











情報がシステムをどのように通過するかを理解することは、信頼性の高いソフトウェアアーキテクチャを構築する上で基本的なことである。データフローダイアグラム(DFD)を使ってシステムをマッピングする際、単にボックスと線を描いているわけではない。我々はデータそのもののライフサイクルを記録しているのである。データ移動経路の分析には、データがどこから来ているか、どのように変換されるか、どこに一時的に保管されるか、そして環境からどのように出ていくかを厳密に検証する必要がある。このプロセスにより、アーキテクチャ全体にわたって整合性、パフォーマンス、セキュリティが確保される。
明確なマップがなければ、データは紛失したり重複したり、不正アクセスの対象になったりする。包括的な分析により、本番環境に影響を与える前に、ボトルネックや隠れた依存関係、潜在的な障害点を発見できる。このガイドでは、これらの経路を正確かつ明確に解体するための手法について探求する。
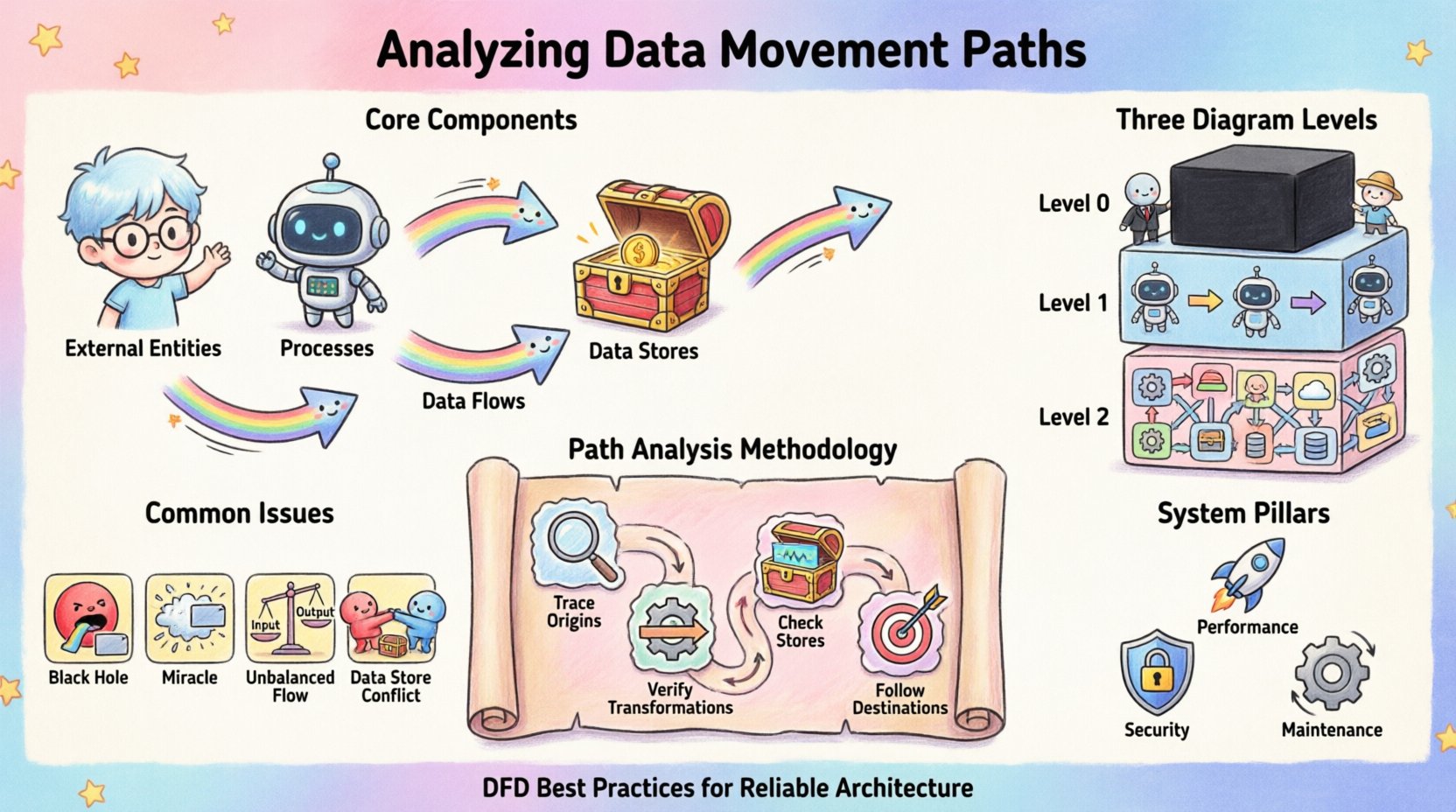
データ移動のコアコンポーネント 🧩
効果的に移動を分析するためには、まずそれを可能にする明確な要素を認識する必要がある。すべてのDFDは、流れを記述するための一貫した語彙に依存している。これらの定義を無視すると、モデルに曖昧さが生じる。
- 外部エンティティ: これらはシステム境界外の情報源または宛先を表す。データ要求を開始したり、処理された出力を受信したりする。人間のユーザー、他のシステム、第三者のサービスなどが例である。
- プロセス: これらは変換を表す。プロセスは入力データを受け取り、論理やルールを適用し、出力を生成する。これはシステム内の変化の原動力である。
- データストア: これらは情報が後で取得できるように保管されるリポジトリである。永続性を提供し、プロセスの即時実行を超えてデータが存続できるようにする。
- データフロー: これらはコンポーネントをつなぐ矢印である。これらはエンティティ、プロセス、ストア間でのデータパケットやレコードの実際の移動を表している。
各矢印には、何が移動しているかを正確に示す説明ラベルが必要である。”info”や”data”といった曖昧なラベルは、転送の具体的な性質を隠蔽し、分析を困難にする。
図示における詳細レベル 📊
データ移動はほとんど静的ではない。抽象化のさまざまなレベルに存在する。1つの図ではすべてのバイトの情報を捉えることはできない。代わりに、階層的なアプローチを用いてシステムを分解する。
1. コンテキスト図(レベル0)
最も高いレベルの視点では、システム全体を単一のブラックボックスとして扱う。システムが外部エンティティとどのように相互作用しているかを示す。境界を理解する上で不可欠である。この図は、「システムは外部世界と何をやり取りしているか?」という問いに答える。
2. レベル1図
ここでは、ブラックボックスが主要なプロセスに分解される。このレベルでは、主要なサブシステムとそれらの間を流れる高レベルのデータの動きが明らかになる。細かい論理に巻き込まれることなく、内部アーキテクチャのマクロな視点を提供する。
3. レベル2図およびそれ以下のレベル
複雑なプロセスに対して、さらに分解が行われる。これらの詳細なビューでは、特定の変換やデータの粒度の高い流れが示される。このレベルは、特定の検証ステップやエラー処理メカニズムを特定する上で不可欠である。
経路を分析する際、レベル間の一貫性が極めて重要である。レベル1のプロセスに入力されるデータは、出力されるデータと一致しなければならない。レベル間の不一致は、設計上のギャップを示している。
経路分析の手法 🔍
データ経路を追跡することは、体系的な作業である。これは、データの発信元から受信先までを追うプロセスである。このプロセスにより、論理的な誤りや欠落した接続を特定するのに役立つ。
ステップ1:入力元の追跡
外部エンティティから始める。矢印に従ってシステム内へ進む。次にこのデータはどこへ行くかを問う。プロセスへ行くのか、ストアへ行くのか。もしプロセスへ行く場合、そのプロセスは機能するのに十分な情報を持っているか。すべてのプロセスには少なくとも1つの入力と1つの出力が必要である。
ステップ2:変換の検証
データがプロセスに入ると、変化を分析する。出力は入力から論理的に導かれるか。時折、入力に存在しなかったデータがプロセスの出力に現れることがある。これは「ミラクル」と呼ばれ、入力が欠けているか、ドキュメント化すべきハードコードされた定数を示している。
ステップ3:データストアの確認
すべての読み取りおよび書き込み操作を特定する。データストアはデッドエンドであってはならない。データがストアに入力される場合、そのデータがどこかで出力される流れが存在しなければならない。ただし、データが永続的にアーカイブされている場合は除く。図から示唆されるスキーマが物理的なストレージ要件と一致しているかを確認する。
ステップ4:出力先の追跡
処理されたデータはどこへ行くのでしょうか?ユーザーに戻るのでしょうか?別のプロセスをトリガーするのでしょうか?システムの境界を越えていくのでしょうか?すべての出力パスが適切に管理されていることを確認してください。出力先のないデータを生成する孤立したプロセスは、設計が不完全であることを示しています。
一般的な構造的問題 ⚠️
分析の過程で、設計上の欠陥を示す特定のパターンが浮かび上がります。これらのパターンを早期に認識することで、後々の高コストな再設計を防ぐことができます。
| 問題 | 説明 | 影響 |
|---|---|---|
| ブラックホール | プロセスに入力はあるが、出力がない。 | データが消費され、消え去る。論理が不完全である。 |
| ミラクル | プロセスに出力はあるが、入力がない。 | データがどこからともなく出現する。論理が定義されていない。 |
| バランスの取れていないフロー | レベル間で入力データと出力データが一致しない。 | 分解過程でデータの整合性が損なわれる。 |
| データストアの衝突 | 複数のプロセスがロックなしで同じストアに書き込みを行う。 | 同時実行の問題とデータの破損。 |
セキュリティおよびコンプライアンスの考慮事項 🔒
セキュリティは追加機能ではなく、データ移動そのものに内在する性質です。パスを分析することで、機密情報がどこに存在し、どのように移動しているかを特定できます。
機密データの特定
個人を特定できる情報(PII)や財務記録を追跡してください。機密データがプロセス間を移動する場合、暗号化が必要でしょうか?ストアに保存されている場合、アクセスは制御されていますか?図面では、これらの機密なデータフローを明確に示す必要があります。たとえば、異なる線のスタイルやラベルを使用するなどして区別してください。
アクセス制御ポイント
各プロセスは潜在的なゲートキーパーとして機能します。各プロセスの認証要件を分析してください。データフローダイアグラムが、任意のプロセスが任意のストアにアクセス可能であることを示唆しているでしょうか?これは、より厳格なロールベースのアクセス制御の必要性を示していることが多いです。
規制遵守
規制は、データがどこに保管できるかを規定することが多いです。たとえば、一部の管轄区域では、データが特定の地理的境界内に留まることが求められます。これらの境界を越えるデータ移動パスは、法的レビューの対象となるべきです。図面は、コンプライアンスアーキテクチャの証拠として機能します。
パフォーマンスと最適化 🚀
データ移動にはコストがかかります。帯域幅、処理能力、時間の消費を伴います。パスを分析することで、これらのリソースを最適化できます。
ボトルネックの特定
複数の高容量の入力と出力を備えたプロセスを探してください。これらはパフォーマンスのボトルネックになりやすいです。たとえば、1つのプロセスが5つの異なるソースからデータを集約して次に渡す場合、負荷がかかると処理に苦戦する可能性があります。これを並列プロセスに分割することを検討してください。
レイテンシ分析
データが宛先に到達するために経由するホップの数をカウントする。各ホップはレイテンシを引き起こす。ユーザーのリクエストが結果を返す前に10のプロセスを通過する必要がある場合、システムは遅く感じられる。変換の数を減らすことで応答性が向上する。
冗長性の低減
重複するデータフローがないか確認する。同じ情報が3つの異なるプロセスに送信されている場合、それらが共通のデータストアを共有できるかどうか検討する。これによりネットワークトラフィックが削減され、一貫性が保たれる。
図の正確性の維持 🔄
図は動的な文書である。システムが進化するにつれて、経路も変化する。正確性を維持するには、厳格なアプローチが求められる。
バージョン管理
データフロー構造のすべての変更はバージョン管理するべきである。これにより、特定の経路がいつ変更されたかを追跡できる。デバッグや影響分析において不可欠である。
影響分析
プロセスを変更する前に、すべての接続されたフローを追跡する。1つのプロセスを変更すると、下流のコンシューマーが破損する可能性がある。図はこれらの依存関係を可視化するのに役立つ。データストア内のデータ形式が変更された場合、それから読み取るすべてのプロセスを更新しなければならない。
ドキュメントの標準化
命名やラベル付けに関するルールを定める。一貫した命名規則により、新しく加入するチームメンバーにとって図が読みやすくなる。明確な凡例を用意し、セキュリティやパフォーマンスのマーカーに使用される特別な記号や線種を説明する。
他のモデルとの統合 🤝
データフローダイアグラムは孤立して存在するものではない。他のモデリング手法と補完し合う。
エンティティ関係図(ERD)
DFDは動きに注目するが、ERDは構造に注目する。両者を相互参照することで、プロセスを通過するデータがデータベースで定義されたスキーマと一致していることを確認できる。プロセスが「CustomerID」を期待しているが、ERDでは「ClientNum」と定義されている場合、不一致が生じる。
状態遷移図
DFDは何が移動するかを示すが、状態図はいつ移動するかを示す。これらを組み合わせることで、データの移動が状態変化を引き起こす仕組みを理解できる。たとえば、「PaymentReceived」のフローが、「Pending」から「Shipped」への状態変更を引き起こす可能性がある。
分析手法に関する結論 ✅
データ移動経路を分析するという専門性は、明確さと制御のためのものである。抽象的な要件を具体的なアーキテクチャ設計に変換する。すべての矢印を厳密に追跡し、すべての変換を検証することで、耐障害性があり理解しやすいシステムを構築できる。
この作業は細部への注意を要求する。データがどこから来てどこへ行くのかというすべての仮定を疑問視する必要がある。正しく行われれば、結果として得られる図は開発、テスト、保守のためのブループリントとなる。ビジネス関係者と技術チームの間で共有される言語となり、データの旅路を誰もが理解できるようにする。
システムの複雑さが増すにつれて、明確なマッピングの必要性が高まる。よく分析されたデータフローダイアグラムは、ソフトウェアの長期的な安定性への投資となる。データ損失、セキュリティ侵害、パフォーマンス劣化のリスクを低減する。これらの分析基準に従うことで、チームはスケーリングする中でもシステムの堅牢性を保証できる。