











数据流图(DFD)是系统分析与设计中的基石。它们以可视化方式展示信息在系统中的流动过程,突出外部实体、内部处理过程、数据存储以及连接它们的数据流之间的交互。虽然这一概念简单明了,但这些图表的详细程度会因所需细节层次的不同而显著变化。在这一层级结构中,最关键的两个阶段是第0级和第1级DFD。理解这两个层级之间的区别,对于需要在不陷入不必要的复杂性的情况下传达系统逻辑的架构师、分析师和利益相关者而言至关重要。
本指南将探讨第0级和第1级图表在结构上的差异、应用场景以及最佳实践。我们将分析如何从高层次的上下文视图过渡到详细的职能分解,确保系统文档的清晰性和精确性。
🧭 什么是第0级数据流图?
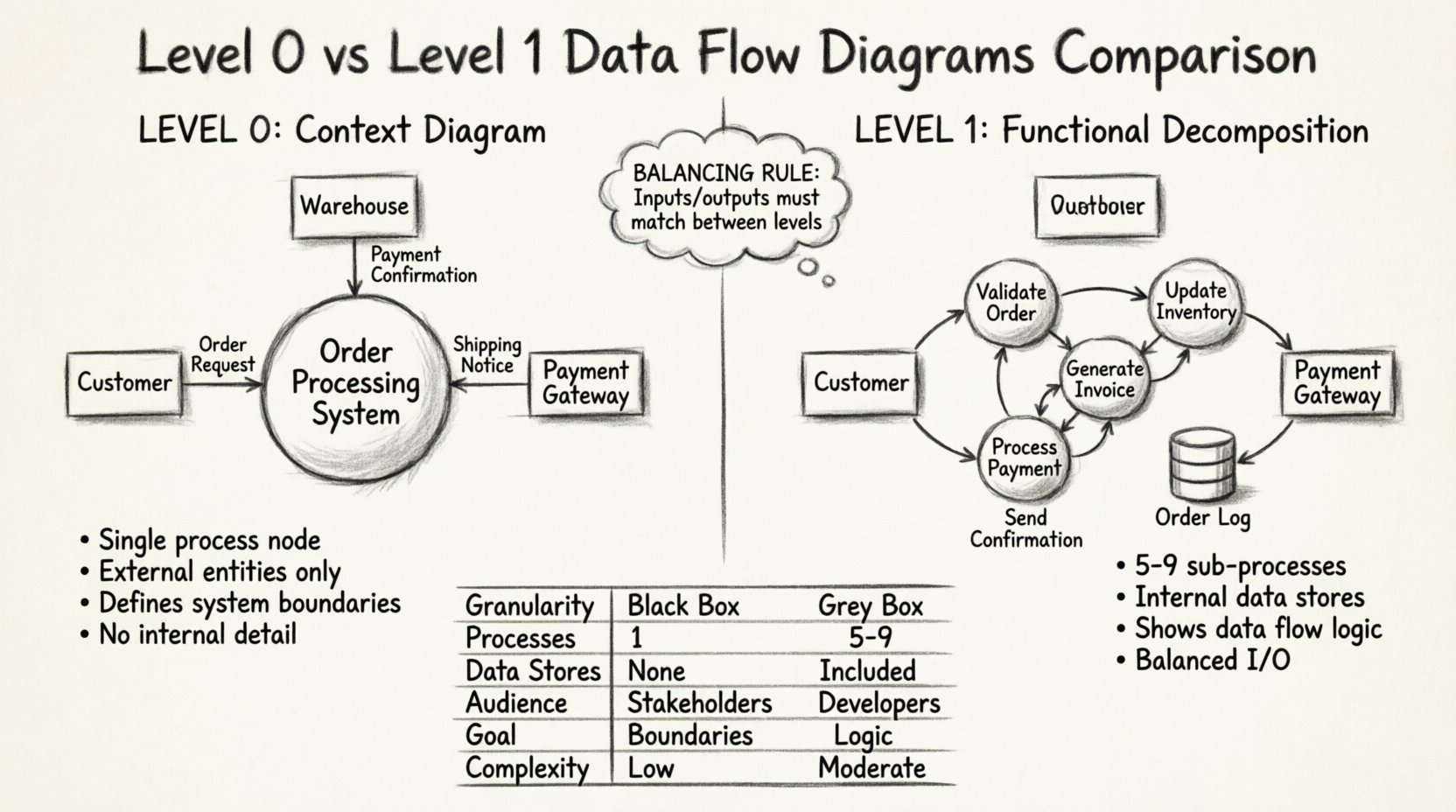
第0级DFD通常被称为上下文图,将系统表示为一个单一的、整体的处理过程。它是DFD层级结构中的最高抽象级别。此处的主要目标是界定系统的边界,并展示系统与外部世界之间的交互方式。
关键特征
- 单一处理节点: 整个系统被描绘为一个圆圈或圆角矩形,通常以系统名称进行标注。
- 外部实体: 这些是存在于系统边界之外的数据源或数据目的地。例如用户、其他系统或监管机构。
- 数据流: 箭头表示外部实体与系统之间的数据输入和输出。
- 无内部细节: 图中不显示任何数据存储、子过程或内部数据流动。
此图回答的问题是:“系统做什么,与谁交互?” 它通常是在需求收集阶段创建的第一个成果。在深入研究具体机制之前,它为利益相关者提供了对项目范围的共同理解。
第0级的视觉结构
想象页面中央有一个大圆圈,标注为“订单处理系统”。该圆圈周围是代表外部实体的矩形,例如“客户”、“仓库”和“支付网关”。线条将这些矩形连接到中心圆圈,标注为交换的数据,如“订单请求”或“支付确认”。这种简洁性确保非技术利益相关者能够快速理解系统的目的。
⚙️ 什么是第1级数据流图?
第1级DFD通过将第0级中的单一系统过程分解为若干主要子过程,对第0级图进行扩展。它揭示了系统的内部逻辑,但不涉及过于细节的内容。这一层级在高层次上下文与详细设计规范之间架起了桥梁。
关键特征
- 分解后的处理过程: 第0级中的单一过程被分解为5到9个主要子过程。这一数量是一个指导原则,以保持图表的可读性。
- 内部数据存储: 该层级引入了数据存储库,例如数据库、文件或队列,用于存放数据。
- 细化的数据流: 箭头现在展示了数据在子过程与数据存储之间如何流动。
- 输入/输出平衡 第0层流程的输入和输出必须与第1层子流程的汇总输入和输出相匹配。
此图回答了以下问题:“系统是如何实现其功能的?” 对于需要理解信息流以构建底层架构的开发人员和系统架构师来说,这一点至关重要。
第1层的视觉结构
以之前的例子为例,“订单处理系统”这个圆被一组较小的圆所取代。其中一个可能是“验证订单”,另一个是“更新库存”,第三个是“生成发票”。这些圆通过箭头连接,表示数据在它们之间流动。此外,还可能出现一个圆柱形,代表“客户数据库”或“订单日志”。这种结构使团队能够看到依赖关系和数据保留需求。
🆚 对比:第0层 vs 第1层
为了澄清两者的区别,我们可以从多个维度对这两个层级进行比较。此表格突出了它们在结构和功能上的差异。
| 特性 | 第0层(上下文图) | 第1层(功能分解) |
|---|---|---|
| 粒度 | 系统级视图(黑箱) | 主要功能模块(灰箱) |
| 流程数量 | 恰好1个 | 5到9个主要子流程 |
| 数据存储 | 未显示任何 | 明确包含 |
| 受众 | 利益相关者、管理层、用户 | 开发人员、系统架构师、分析师 |
| 主要目标 | 定义系统边界 | 定义内部逻辑和流程 |
| 复杂度 | 低 | 中等 |
🔄 平衡的概念
从0级过渡到1级时的一个关键规则是平衡。进入和离开0级流程的输入和输出,必须与进入和离开1级子流程的输入和输出的总和完全相同。这确保了在分解过程中不会产生或销毁任何数据。
例如,如果0级显示“客户数据”作为进入系统的输入,那么1级必须显示“客户数据”流入至少一个子流程。如果0级显示“收据”作为离开系统的输出,那么1级必须显示一个子流程生成“收据”数据。未能保持这种平衡,表明分析中存在错误或设计中缺少某个组件。
🛠 设计的最佳实践
创建有效的DFD需要纪律性,并遵循特定的规范。遵循这些指南有助于保持清晰,避免混淆。
1. 命名规范
流程应使用动词-名词结构命名(例如,“计算税款”而非“税款”)。数据流应使用表示内容的名词短语命名(例如,“发票详情”而非“发票”)。外部实体应清晰命名,以反映提供数据的参与者或系统。
2. 避免交叉
图示布局应尽量减少数据流线的交叉。交叉的线条会产生视觉干扰,使信息路径难以追踪。如果无法避免交叉,应确保它们明显可辨,并清晰标注。
3. 数据存储的一致性
确保数据存储在各图示中标签一致。1级中名为“客户数据库”的数据库在2级中不应被重命名为“用户表”。一致性有助于在不同层级间进行导航和理解。
4. 限制子流程数量
虽然1级应足够详细,但不应事无巨细。如果单个子流程包含过多逻辑,可能需要进一步分解为2级。然而,1级通常应保持在可管理的范围内,以避免让读者感到信息过载。
📈 各层级的使用时机
选择合适的层级取决于项目阶段和受众。
使用0级的情况:
- 项目启动: 早期确立范围和边界。
- 高管摘要: 为非技术型领导提供高层次的概览。
- 接口定义: 明确系统与外部系统连接的位置。
使用1级的情况:
- 系统设计: 指导开发团队理解内部逻辑。
- 集成规划: 识别数据存储和内部数据流的位置。
- 测试策略: 基于流程路径和数据转换来定义测试用例。
🔍 常见挑战与解决方案
创建这些图表通常会带来一些特定的挑战。了解这些问题有助于生成准确的成果。
问题:缺失的数据存储
分析师有时会忘记在一级图中包含数据存储,误以为数据可以直接在过程之间流动。然而,大多数系统都需要持久化。请确保识别出事务之间数据保存的位置。
问题:幽灵数据流
幽灵数据流是指指向无处或起源于无处的箭头。每个箭头都必须从一个源(过程、实体或存储)开始,并结束于一个目标。检查你的图表,确保所有线条都正确锚定。
问题:过度复杂
试图在一级图中展示每一个步骤,可能导致图表杂乱无章。如果一级图变得难以阅读,应考虑将系统拆分为逻辑子系统,并为每个子系统创建独立的一级图,而不是绘制一个庞大的单一图表。
🔗 过渡到更高级别
一旦一级图完成,它就成为二级图的父图。一级图中的每个子过程都可以进一步分解。这种递归过程持续进行,直到过程足够简单,可以直接作为代码或配置实现。一级图是关键步骤,确保在深入具体算法或数据库模式的细节之前,分解策略是可靠的。
📝 差异总结
0级和1级数据流图在系统分析中扮演着不同但互补的角色。0级图定义了系统的边界及其与外部环境的关系。1级图则揭示了主要功能组件和内部数据处理。两者共同构成了一种分层视图,既支持战略规划,也支持战术执行。
通过遵循平衡性、命名一致性以及适当粒度的原则,团队可以利用这些图表减少歧义、统一预期,并构建稳健的系统。无论你是记录遗留应用程序还是设计新架构,掌握这两个层级之间的区别,都能确保清晰的沟通和有效的系统建模。