











Concevoir un système robuste exige plus que de simplement relier visuellement les composants ; il demande une vérification logique rigoureuse. Lors de la construction d’un diagramme de flux de données, la représentation visuelle du déplacement de l’information n’est valable que par la logique qui la sous-tend. Les erreurs commises à cette phase peuvent se propager et entraîner des défaillances opérationnelles importantes ultérieurement. Ce guide vous permet d’approfondir la détection et la correction des erreurs logiques dans les conceptions de flux afin de garantir l’intégrité des données et la fiabilité des processus. 🧠
Comprendre les fondements de la conception des flux 🏗️
Avant de détecter les erreurs, il faut comprendre l’architecture d’un diagramme de flux de données standard. Ces diagrammes cartographient le déplacement des données à travers un système, en mettant en évidence les entités externes, les processus, les magasins de données et les flux qui les relient. Le but principal est de visualiser comment l’information entre dans un système, s’y transforme et en sort. Lorsque la logique régissant ces mouvements est faussée, l’architecture du système résultant devient instable.
Les erreurs logiques diffèrent des erreurs de syntaxe. Une erreur de syntaxe empêche le diagramme d’être dessiné ou validé techniquement. Une erreur logique signifie que le diagramme est correctement dessiné, mais représente une réalité impossible ou inefficace. Par exemple, un processus pourrait être représenté comme recevant une entrée sans sortie définie, ou les données pourraient apparaître de nulle part. Ces anomalies perturbent le flux logique de l’information. ⚙️
Il est essentiel que le diagramme reflète fidèlement les règles métier et les lois de conservation des données. Chaque donnée entrant dans un processus doit être soit transformée, soit stockée, soit transmise. Rien ne doit être créé ou détruit sans mécanisme défini. Ce principe est la colonne vertébrale de la cohérence logique dans la conception des flux.
Catégories d’erreurs logiques à détecter 🔍
Les erreurs logiques se manifestent sous diverses formes dans une conception de flux. Reconnaître ces catégories facilite une revue systématique. Ci-dessous figurent les principaux types d’incohérences logiques qui apparaissent fréquemment lors de la phase de conception.
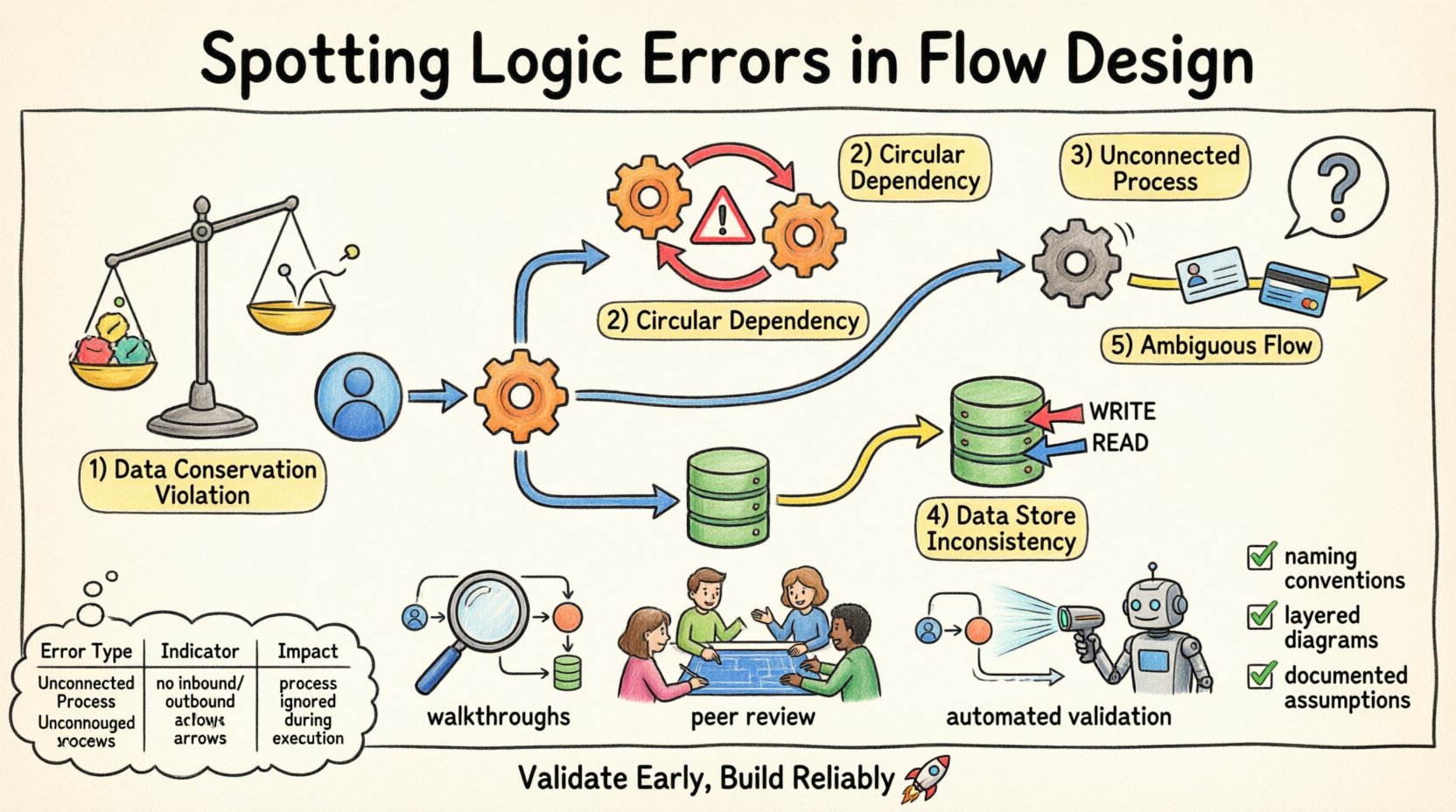
1. Violations de la conservation des données 📉
La loi de conservation des données stipule qu’une donnée ne peut être ni créée ni détruite au sein d’un processus. Si un diagramme de flux montre des données émergeant d’un processus sans source claire, cela viole cette loi. À l’inverse, si des données entrent dans un processus et disparaissent sans être stockées ou sorties, elles sont perdues. Cela se produit souvent lorsque le concepteur oublie de dessiner une flèche de sortie.
Par exemple, si un processus de commande client reçoit les détails de la commande mais ne produit que reçu de confirmation, les informations de paiement sont absentes. Cela indique un manque dans la logique. Le système ne peut fonctionner sans tenir compte de toutes les entrées et sorties.
2. Dépendances circulaires 🔄
Les dépendances circulaires surviennent lorsque le Processus A alimente le Processus B, qui à son tour alimente à nouveau le Processus A sans étape intermédiaire. Dans un diagramme statique, cela ressemble à une boucle. Bien que les boucles existent dans les systèmes basés sur le temps, dans une conception de flux logique, elles indiquent souvent un blocage ou une récursion infinie que le système ne peut résoudre.
Identifier ces cas nécessite de suivre le parcours des données. Si un processus dépend de la sortie d’un autre processus qui attend lui-même le premier processus, le flux s’arrête. Il s’agit d’une erreur logique critique qui bloque l’exécution du système.
3. Processus non connectés 🚫
Un processus non connecté est un processus qui n’a pas de flux d’entrée de données. Sans entrée, un processus ne peut pas s’exécuter. Il constitue une île logique. De même, un processus sans flux de sortie ne contribue pas à la sortie globale du système. Bien que des processus internes puissent exister sans sortie externe directe, ils doivent finalement alimenter une chaîne aboutissant à un magasin de données ou à une entité externe.
Les processus isolés suggèrent une conception incomplète. Ils consomment des ressources sans apporter de valeur. Leur détection nécessite une analyse de connectivité de chaque nœud du diagramme.
4. Incohérences des magasins de données 🗄️
Les magasins de données représentent des informations persistantes. Des erreurs logiques surviennent lorsque des processus lisent ou écrivent dans un magasin de données sans autorisation ou contexte appropriés. Par exemple, un processus pourrait mettre à jour un enregistrement sans vérifier si l’utilisateur dispose des autorisations nécessaires, ou un processus pourrait lire des données qui ne sont écrites que par un autre processus qui n’a pas encore été exécuté.
Un autre problème courant est qu’un magasin de données soit lu et écrit simultanément par des processus différents sans synchronisation. Cela crée des conditions de course dans le modèle logique. Le diagramme doit montrer clairement les chemins d’écriture et de lecture pour éviter toute ambiguïté.
5. Flux de données ambigus 🌫️
Les flux de données doivent être nommés et décrits clairement. Un flux ambigu est celui qui transporte plusieurs types de données sans distinction. Si une seule flèche représente à la fois « ID utilisateur » et « Numéro de carte de crédit », la logique est faussée, car ces éléments de données ont des exigences de sécurité et de traitement différentes.
Séparer ces flux garantit que chaque information est traitée selon ses règles spécifiques. L’ambiguïté entraîne des vulnérabilités de sécurité et des erreurs de traitement en aval.
| Type d’erreur | Indicateur | Impact |
|---|---|---|
| Conservation des données | Données apparaissent/disparaissent | Perte ou corruption des données |
| Dépendance circulaire | Processus A → Processus B → Processus A | Bloquage du système |
| Processus non connecté | Pas de flèches d’entrée ou de sortie | Perte de ressources |
| Incohérence du magasin de données | Lecture/écriture non contrôlée | Problèmes d’intégrité des données |
| Flux ambigus | Types de données mixtes dans un même flux | Risques de sécurité |
Méthodologies de détection 🛡️
Une fois que les types d’erreurs sont connus, la prochaine étape consiste à établir une méthodologie pour les détecter. Une revue passive est souvent insuffisante. Une interrogation active du diagramme est nécessaire.
Parcours étape par étape 🚶
Effectuez un parcours mental du diagramme. Commencez par une entité externe et suivez les données à travers chaque processus jusqu’à une base de données ou une autre entité. Posez des questions à chaque nœud. Ce processus dispose-t-il de suffisamment d’entrées pour fonctionner ? Produit-il la sortie attendue ? Si je devais exécuter cette logique, où iraient les données ?
Ce suivi manuel oblige le concepteur à visualiser le déplacement des données de manière dynamique. Il révèle des lacunes que la visualisation statique manque. Si le parcours s’arrête à un nœud, c’est probablement là que se trouve l’erreur logique.
Sessions de revue par les pairs 👥
Une autre personne examinant le diagramme apporte une perspective fraîche. Un relecteur peut détecter des erreurs auxquelles le concepteur est devenu aveugle à cause de la familiarité. Encouragez les relecteurs à remettre en question les hypothèses. Demandez-leur de repérer le flux de données qui semble inutile ou manquant.
Des sessions de revue structurées réduisent les risques d’omission. Une liste de contrôle doit être utilisée lors de ces revues pour s’assurer que toutes les catégories d’erreurs sont couvertes.
Règles de validation automatisées 🤖
Bien que le logiciel spécifique ne soit pas mentionné ici, des outils de validation logique peuvent analyser les diagrammes pour détecter des erreurs structurelles. Ces outils peuvent signaler des nœuds non connectés, des bases de données manquantes ou des références circulaires. Ils agissent comme une première ligne de défense contre les incohérences logiques fondamentales.
L’utilisation de contrôles automatisés permet à l’équipe de se concentrer sur la logique de haut niveau plutôt que sur la syntaxe structurelle. Cela garantit que la base est solide avant d’ajouter de la complexité.
Le coût de la négligence logique 💸
Pourquoi cela importe-t-il ? Les erreurs logiques lors de la phase de conception sont les plus coûteuses à corriger. Si un défaut logique est découvert pendant le codage, cela nécessite de réécrire des modules. Si une erreur est détectée après le déploiement, cela exige des correctifs et potentiellement une migration de données.
Prenons le scénario où un flux de données manque une étape de validation. Cela permet à des données non valides d’entrer dans le système. Plus tard, les rapports générés à partir de ces données sont inexactes. L’entreprise prend des décisions sur la base d’informations erronées. Le coût de nettoyage de ces données et de la restauration de la confiance est bien supérieur au coût de la correction du diagramme initialement.
En outre, les erreurs logiques peuvent entraîner des violations de sécurité. Si un flux permet à des données de contourner une vérification de sécurité, des informations sensibles sont exposées. Cela peut entraîner des violations de conformité et des conséquences juridiques. Prévenir ces erreurs ne concerne pas seulement l’efficacité ; c’est une question de gestion des risques.
Stratégies de prévention 🛡️
La prévention est meilleure que la détection. Mettre en place des normes et des pratiques lors de la création du schéma de flux réduit la probabilité que des erreurs surviennent dès le départ.
Conventions de nommage standardisées 🏷️
Établissez des règles strictes de nommage pour les processus, les bases de données et les flux. Un nom de processus doit être une paire verbe-nom, par exemple « Valider la commande ». Un nom de flux doit décrire les données, par exemple « Détails de la commande ». Cette cohérence facilite la détection des anomalies. Si un flux est nommé « Données », il est probablement trop vague et doit être examiné attentivement.
Un nommage cohérent facilite également la validation automatisée. Les scripts peuvent analyser les noms pour vérifier la conformité avec les structures logiques.
Diagrammes en couches 📑
Décomposez les systèmes complexes en plusieurs niveaux. Le niveau 0 montre les processus de haut niveau. Le niveau 1 décompose ces processus en sous-processus. Cette approche hiérarchique empêche le diagramme de devenir encombré. Le désordre cache les erreurs logiques.
En zoomant sur des zones spécifiques, le concepteur peut se concentrer sur la logique de ce sous-système particulier sans perdre de vue l’ensemble. Les erreurs sont plus faciles à détecter dans des vues ciblées.
Documentation des hypothèses 📝
Chaque diagramme comporte des hypothèses. Documentez-les explicitement. Si un processus suppose que les données sont toujours présentes, indiquez cette hypothèse. Si un flux implique un délai temporel, notez-le. Cette documentation fournit un contexte aux relecteurs. Elle explique pourquoi certaines décisions logiques ont été prises.
Lorsque les hypothèses sont documentées, elles peuvent être remises en question et validées par rapport aux exigences métiers. Cela réduit la probabilité que des erreurs logiques cachées persistent dans le design final.
Liste de contrôle de validation ✅
Avant de finaliser un schéma de flux, passez en revue cette liste de contrôle. Elle couvre les zones critiques où les erreurs logiques se cachent généralement.
- Complétude des entrées :Chaque processus dispose-t-il d’au moins un flux entrant ?
- Complétude des sorties :Chaque processus dispose-t-il d’au moins un flux sortant ?
- Équilibre des données :Le volume des données est-il conservé à travers les processus ?
- Pas de cul-de-sac : Y a-t-il des processus qui ne mènent pas à un magasin de données ou à une entité externe ?
- Nomination claire : Tous les flux et les processus sont-ils nommés de manière descriptive ?
- Sécurité : Les flux de données sensibles sont-ils clairement marqués et protégés logiquement ?
- Sensibilité temporelle : Les dépendances de temporisation sont-elles clairement définies ?
- Consistance : Les magasins de données correspondent-ils aux données utilisées dans les processus ?
Affiner la conception 🎯
Une fois les erreurs détectées, le processus d’affinement commence. Cela consiste à modifier le diagramme pour corriger la logique. Il ne s’agit pas toujours d’éliminer des éléments ; parfois, il s’agit d’ajouter des connexions manquantes.
Par exemple, si un processus n’a pas de sortie, déterminez où les données doivent aller. Ajoutez la flèche manquante vers le magasin de données ou l’entité appropriée. Si une dépendance circulaire existe, introduisez un tampon ou une file d’attente pour briser la boucle. Cela peut signifier ajouter une étape intermédiaire à la conception.
L’affinement est itératif. Après avoir apporté des modifications, réexécutez le parcours et la liste de contrôle. Assurez-vous que la nouvelle logique résiste à une analyse rigoureuse. Ne supposez pas que la correction est terminée tant que le diagramme n’a pas passé toutes les étapes de validation.
Réflexions finales sur l’intégrité logique 💡
L’intégrité d’une conception de flux détermine le succès du système. Les erreurs logiques sont subtiles mais destructrices. Elles compromettent la fiabilité de toute l’architecture. En appliquant des méthodes rigoureuses de détection et des stratégies de prévention, les concepteurs peuvent créer des systèmes qui fonctionnent comme prévu.
L’attention aux détails pendant la phase de conception permet d’économiser du temps, de l’argent et des efforts en aval. Un diagramme bien validé est un plan directeur pour un système stable. Prioriser la cohérence logique garantit que les données circulent correctement, de manière sécurisée et efficace au sein de l’organisation. Cette approche conduit à des systèmes qui sont non seulement fonctionnels, mais aussi résilients face aux changements. 🚀
Restez concentré sur la clarté et la justesse. Chaque flèche compte. Chaque nœud a son importance. En respectant ces principes, la conception de flux devient un atout fiable pour l’équipe de développement.