东西。清晰的地图有助于在分布式环境中追踪请求。
- 安全性:理解数据流有助于在正确的边界上应用加密和访问控制。
- 性能:识别高延迟路径有助于优化网络调用和数据库查询。
- 合规性:法规通常要求明确敏感数据的存放位置及其流动方式。
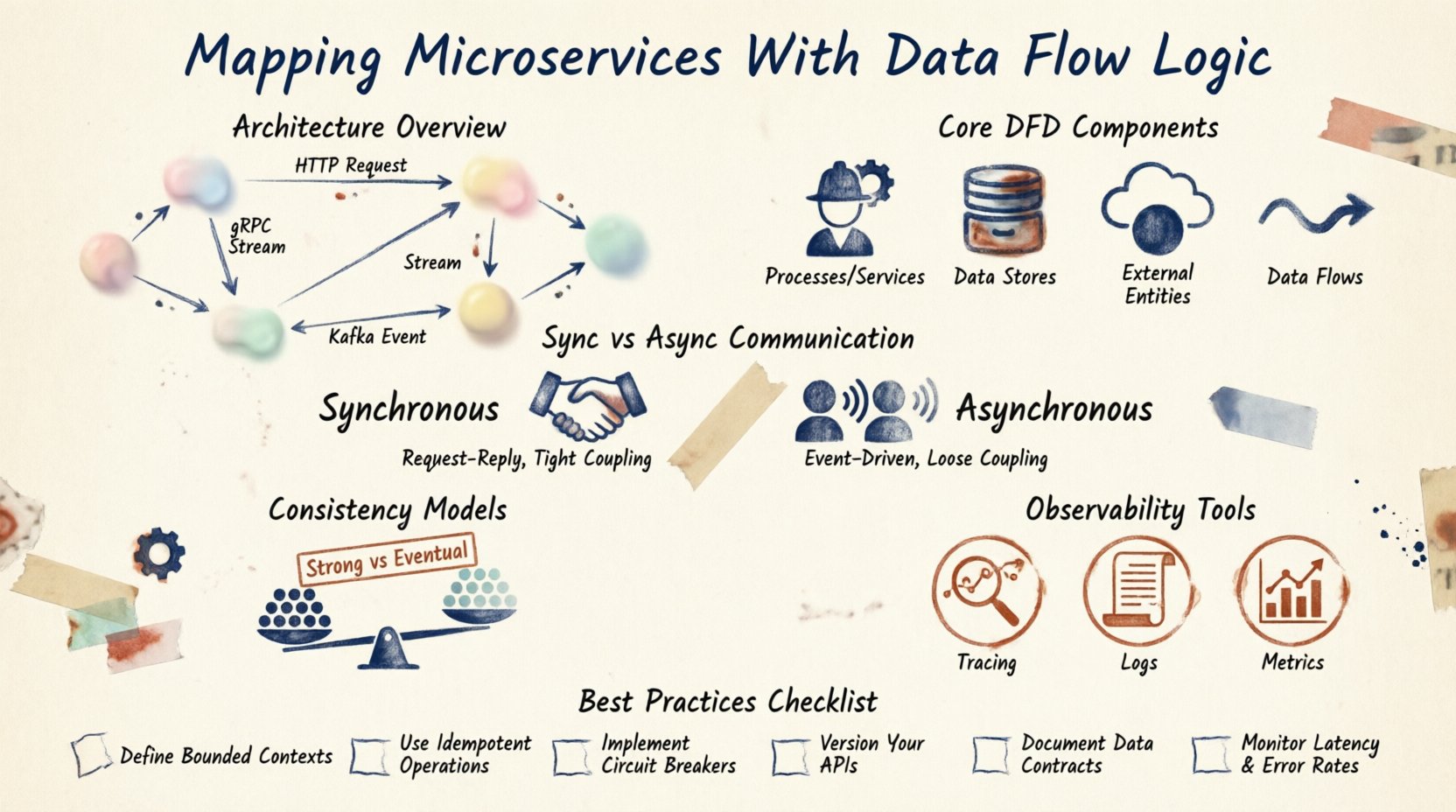
数据流图的核心组件 📊
数据流图(DFD)提供了一种标准化的方式来表示这些交互。在微服务的背景下,其组件与传统软件工程中的DFD略有不同。
1. 处理过程(服务)
这些是活跃的元素。每个微服务代表一个将输入数据转换为输出数据的过程。例如,订单服务接收订单详情,并将其转换为库存预留。
2. 数据存储
数据并不总是在内存中停留。它通常持久化在数据库、缓存或对象存储中。在微服务环境中,服务通常拥有私有的数据存储。这确保了松耦合。如果数据库模式发生变化,只有拥有该数据的服务才需要调整。
3. 外部实体
这些是系统外部的参与者。它们可能是第三方支付网关、移动应用程序或用户。它们发起请求或接收通知。映射这些边界对于API网关设计至关重要。
4. 数据流
这些是连接各组件的箭头。它们代表信息的流动。每个数据流都应有标签,说明传输的数据内容。是JSON负载?是二进制文件?还是事件通知?
分步映射流程 🗺️
绘制地图是一项系统性的工作。它需要逐层分解系统。以下是构建这些图表的一种逻辑方法。
- 确定边界: 明确系统内部和外部的内容。这设定了你图表的范围。
- 列出服务: 列出与你正在分析的特定业务流程相关的每一个微服务。
- 定义数据入口点: 数据进入系统的位置在哪里?是 API 端点吗?一个定时任务吗?还是消息队列的消费者?
- 追踪数据路径: 跟踪单条数据从进入系统到离开系统的全过程。记录它经过的每一个服务。
- 识别存储位置: 在每一步中标记数据被读取或写入的位置。
- 验证逻辑: 与开发团队一起审查这张图,确保它与实际实现一致。
通信模式 📡
服务之间的通信方式决定了流程逻辑。主要有两种模式:同步和异步。
同步通信
服务 A 调用服务 B 并等待响应。这通常通过 REST 或 gRPC 实现。它能提供即时反馈,但会造成紧密耦合。如果服务 B 响应缓慢,服务 A 就会阻塞。
异步通信
服务 A 发送一条消息后继续工作。服务 B 在准备好时再获取该消息。这使用消息代理或事件流。它提高了系统的容错性,但使状态追踪变得更困难。
| 方面 | 同步 | 异步 |
|---|---|---|
| 延迟 | 较高(阻塞) | 较低(非阻塞) |
| 耦合度 | 紧密 | 松散 |
| 复杂性 | 易于追踪 | 需要事件溯源 |
| 故障处理 | 立即重试 | 死信队列 |
一致性模型 🤝
在分布式系统中,数据一致性是一个主要问题。你不能依赖跨多个数据库的单一事务。你必须选择一种一致性模型。
强一致性
每次读取都能获取最新的写入数据。在不阻塞的情况下跨微服务实现这一点非常困难,通常需要分布式锁机制。
最终一致性
数据将在一段时间后达到一致。更新以异步方式传播。这是大多数微服务的标准。它支持高可用性,但要求应用程序处理临时的数据不一致问题。
可观测性与追踪 🔍
绘制完地图后,你需要工具来监控它。分布式追踪可以让你沿着请求ID追踪每个服务中的调用过程。这对于调试至关重要。
日志应相互关联。如果一个请求失败,网关、订单服务和支付服务的日志必须能够关联起来。这种关联就是你数据流图的数字孪生。
指标也是流程的一部分。你应该跟踪消息的数量、调用的延迟和错误率。这些指标验证了你所设计的数据路径的健康状况。
维护的最佳实践 🛠️
只有当图表保持准确时,它才真正有用。系统在不断演进,地图也必须随之更新。
- 自动化生成: 尽可能从代码或基础设施即代码中生成图表。这可以减少人为错误。
- 版本控制: 将你的图表与代码存储在同一个代码仓库中。在拉取请求时进行审查。
- 定期审计: 安排每季度一次的审查,以确保地图与实际运行的系统一致。
- 文档化协议: 明确定义数据格式。使用模式来确保服务间的数据结构一致。
分布式流中的挑战 ⚠️
映射这些系统并非没有困难。网络会故障,服务会重启,数据可能丢失。
网络延迟: 服务之间的物理距离会影响性能。你必须在时间逻辑中考虑这一点。
数据碎片化: 数据分散在多个存储中。要重建一个实体的完整视图,需要从不同来源合并数据。这增加了查询的复杂性。
编排 vs. 舞台调度: 你必须决定由谁来控制流程。编排使用中央协调者,而舞台调度依赖事件。两者在可见性和控制权方面各有权衡。
未来可扩展的设计 🔮
技术在不断变化,协议也在演进。你的地图应具备足够的抽象性,以应对这些变化。
关注业务逻辑,而非实现细节。描述数据的含义,而不仅仅是编码方式。这种抽象使你能够在不重写整个架构的情况下更换底层技术。
考虑可扩展性。流程能否承受十倍的负载?地图是否能显示出潜在的瓶颈?从一开始就为增长而设计。
关于数据逻辑的最后思考
使用数据流逻辑来映射微服务是架构师的一项基础技能。它将讨论从抽象的代码转移到具体的流动过程。通过可视化数据流,团队能够更好地做出关于弹性、安全性和性能的决策。
保持地图更新需要纪律,确保每个人都理解路径则需要协作。但结果是一个更易于构建、更易于调试、更易于扩展的系统。数据流动清晰,系统在压力下依然保持稳定。
投入时间在这些图表上。它们是你系统生命线的文档。当生产服务器断电时,正是这些地图指引着恢复工作。