











La construction de systèmes logiciels fiables exige plus que la simple rédaction de code fonctionnel. Elle exige une compréhension claire du comportement du système dans diverses conditions. Les diagrammes d’états, souvent appelés simplement diagrammes d’état, fournissent le plan de ce comportement. Ils définissent les modes distincts qu’un système peut occuper ainsi que les règles régissant les transitions entre eux. Toutefois, à mesure que les systèmes gagnent en complexité, la probabilité d’erreurs logiques augmente. Le débogage de ces problèmes exige une approche structurée, une compréhension approfondie de la logique sous-jacente et une élimination méthodique des variables.
Ce guide expose les stratégies essentielles pour identifier et résoudre les erreurs logiques au sein des architectures basées sur les états. En comprenant l’anatomie des transitions d’état et les pièges courants, les ingénieurs peuvent maintenir l’intégrité du système sans avoir recours à des suppositions.
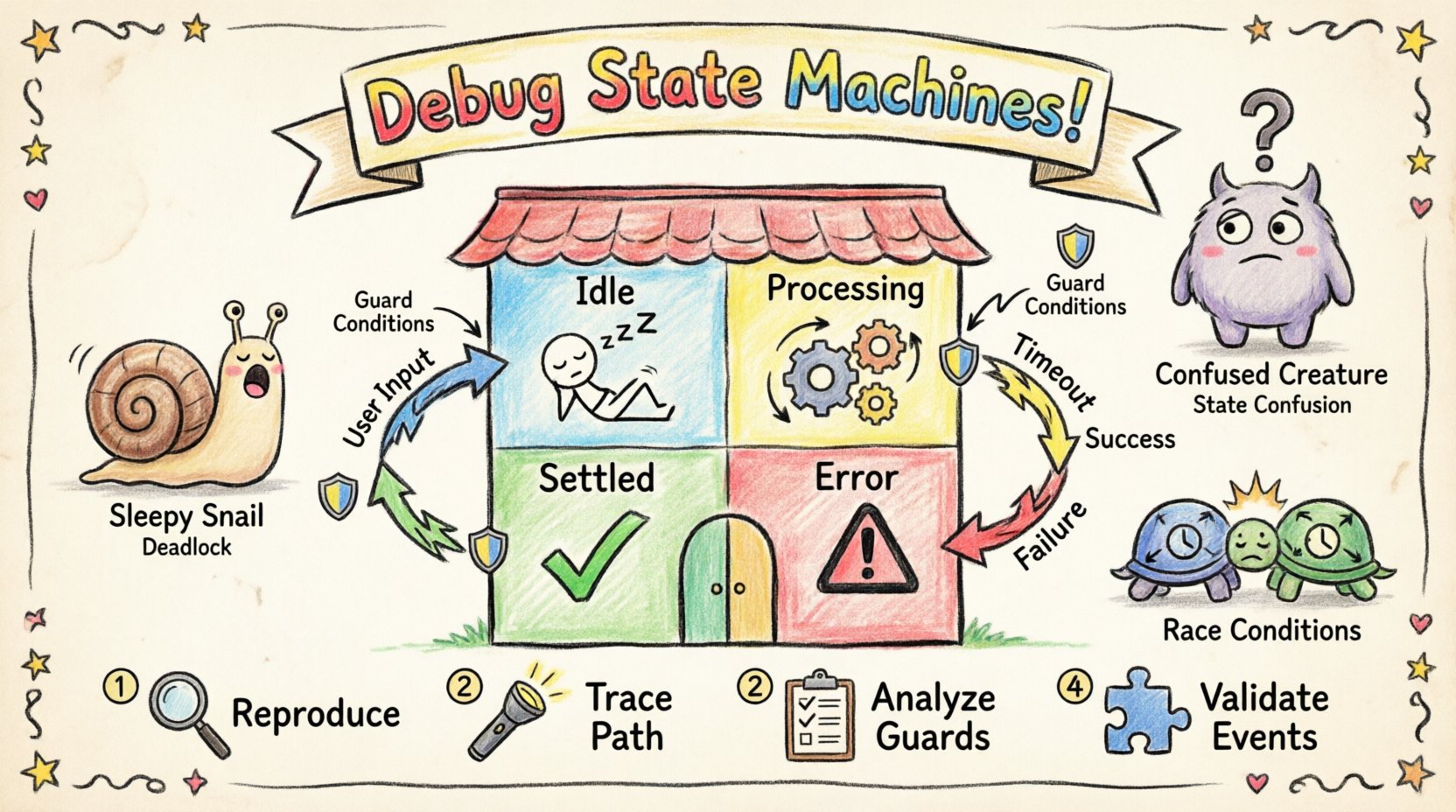
🔍 Comprendre l’anatomie d’une machine à états
Avant de procéder au dépannage, il est essentiel de comprendre les composants qui pilotent la machine à états. Un diagramme d’état n’est pas simplement une représentation visuelle ; il s’agit d’un contrat logique définissant le cycle de vie du système. Chaque élément remplit un rôle spécifique dans le contrôle du flux et des données.
- États : Modes ou conditions distincts dans lesquels le système peut exister. Des exemples incluent Inactif, En traitement, ou Erreur.
- Transitions : Les chemins reliant les états. Une transition a lieu lorsqu’un événement spécifique déclenche un changement d’un état à un autre.
- Événements : Signaux ou actions qui déclenchent des transitions. Ceux-ci peuvent être des actions internes ou des entrées externes.
- Conditions de garde : Conditions booléennes évaluées lors d’une transition. La transition n’a lieu que si la condition de garde est évaluée à vrai.
- Actions : Opérations effectuées lors de l’entrée, de la sortie ou pendant une transition. Celles-ci peuvent inclure la journalisation, la mise à jour des données ou le déclenchement de services externes.
- États initial/final : Le point de départ et le point de terminaison du cycle de vie.
Lors du débogage, il est crucial de vérifier que ces composants interagissent correctement. Une erreur logique provient souvent d’un désaccord entre le comportement attendu défini dans le diagramme et le comportement réel observé dans l’environnement d’exécution.
🚨 Erreurs logiques courantes et leurs symptômes
Les systèmes complexes souffrent fréquemment de certains types d’échecs logiques. Reconnaître les symptômes tôt peut épargner beaucoup de temps pendant le processus de débogage. Le tableau ci-dessous catégorise les problèmes courants, leurs symptômes observables et les causes probables.
| Type d’erreur | Symptôme | Cause racine |
|---|---|---|
| Transitions spuriées | Le système passe à un état inattendu sans déclencheur clair. | Conditions de garde manquantes ou gestionnaires d’événements chevauchants. |
| Bloquages | Le système s’arrête et ne répond pas aux entrées valides. | Aucune transition sortante depuis un état spécifique pour certains événements. |
| États inaccessibles | Certains états ne sont jamais atteints pendant un fonctionnement normal. | Chemins d’entrée incorrects ou logique qui contourne des états spécifiques. |
| Confusion d’état | Le système se comporte différemment dans le même état selon son historique. | Échec de réinitialisation du contexte ou de gestion incorrecte des états historiques. |
| Conditions de course concurrentes | Des actions en conflit se produisent simultanément dans des états parallèles. | Manque de synchronisation entre les sous-machines concurrentes. |
🧪 Méthodologie de débogage étape par étape
Résoudre les problèmes de machine à états nécessite un flux de travail rigoureux. Les corrections improvisées introduisent souvent de nouveaux bogues. Suivez cette approche systématique pour isoler et corriger les erreurs logiques.
1. Recréer le problème
Avant d’essayer une correction, vous devez reproduire de manière fiable l’erreur. Si le problème est intermittent, documentez la séquence des événements menant à l’échec.
- Identifiez l’entrée ou l’événement spécifique qui déclenche un comportement incorrect.
- Enregistrez l’état actuel du système avant que l’événement ne se produise.
- Enregistrez l’état dans lequel le système entre après l’événement.
- Vérifiez si le problème se produit de manière constante ou uniquement dans des conditions spécifiques (par exemple, des valeurs de données spécifiques).
2. Suivre le chemin d’exécution
Utilisez des mécanismes de journalisation pour suivre le chemin d’exécution. Chaque transition doit être enregistrée avec son contexte pertinent.
- Journalisation d’entrée/sortie :Journalisez chaque fois qu’un état est entré ou quitté.
- Journalisation de transition :Journalisez l’événement qui a déclenché la transition.
- Évaluation des conditions de garde :Journalisez si les conditions de garde ont réussi ou échoué, et pourquoi.
- Journalisation des actions :Journaliser lorsque les actions sont exécutées et leurs sorties.
Ces données créent une chronologie des événements. Comparez cette chronologie au diagramme d’état. Recherchez les incohérences là où le code s’écarte de la conception.
3. Analyser les conditions de garde
Les conditions de garde sont souvent à l’origine d’erreurs logiques. Une transition peut sembler disponible sur le diagramme, mais une condition cachée peut l’empêcher de se déclencher.
- Revoyez toutes les conditions de garde associées à la transition problématique.
- Vérifiez que les variables utilisées dans la condition de garde correspondent aux données disponibles au moment de l’événement.
- Vérifiez les effets secondaires lors de l’évaluation de la condition de garde qui pourraient modifier l’état de manière inattendue.
- Assurez-vous que les conditions de garde ne sont pas trop restrictives, bloquant des transitions valides.
4. Valider la gestion des événements
Les événements sont les catalyseurs du changement. Si un événement n’est pas correctement géré, le système peut l’ignorer ou le traiter dans l’état incorrect.
- Vérifiez que le nom de l’événement correspond exactement entre la source et la machine à états.
- Vérifiez que l’événement est envoyé à l’instance correcte de la machine à états.
- Assurez-vous que l’événement n’est pas consommé par un état parent alors qu’un état enfant devrait le gérer.
- Confirmez que la file d’événements traite les événements dans l’ordre attendu.
🔄 Gestion de la concurrence et des états parallèles
Les machines à états avancées utilisent souvent des états concurrents. Cela permet à plusieurs machines à états indépendantes de s’exécuter simultanément au sein d’un état composite. Bien que puissant, cela introduit une complexité concernant la synchronisation et le partage des données.
1. Points de synchronisation
Dans les environnements concurrents, les transitions doivent être synchronisées pour éviter les conditions de course. Une transition dans un état parallèle peut dépendre de la fin d’une transition dans un autre.
- Définissez des barrières de synchronisation claires là où les états parallèles doivent s’aligner.
- Utilisez des drapeaux ou des variables d’état pour indiquer la disponibilité des branches parallèles.
- Assurez-vous que les états finaux des branches parallèles sont atteints avant que l’état composite ne soit complété.
2. Intégrité des données partagées
Les états parallèles accèdent souvent à des ressources partagées. Si deux états modifient les mêmes données simultanément, une corruption peut survenir.
- Implémentez des mécanismes de verrouillage lors de l’accès aux variables d’état partagées.
- Utilisez des structures de données immuables lorsque cela est possible pour éviter les modifications accidentelles.
- Auditez toutes les fonctions d’action pour déterminer si elles modifient un état global ou partagé.
🛡️ Techniques de vérification et de validation
Le débogage est réactif ; la vérification est proactive. Mettre en œuvre des stratégies pour valider la machine à états avant le déploiement réduit la charge du dépannage.
1. Analyse statique
Les outils d’analyse statique peuvent analyser la définition du diagramme d’états sans exécuter le code. Ils peuvent identifier les problèmes structurels.
- Vérifiez les états inaccessibles.
- Identifiez les transitions qui ne peuvent pas être déclenchées par un événement.
- Vérifiez que tous les états ont des chemins de sortie valides.
- Assurez-vous que tous les événements sont traités (pas d’erreurs d’événements non gérés).
2. Vérification de modèle
La vérification de modèle consiste à vérifier mathématiquement que la machine à états satisfait des propriétés spécifiques. Cela est particulièrement utile pour les systèmes critiques pour la sécurité.
- Définissez des propriétés telles que « le système n’entre jamais dans un état de blocage ».
- Exécutez des algorithmes pour vérifier ces propriétés par rapport au graphe de transition d’états.
- Utilisez ces outils pour valider des scénarios de concurrence complexes.
3. Tests unitaires pour les machines à états
Chaque état et transition doit être testé indépendamment, lorsque cela est possible.
- Écrivez des tests qui placent le système dans un état spécifique et déclenchent un événement spécifique.
- Affirmez que le système passe à l’état suivant correct.
- Affirmez que les actions attendues sont déclenchées.
- Testez les conditions limites, telles que le déclenchement d’un événement dans un état où il ne devrait pas être autorisé.
📝 Documentation pour la maintenance future
Une machine à états difficile à comprendre est difficile à déboguer. Une documentation claire garantit que les ingénieurs futurs peuvent diagnostiquer efficacement sans avoir à reverse-ingénier le logique.
- Commentez le code :Ajoutez des commentaires en ligne expliquant les transitions complexes ou les conditions de garde non évidentes.
- Maintenez les diagrammes :Maintenez les diagrammes d’états visuels synchronisés avec le code. Un diagramme obsolète est une menace.
- Documentez les cas limites :Enregistrez les limitations connues ou les scénarios spécifiques que la machine gère différemment.
- Contrôle de version :Traitez les définitions d’états comme du code. Utilisez le contrôle de version pour suivre les modifications apportées à la logique au fil du temps.
⚙️ Scénario du monde réel : Le pipeline de traitement des paiements
Considérez un système de traitement des paiements. La machine à états gère le cycle de vie d’une transaction :Initié, Autorisé, Soldé, ou Échoué.
Imaginez un scénario où une transaction entre dans l’état Soldé mais la base de données indique qu’elle est toujours Autorisé. C’est une erreur classique d’incohérence d’état.
- Diagnostic : La transition de Autorisé à Soldé a été déclenchée, mais la logique de mise à jour d’état a échoué à valider le changement dans le stockage persistant.
- Impact : L’utilisateur voit un succès, mais le backend s’attend à ce que les fonds soient réservés.
- Solution : Mettez en place un wrapper de transaction qui garantit que la mise à jour d’état et la validation dans la base de données se produisent de manière atomique.
- Prévention : Ajoutez une tâche de reconciliation qui vérifie périodiquement l’état de la machine d’état par rapport à l’état de la base de données.
🔧 Outils avancés de dépannage
Bien que le traçage manuel soit efficace, certains outils peuvent accélérer le processus de débogage.
- Visualisateurs d’état interactifs : Des outils qui vous permettent de parcourir les états visuellement en temps réel.
- Aggrégateurs de journaux : Des systèmes de journalisation centralisés qui permettent de filtrer par ID d’état ou type d’événement.
- Protocoles de débogage : Interfaces qui permettent aux systèmes externes de demander l’état actuel de la machine sans la redémarrer.
- Environnements de simulation :Bacs à sable où vous pouvez rejouer des séquences d’événements pour reproduire les bogues en toute sécurité.
🧠 Charge cognitive et complexité des états
À mesure que le nombre d’états augmente, la charge cognitive nécessaire pour maintenir la logique croît de manière exponentielle. Cela est connu sous le nom de problème d’explosion des états.
- Modulariser :Diviser les machines à états grandes en sous-machines plus petites et gérables.
- Abstraire :Utiliser des états composites pour cacher la complexité à la logique de niveau supérieur.
- Limiter :Limitez strictement le nombre d’états concurrents afin de réduire la surcharge de synchronisation.
- Refactoriser :Revoyez régulièrement le diagramme d’états pour identifier les états redondants ou superposés.
🛑 Gestion des entrées imprévues
Les systèmes robustes doivent gérer les entrées qui ne sont pas définies dans le diagramme d’états. Cela est souvent appelé l’« état d’erreur ».
- Transitions par défaut :Définissez une transition générale pour les événements survenant dans des états imprévus.
- Journalisation :Enregistrez les événements imprévus avec une gravité élevée pour alerter les développeurs.
- Récupération :Assurez-vous que le système peut se remettre d’un état d’erreur, plutôt que de planter.
- Notification :Avertissez l’utilisateur ou le système de surveillance lorsqu’un événement imprévu se produit.
📊 Métriques pour l’état de santé de la machine à états
Pour maintenir un système sain, suivez des métriques spécifiques liées à la machine à états.
- Fréquence des transitions :Avec quelle fréquence des transitions spécifiques se produisent. Des changements soudains pourraient indiquer un bogue.
- Durée de l’état :Combien de temps le système reste-t-il dans un état spécifique. Des durées longues pourraient indiquer un blocage.
- Taux d’erreurs : Le pourcentage des événements qui entraînent des transitions d’erreur.
- Nombre de blocages : Le nombre de fois où le système entre dans un état sans transitions sortantes.
🚀 Conclusion sur l’intégrité du système
Maintenir l’intégrité d’une machine à états est un processus continu. Il exige de la vigilance, une documentation claire et une compréhension approfondie du flux logique. En suivant les méthodologies décrites ci-dessus, les ingénieurs peuvent diagnostiquer efficacement les erreurs logiques et garantir que les systèmes complexes se comportent de manière prévisible.
Souvenez-vous que l’objectif n’est pas seulement de corriger le bug immédiat, mais d’améliorer la robustesse globale de l’architecture. Une machine à états bien conçue est auto-documentée et résiliente aux changements. Investissez du temps dans la phase de conception pour réduire le coût du dépannage ultérieur.
Appliquez ces principes de façon cohérente. Revoyez régulièrement vos diagrammes. Testez vos transitions de manière approfondie. Avec une discipline rigoureuse, vous pouvez maîtriser la complexité et livrer un logiciel stable et fiable.