











現代の情報アーキテクチャにおいて、データの整合性は信頼性のあるシステム動作の基盤となる。データが処理環境に入ると、運用を妨害したり、セキュリティを損なったり、下流の出力を破損する可能性のあるリスクを伴う。システム入力の検証は単なる安全確認ではなく、システム設計に組み込まれた根本的な論理的要件である。データフローダイアグラム(DFD)内のフローロジックを活用することで、エンジニアは検証がどこで行われるか、エラーがどのように処理されるか、データがアーキテクチャをどのように遷移するかを明確に把握できる。このアプローチにより、ビジネスロジックに影響を与える前に、システムに入力されるすべての情報が必要な基準を満たしていることが保証される。
本記事では、フローロジックの視点から入力検証のメカニズムを検討する。検証ルールを視覚的に表現する方法、データ受容のための意思決定ポイントの構造、フローを中断せずにエラー状態を管理する方法について考察する。これらのメカニズムを理解することで、不正なデータや外部からの脅威に対して耐性を持つシステムを構築できるようになる。
検証におけるデータフローダイアグラムの理解 📊
データフローダイアグラムは、情報がシステム内でどのように移動するかを視覚的に表現するものである。プロセス、データストア、外部エンティティ、そしてデータそのものを示す。検証の文脈において、DFDは信頼の地図となる。データが受け入れられる場所、検証が行われる場所、保存または破棄される場所を示す。
標準的なDFDは、以下の4つの主要な要素から構成される:
- プロセス:データの変換。検証ロジックは通常、ここに配置される。
- データストア:データが保存されるリポジトリ。データがストアに入力される前に検証が行われなければならない。
- 外部エンティティ:システム境界外のデータの発信元または受信先。入力はここから発生する。
- データフロー:要素間でのデータの移動。検証チェックはこれらの経路で行われる。
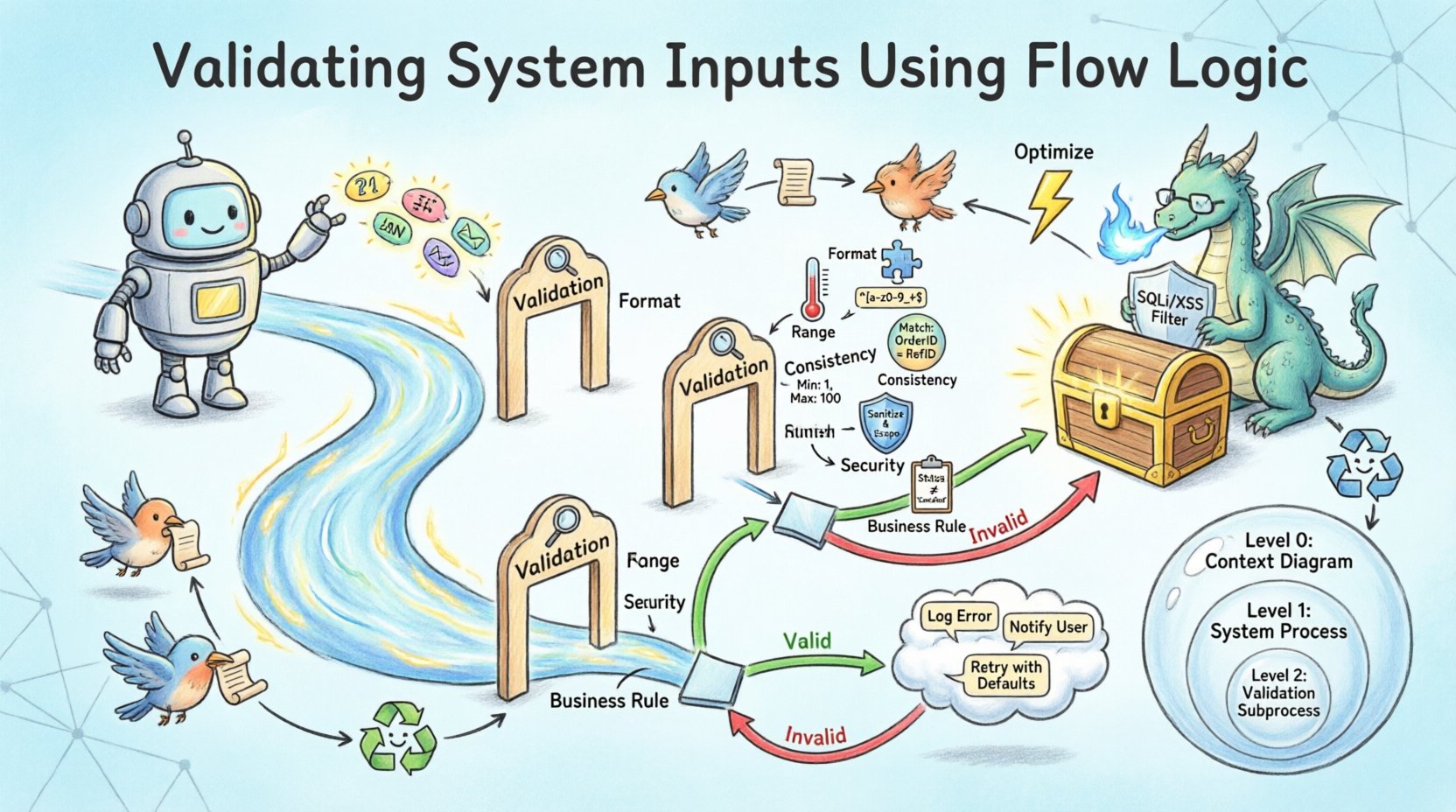
検証を設計する際、プロセス要素が極めて重要となる。単にポイントAからポイントBへデータを移動するだけでは不十分である。プロセスはデータを一連のルールに基づいて評価しなければならない。図では、このプロセスはしばしば「検証」または「クリーニング」とラベル付けされた特定のサブプロセスとして表現される。この視覚的サインは、ここに入力のフィルタリングを行うロジックが存在することを開発者に思い出させる。
検証ロジックをフローフレームにマッピングする 🧠
フローロジックとは、データの経路を決定する操作の順序を指す。検証においては、このロジックがデータが次の段階に進むか、エラー処理に振り分けられるかを決定する。これを実装するには、意思決定ポイントを明確に理解する必要がある。
ユーザー情報を収集するデータ入力フォームを例に挙げよう。フローロジックは以下の属性を検証しなければならない:
- 存在性:フィールドが入力されているか?
- 型:入力が正しいデータ型か(例:整数 vs. 文字列)?
- 範囲:値が許容可能な範囲内にあるか?
- 形式:文字列が要求されたパターンに一致するか(例:メールアドレス)?
DFDでは、これらのチェックが分岐を生じさせる。データがすべてのチェックを通過すれば、フローは主プロセスへ進む。もし失敗すれば、フローはエラー処理プロセスへ分岐する。この分岐は堅牢なアーキテクチャにとって不可欠である。これがないと、不正なデータが静かに伝播し、計算エラーまたはセキュリティ上の脆弱性を引き起こす可能性がある。
意思決定ポイントのメカニズム
意思決定ポイントとは、フローが分岐する場所である。フローロジック図では、この場所はしばしば菱形の形状、または「有効」と「無効」という2つの異なるデータフローを出力する特定のプロセスノードとして視覚化される。「有効」のフローは主プロセスパイプラインへ継続する。「無効」のフローはエラー応答をトリガーするか、修正ループを開始する。
図の中でクライアント側検証とサーバーサイド検証を区別することは重要である。クライアント側検証はユーザー体験を向上させるが、サーバーサイド検証こそが真のゲートキーパーである。DFDにおいては、サーバーサイドのチェックがデータストアに到達する前の最終的な障壁となるべきである。これにより、インターフェースがバイパスされた場合でも、コアシステムは保護された状態を保つことができる。
入力検証ルールの種類 🛡️
検証は単一の概念ではない。複数の段階の検査を含む。各段階は異なる目的を持ち、フローロジック内での実装戦略も異なる。
| 検証の種類 | 目的 | 例の論理 |
|---|---|---|
| フォーマット検証 | データが期待される構造と一致することを保証する | 電話番号の正規表現による照合 |
| 範囲検証 | データが数値の範囲内にあることを保証する | 年齢は18歳以上120歳以下でなければなりません |
| 一貫性検証 | データが他の入力と整合していることを保証する | 終了日は開始日より後に設定しなければならない |
| セキュリティ検証 | 悪意のあるコードのインジェクションを防止する | テキストフィールド内のHTMLタグをクリーンアップする |
| ビジネスルール検証 | データが運用上の制約に適合していることを保証する | 割引は50%を超えることはできない |
これらのルールをフローロジックに統合するには、慎重な順序付けが必要です。セキュリティ検証は一般的にプロセスの初期段階で実行されるべきであり、悪意のあるペイロードの高コストな処理を防ぐためです。フォーマット検証は通常、論理的な比較を行う前にデータ型が正しいことを確認するために最初のステップです。ビジネスルール検証は、データがすでに正規化されている場合に依存するため、しばしば最後に行われます。
エラー処理フローとフィードバックループの扱い 🔄
信頼性の高いシステムは、無効なデータを単に拒否するだけでなく、その拒否をスムーズに処理する必要があります。これがフローロジックの「無効」分岐が機能する場所です。エラー処理フローは、ユーザーまたはシステム管理者に問題を通知する仕組みに繋がるべきであり、機密的な内部情報を暴露しないようにする必要があります。
DFDにおいて、エラー処理プロセスには以下の内容を含めるべきです:
- ログ記録:デバッグ用にエラーの詳細を記録する。このフローは監査ログデータストアに送られる。
- 通知:ユーザーに警告する。このフローは外部エンティティ(ユーザーインターフェース)に送られる。
- 修正:データを修正するための仕組みを提供する。これにより、データが入力ステージに戻るフィードバックループが作成される。
フィードバックループは使いやすさにとって不可欠です。ユーザーが無効なメールアドレスを含むフォームを送信した場合、システムはすぐに修正できるようにすべきです。フローの観点から言えば、データは入力フェーズから永久に離れるわけではありません。検証ロジックに再評価され、合格するか、ユーザーが操作をキャンセルするまで繰り返されます。これにより、ユーザー体験における行き詰まりを防ぐことができます。
エラーログ記録と監査トレース
セキュリティおよびコンプライアンスの要件により、検証の失敗を記録することが求められることがあります。入力が拒否されたとしても、その試行自体が攻撃の兆候である可能性があります。したがって、検証プロセスから監査ログへの別々のデータフローが存在するべきです。このフローはタイムスタンプ、送信元IPアドレス、および失敗の性質を記録します。ログ記録の障害が正当な処理をブロックしないようにするため、メインのデータフローとは独立して動作します。
検証をプロセスレベルに統合する 🏗️
データフローダイアグラムは、しばしば異なる抽象度のレベルで存在します。レベル0は概要を提供し、レベル1およびレベル2では特定のプロセスを詳細に分解します。検証ロジックはこれらのレベル間で一貫性を保つ必要があります。
レベル0:システム境界
最も高いレベルでは、検証はゲートとして表現される。外部エンティティがデータを送信し、システムはそれを受け入れたり拒否したりする。DFDは入力と出力の境界を示す。この段階で検証に失敗したデータは、内部システムに入ることはない。
レベル1:プロセスの分解
システムを分解する際、特定のプロセスに検証のサブフローが割り当てられる。たとえば、「ユーザー登録」プロセスは「本人確認」「パスワード検証」「連絡先検証」に分割されることがある。これらのサブプロセスそれぞれに独自のフローロジックがある。このレベルのDFDは、これらのチェックを実行するために必要な内部データの移動を示す。
レベル2:詳細なロジック
最も低いレベルでは、ロジックが完全に定義される。ここから実際にコード構造が図から導かれる。このレベルのフローロジックは、操作の正確な順序を指定する。たとえば、ユーザー名がデータベースに存在するかを確認する処理は、その形式が有効かどうかを確認する処理より先に行わなければならない。これにより、既存ユーザーに関する情報を漏洩するリスクを回避できる。
検証中のパフォーマンス最適化 ⚡
検証ロジックは計算上のオーバーヘッドを追加する。すべてのチェックには処理時間がかかる。高負荷のシステムでは、過剰な検証がボトルネックになることがある。DFDは、最適化が必要な場所を特定するのに役立つ。
最適化の戦略には以下がある:
- 早期終了: 基本的なチェックに失敗した場合(例:空のフィールド)、直ちに処理を停止する。複雑なロジックは実行しない。
- キャッシュ: 検証が外部データに依存する場合(例:ユーザーIDをブロック済みアカウントリストと照合する)、そのデータをキャッシュしてデータベース呼び出しを減らす。
- 非同期処理: 重要度の低い検証については、チェックをバックグラウンドキューに移す。これにより、主なデータフローが高速に保たれる。
これらの最適化をDFDに表現する際は、同期処理と非同期処理にそれぞれ異なるデータフローを使用する。これにより、ユーザーをブロッキングする検証と、バックグラウンドで実行される検証が明確になる。また、ストレス下でのシステム動作を理解する必要がある負荷テストのシナリオにおいても役立つ。
フローロジックのセキュリティ上の影響 🔒
無効な入力は、SQLインジェクション、クロスサイトスクリプティング、バッファオーバーフローなどの攻撃の主要な経路である。検証を目的としたフローロジックはファイアウォールとして機能する。しかし、設計が正確でなければならない。
設計における一般的な課題は、入力が信頼できるソースから来ると仮定することである。DFDでは、すべての外部エンティティを潜在的に敵対的とみなすべきである。検証プロセスは、データベースやコマンドラインとやり取りする前に、データをクリーニング(洗浄)しなければならない。このクリーニングは、図内の特定のプロセスノードとして表現される。
さらに、フローロジックは情報漏洩を防ぐ必要がある。検証エラーがユーザー名が存在することを明らかにすると、攻撃者はアカウントを列挙できる。エラーフローは、「無効な資格情報」などの汎用メッセージを提供すべきであり、「ユーザー名が見つかりません」などの具体的な理由を提示すべきではない。このニュアンスは、エラーハンドリングプロセスの説明に反映されるべきである。
検証フローのテストと検証 ✅
フローロジックが設計されると、検証が必要となる。テストは、DFDのパスを通じてデータを送信し、ロジックが正しく機能することを確認するものである。これは、個々の検証ルールに対してユニットテストを行い、全体のフローに対して統合テストを行うことで行われる。
テストケースは以下の内容をカバーすべきである:
- ハッピーパス: 有効なデータはすべてのチェックを通過し、データストアに到達する。
- エッジケース: 範囲の境界にあるデータ(例:最小値および最大値)。
- 不正なデータ: 不正な型や予期しない文字を含むデータ。
- 欠損データ: 必須フィールドが欠けているデータ。
DFDが正確であれば、テスト結果は可視化されたフローと一致するべきである。図で予測されていない方法でテストケースが失敗した場合、DFDは更新されなければならない。この反復プロセスにより、ドキュメントがシステム動作の真実の反映を保つことができる。
構造化された検証に関する結論 📝
フローロジックを用いたシステム入力の検証は、セキュリティ要件をアーキテクチャの構造的要素に変換する。データフローダイアグラム内に検証ルールをマッピングすることで、チームはデータがどこでチェックされるか、エラーはどのように処理されるか、情報がシステム内でどのように移動するかを可視化できる。この明確さにより、曖昧さが減少し、設計者と開発者の間のコミュニケーションが向上し、最終的により安定したソフトウェアが得られる。意思決定ポイント、エラーフロー、セキュリティチェックの統合により、システムは外部世界の避けがたいノイズに対して堅牢な状態を保つことができる。
システムの複雑性が増すにつれ、構造化されたフローロジックへの依存はさらに重要になる。これは、時間の経過とともにデータ整合性を維持するためのブループリントを提供する。ここに示された原則に従うことで、アーキテクトは「何も信頼せず、すべてを検証する」パイプラインを構築でき、データエコシステムの持続可能性と信頼性を確保できる。