











理解信息如何在系统中流转,是构建可靠软件架构的根本。当我们使用数据流图(DFD)来描绘系统时,我们不仅仅是画出方框和线条;我们实际上是在绘制数据本身的生命周期。分析数据流动路径需要对数据的来源、转换方式、存储位置以及退出环境的方式进行严谨的考察。这一过程确保了整个架构在完整性、性能和安全性方面的保障。
如果没有清晰的蓝图,数据可能会丢失、重复,或被未经授权的访问暴露。全面的分析可以在生产环境受到影响之前,揭示瓶颈、隐藏的依赖关系以及潜在的故障点。本指南探讨了以精确和清晰的方式剖析这些路径的方法论。
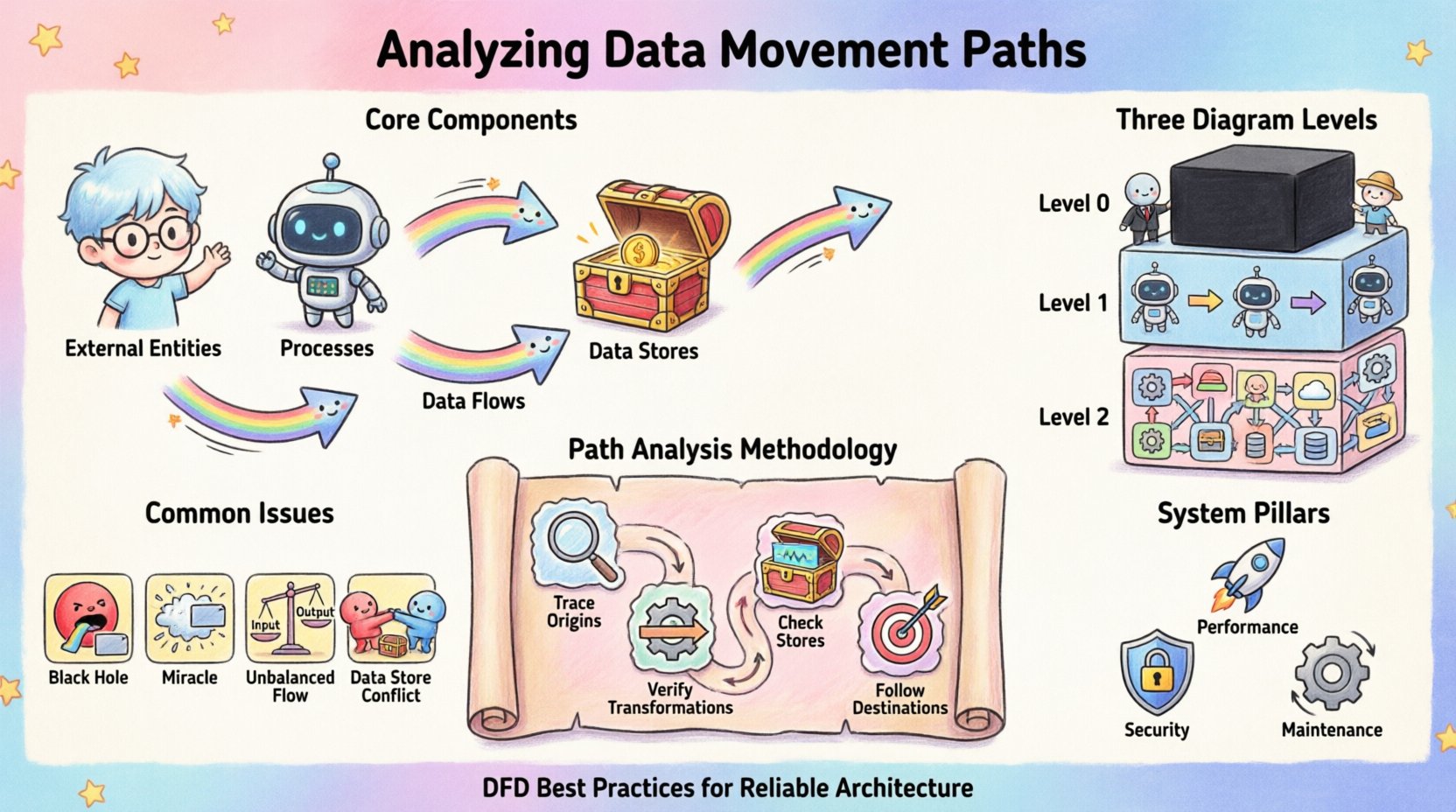
数据流动的核心组件 🧩
要有效分析流动,首先必须识别促成流动的各个独立元素。每个DFD都依赖于一套一致的术语来描述数据流。忽略这些定义会导致模型出现歧义。
- 外部实体: 这些代表系统边界之外的来源或目的地。它们发起数据请求或接收处理后的输出。例如,人类用户、其他系统或第三方服务。
- 处理过程: 这些是数据的转换过程。一个处理过程接收输入数据,应用逻辑或规则,生成输出。它是系统内部变化的引擎。
- 数据存储: 这些是信息被保存以备后续检索的存储库。它们提供持久性,使数据能够超越单个过程的即时执行而持续存在。
- 数据流: 这些是连接各个组件的箭头。它们代表了数据包或记录在实体、处理过程和存储之间实际的流动。
每个箭头都必须带有描述性标签,明确指出正在传输的信息内容。像“信息”或“数据”这样模糊的标签会掩盖传输的具体性质,使分析变得困难。
绘图中的详细程度层级 📊
数据流动很少是静态的;它存在于不同抽象层次上。单一图表无法捕捉每一字节的信息。相反,我们采用分层方法来分解系统。
1. 上下文图(第0层)
最高层级的视图将整个系统视为一个单一的黑箱。它展示了系统与外部实体的交互。这对于理解系统边界至关重要。它回答的问题是:系统与外部世界交换什么?
2. 第1层图
在此层级,黑箱被展开为主要的处理过程。该层级揭示了主要的子系统以及高层数据在它们之间的流动方式。它提供了系统内部架构的宏观视图,而无需陷入琐碎的逻辑细节。
3. 第2层及以下层级图
对于复杂的过程,会进一步进行分解。这些详细视图展示了具体的数据转换和数据的细粒度流动。该层级对于识别特定的验证步骤和错误处理机制至关重要。
在分析路径时,层级间的一致性至关重要。进入第1层处理过程的数据必须与离开该过程的数据相匹配。层级之间的差异表明设计中存在漏洞。
路径分析的方法论 🔍
追踪数据路径是一项系统性的工作。它涉及从源头到终点的全程追踪。这一过程有助于识别逻辑错误和缺失的连接。
步骤1:追踪输入来源
从一个外部实体开始。沿着箭头进入系统。询问该数据接下来会去往何处。是进入一个处理过程还是存储?如果进入处理过程,该过程是否具备足够的信息来运行?每个处理过程都必须至少有一个输入和一个输出。
步骤2:验证转换
当数据进入一个处理过程后,分析其变化。输出是否逻辑上源自输入?有时,输出中会出现输入中不存在的数据。这被称为“奇迹”,表明存在缺失的输入,或应被记录的硬编码常量。
步骤3:检查数据存储
识别每一个读取和写入操作。数据存储不应成为死胡同。如果数据流入一个存储,必须在某个时刻有相应的数据流出,除非该数据已被永久归档。验证图中隐含的模式是否与物理存储需求一致。
步骤4:追踪输出目的地
处理后的数据去往何处?它会返回给用户吗?是否会触发另一个流程?它是否会离开系统边界?确保每个输出路径都得到妥善处理。产生数据但没有目的地的孤立流程,表明设计不完整。
常见结构问题 ⚠️
在分析过程中,某些特定模式会浮现,表明存在设计缺陷。及早识别这些模式可以避免后期高昂的重构成本。
| 问题 | 描述 | 影响 |
|---|---|---|
| 黑洞 | 一个流程有输入,但没有输出。 | 数据被消耗后消失。逻辑不完整。 |
| 奇迹 | 一个流程有输出,但没有输入。 | 数据凭空出现。逻辑未定义。 |
| 流量失衡 | 各级之间的输入和输出数据不匹配。 | 分解过程中数据完整性丢失。 |
| 数据存储冲突 | 多个流程在未加锁的情况下写入同一存储。 | 并发问题和数据损坏。 |
安全与合规性考虑 🔒
安全不是附加功能;它是数据流动本身的一个属性。分析数据路径有助于识别敏感信息的存放位置和流动路径。
识别敏感数据
追踪个人身份信息(PII)或财务记录。如果敏感数据在流程之间流动,是否需要加密?如果数据存储在某个存储中,访问是否受控?图表应突出显示这些敏感数据流,例如使用不同的线条样式或标签。
访问控制点
每个流程都可能成为潜在的守门人。分析每个流程的认证需求。数据流图是否暗示任何流程都可以访问任何存储?这通常表明需要更严格的基于角色的访问控制。
法规合规性
法规通常规定数据可以存放的位置。例如,某些司法管辖区要求数据必须保留在特定地理边界内。任何跨越这些边界的移动路径都必须标记以供法律审查。该图表可作为合规架构的证据。
性能与优化 🚀
数据移动并非免费。它会消耗带宽、处理能力和时间。分析路径有助于优化这些资源。
识别瓶颈
寻找具有多个高流量输入和输出的流程。这些流程很可能成为性能瓶颈。如果一个流程在转发前从五个不同来源聚合数据,它在高负载下可能会不堪重负。考虑将其拆分为并行流程。
延迟分析
计算数据到达目的地所需经过的跳数。每次跳转都会引入延迟。如果用户请求在返回结果前需要经过十个处理过程,系统就会显得缓慢。减少转换次数可以提高响应速度。
冗余减少
检查是否存在重复的数据流。如果相同的信息被发送到三个不同的处理过程,应考虑它们是否可以共享一个公共数据存储。这可以减少网络流量并确保一致性。
保持图表准确性 🔄
图表是一个动态文档。随着系统的发展,路径也会发生变化。保持准确性需要有条不紊的方法。
版本控制
对数据流结构的每一次更改都应进行版本化。这使得团队能够追踪某个特定路径被修改的时间。这对于调试和影响分析至关重要。
影响分析
在修改一个处理过程之前,应追踪所有相关联的数据流。更改一个过程可能会导致下游消费者失效。图表有助于可视化这些依赖关系。如果存储中的数据格式发生变化,所有读取该数据的处理过程都必须更新。
文档标准
建立命名和标注的规则。一致的命名规范能让新团队成员更容易理解图表。应有一个清晰的图例,解释用于安全或性能标记的任何特殊符号或线型。
与其他模型的集成 🤝
数据流图并非孤立存在。它们与其他建模技术相辅相成。
实体关系图(ERD)
虽然DFD关注的是数据的流动,ERD则关注结构。交叉参考可以确保通过处理过程的数据与数据库中定义的模式相匹配。如果一个处理过程期望的是“CustomerID”,但ERD中定义的是“ClientNum”,则存在不匹配。
状态转换图
DFD展示的是什么在移动,而状态图展示的是何时移动。结合使用有助于理解数据流动如何触发状态变化。例如,“PaymentReceived”数据流可能触发从“Pending”到“Shipped”的状态转换。
分析实践总结 ✅
分析数据流动路径的纪律在于清晰与控制。它能将抽象的需求转化为具体的架构决策。通过严格追踪每一个箭头并验证每一次转换,架构师能够构建出具有韧性且易于理解的系统。
这一实践要求注重细节。它需要质疑关于数据来源和去向的每一个假设。当正确执行时,生成的图表将成为开发、测试和维护的蓝图。它成为业务利益相关者与技术团队之间的共同语言,确保每个人都理解数据的旅程。
随着系统复杂性的增加,清晰映射的需求也随之上升。一个经过充分分析的数据流图是对软件长期稳定性的投资。它能降低数据丢失、安全漏洞和性能下降的风险。通过遵循这些分析标准,团队能够确保系统在扩展过程中依然保持稳健。