
Les diagrammes de flux de données (DFD) constituent une pierre angulaire de l’analyse et de la conception des systèmes. Ils offrent une représentation visuelle du déplacement de l’information à travers un système, en mettant en évidence les interactions entre les entités externes, les processus internes, les entrepôts de données et les flux qui les relient. Bien que le concept soit simple, le niveau de détail de ces diagrammes varie considérablement selon les exigences. Deux étapes cruciales dans cette hiérarchie sont les DFD Niveau 0 et Niveau 1. Comprendre la distinction entre ces deux niveaux est essentiel pour les architectes, les analystes et les parties prenantes qui doivent communiquer la logique du système sans se perdre dans une complexité inutile.
Ce guide explore les différences structurelles, les cas d’utilisation et les bonnes pratiques pour créer des diagrammes Niveau 0 et Niveau 1. Nous examinerons comment passer d’une vue contextuelle de haut niveau à une décomposition fonctionnelle détaillée, en assurant clarté et précision dans la documentation de votre système.
🧭 Qu’est-ce qu’un diagramme de flux de données Niveau 0 ?
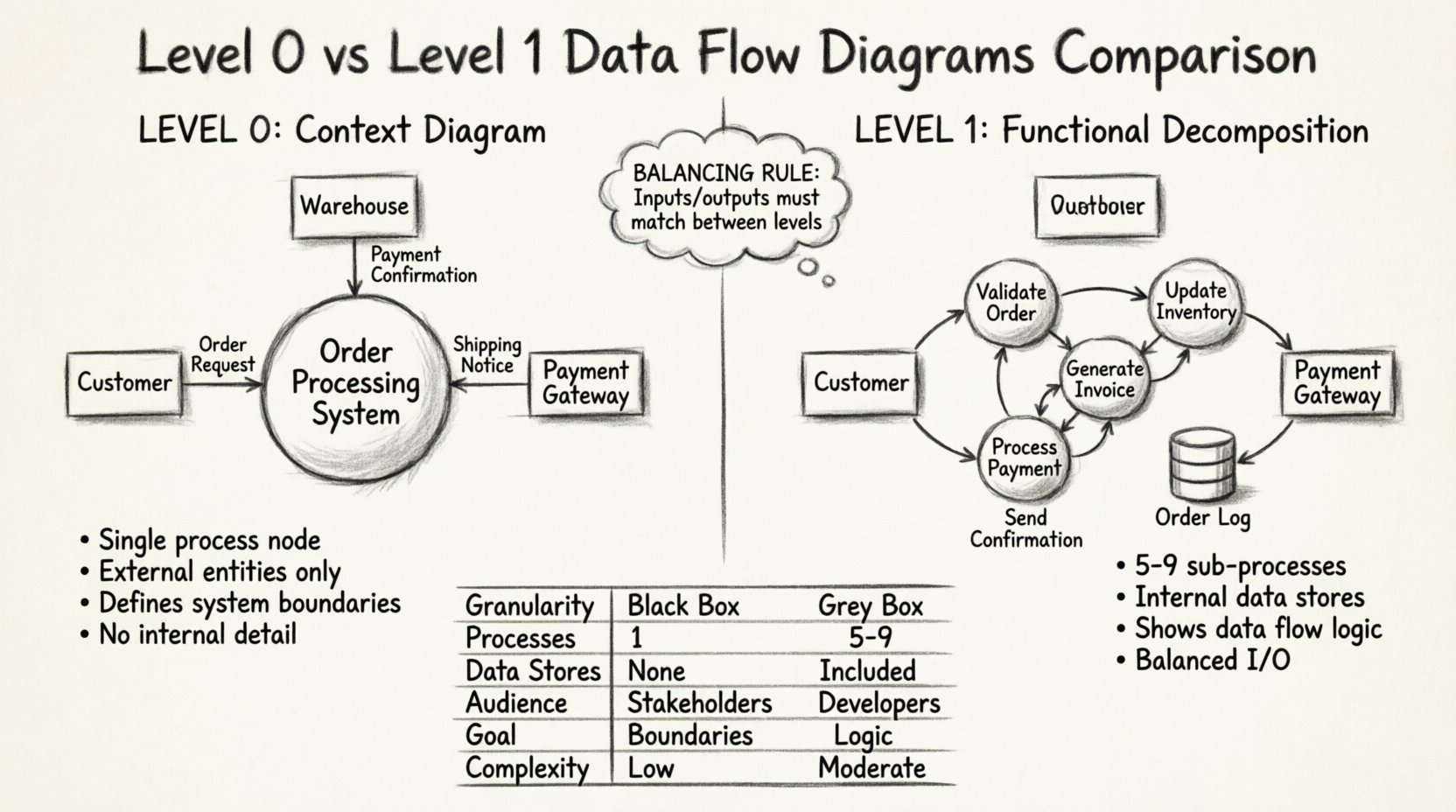
Un DFD Niveau 0, souvent appelé le Diagramme de contexte, représente le système comme un seul processus monolithique. C’est le niveau le plus élevé d’abstraction dans la hiérarchie des DFD. L’objectif principal ici est de définir les limites du système et de montrer comment il interagit avec le monde extérieur.
Caractéristiques principales
- Nœud de processus unique : L’ensemble du système est représenté par un seul cercle ou un rectangle arrondi, généralement étiqueté avec le nom du système.
- Entités externes : Ce sont des sources ou des destinations de données situées en dehors des limites du système. Par exemple, des utilisateurs, d’autres systèmes ou des organismes régulateurs.
- Flux de données : Les flèches indiquent les entrées et sorties de données entre les entités externes et le système.
- Pas de détail interne : Aucun entrepôt de données, sous-processus ou mouvement interne de données n’est représenté.
Ce diagramme répond à la question : « Qu’est-ce que le système fait, et avec qui interagit-il ? » Il s’agit généralement du premier artefact créé pendant la phase de collecte des exigences. Il permet de partager une compréhension commune entre les parties prenantes concernant le périmètre du projet avant de s’immerger dans les détails techniques.
Structure visuelle du Niveau 0
Imaginez un grand cercle au centre de la page étiqueté « Système de traitement des commandes ». Autour de ce cercle se trouvent des rectangles représentant des entités externes, telles que « Client », « Entrepôt » et « Passerelle de paiement ». Des lignes relient ces rectangles au cercle central, étiquetées avec les données échangées, comme « Demande de commande » ou « Confirmation de paiement ». Cette simplicité garantit que les parties prenantes non techniques peuvent rapidement comprendre le but du système.
⚙️ Qu’est-ce qu’un diagramme de flux de données Niveau 1 ?
Un DFD Niveau 1 s’appuie sur le diagramme Niveau 0 en décomposant le processus unique du système en sous-processus majeurs. Il révèle la logique interne du système sans entrer dans les détails minutieux. Ce niveau comble le fossé entre le contexte de haut niveau et les spécifications de conception détaillées.
Caractéristiques principales
- Processus décomposés : Le processus unique du Niveau 0 est décomposé en 5 à 9 sous-processus majeurs. Ce nombre est une recommandation pour préserver la lisibilité.
- Entrepôts de données internes : Ce niveau introduit des répertoires où les données sont stockées, tels que des bases de données, des fichiers ou des files d’attente.
- Flux de données affinés : Les flèches montrent désormais comment les données circulent entre les sous-processus et les entrepôts de données.
- Entrées et sorties équilibrées Les entrées et sorties du processus de niveau 0 doivent correspondre aux entrées et sorties agrégées des sous-processus de niveau 1.
Ce diagramme répond à la question : « Comment le système réalise-t-il sa fonction ? » Il est crucial pour les développeurs et les architectes système qui doivent comprendre le flux d’information afin de construire l’architecture sous-jacente.
Structure visuelle du niveau 1
En utilisant l’exemple précédent, le cercle « Système de traitement des commandes » est remplacé par une collection de cercles plus petits. L’un pourrait être « Valider la commande », un autre « Mettre à jour l’inventaire », et un troisième « Générer une facture ». Ces cercles sont reliés par des flèches indiquant le déplacement des données entre eux. En outre, une forme cylindrique pourrait apparaître, représentant une « Base de données clients » ou un « Journal des commandes ». Cette structure permet à l’équipe de visualiser les dépendances et les exigences de conservation des données.
🆚 Comparaison : niveau 0 vs niveau 1
Pour clarifier les différences, nous pouvons comparer ces deux niveaux selon plusieurs dimensions. Ce tableau met en évidence les différences structurelles et fonctionnelles.
| Fonctionnalité | Niveau 0 (Diagramme de contexte) | Niveau 1 (Décomposition fonctionnelle) |
|---|---|---|
| Granularité | Vue d’ensemble du système (boîte noire) | Modules fonctionnels principaux (boîte grise) |
| Nombre de processus | Exactement 1 | De 5 à 9 sous-processus principaux |
| Stockages de données | Aucun affiché | Explicitement inclus |
| Public cible | Intervenants, gestion, utilisateurs | Développeurs, architectes système, analystes |
| Objectif principal | Définir les limites du système | Définir la logique et le flux internes |
| Complexité | Faible | Modérée |
🔄 Le concept d’équilibre
Une règle fondamentale lors du passage du niveau 0 au niveau 1 est l’équilibre. Les entrées et sorties entrant et sortant du processus au niveau 0 doivent être identiques aux entrées et sorties entrant et sortant des sous-processus au niveau 1 combinés. Cela garantit qu’aucune donnée n’est créée ou détruite au cours du processus de décomposition.
Par exemple, si le niveau 0 montre une entrée de « Données client » entrant dans le système, le niveau 1 doit montrer que « Données client » s’écoule vers au moins un des sous-processus. Si le niveau 0 montre une sortie de « Reçu » quittant le système, le niveau 1 doit montrer un sous-processus générant des données « Reçu ». Le fait de ne pas maintenir cet équilibre indique une erreur dans l’analyse ou un composant manquant dans la conception.
🛠 Meilleures pratiques pour la conception
La création de DFD efficaces exige de la discipline et le respect de conventions spécifiques. Suivre ces directives aide à maintenir la clarté et à éviter toute confusion.
1. Conventions de nommage
Les processus doivent être nommés selon une structure verbe-nom (par exemple, « Calculer la taxe » plutôt que « Taxe »). Les flux de données doivent être nommés avec des expressions nominales indiquant leur contenu (par exemple, « Détails de la facture » plutôt que « Facture »). Les entités externes doivent être nommées clairement pour refléter l’acteur ou le système fournissant les données.
2. Éviter les croisements
Le disposition du diagramme doit minimiser les croisements des lignes de flux de données. Les lignes qui se croisent créent un bruit visuel et rendent difficile le suivi du chemin de l’information. Si des croisements sont inévitables, assurez-vous qu’ils sont distincts et clairement étiquetés.
3. Cohérence des magasins de données
Assurez-vous que les magasins de données sont étiquetés de manière cohérente sur tous les diagrammes. Une base de données nommée « Customer DB » au niveau 1 ne doit pas être renommée « Table utilisateur » au niveau 2. La cohérence facilite la navigation et la compréhension à travers les différents niveaux de la hiérarchie.
4. Limiter les sous-processus
Bien que le niveau 1 doive être détaillé, il ne doit pas être exhaustif. Si un seul sous-processus contient trop de logique, il peut nécessiter sa propre décomposition au niveau 2. Toutefois, le niveau 1 doit généralement rester dans une portée gérable afin d’éviter de surcharger le lecteur.
📈 Quand utiliser chaque niveau
Le choix du niveau approprié dépend de la phase du projet et du public ciblé.
Utilisez le niveau 0 pour :
- Phase de lancement du projet : Pour établir rapidement le périmètre et les limites.
- Résumés pour les décideurs : Pour fournir aux dirigeants non techniques une vue d’ensemble de haut niveau.
- Définition des interfaces : Pour clarifier les points de connexion du système avec les systèmes externes.
Utilisez le niveau 1 pour :
- Conception du système : Pour guider l’équipe de développement sur la logique interne.
- Planification de l’intégration : Pour identifier les emplacements des magasins de données et des flux internes.
- Stratégie de test : Pour définir les cas de test en fonction des chemins de processus et des transformations de données.
🔍 Défis courants et solutions
La création de ces diagrammes soulève souvent des défis spécifiques. Être conscient de ces problèmes aide à produire des artefacts précis.
Problème : Stockages de données manquants
Les analystes oublient parfois d’inclure des stockages de données dans les diagrammes de niveau 1, en supposant que les données circulent directement entre les processus. Toutefois, la plupart des systèmes nécessitent une persistance. Assurez-vous d’identifier où les données sont sauvegardées entre les transactions.
Problème : Flux de données fantômes
Un flux de données fantôme est une flèche qui ne pointe nulle part ou ne provient de nulle part. Chaque flèche doit commencer par une source (Processus, Entité ou Stockage) et se terminer à une destination. Vérifiez votre diagramme pour vous assurer que toutes les lignes sont correctement ancrées.
Problème : Surcomplexité
Essayer de montrer chaque étape individuelle au niveau 1 peut entraîner un diagramme encombré. Si le diagramme de niveau 1 devient illisible, envisagez de diviser le système en sous-systèmes logiques et de créer des diagrammes de niveau 1 séparés pour chacun, plutôt que d’un seul diagramme massif.
🔗 Passage aux niveaux supérieurs
Une fois le diagramme de niveau 1 terminé, il sert de parent aux diagrammes de niveau 2. Chaque sous-processus du niveau 1 peut être décomposé davantage. Ce processus récursif se poursuit jusqu’à ce que les processus soient suffisamment simples pour être implémentés directement sous forme de code ou de configuration. Le diagramme de niveau 1 constitue l’étape clé qui garantit que la stratégie de décomposition est solide avant de s’immerger dans les détails spécifiques des algorithmes ou des schémas de base de données.
📝 Résumé des différences
Les diagrammes de flux de données de niveau 0 et de niveau 1 remplissent des rôles distincts mais complémentaires dans l’analyse des systèmes. Le niveau 0 définit le périmètre du système et sa relation avec l’environnement externe. Le niveau 1 soulève le voile pour révéler les composants fonctionnels principaux et la gestion interne des données. Ensemble, ils forment une vue en couches qui soutient à la fois la planification stratégique et l’exécution tactique.
En respectant les principes d’équilibre, de nomenclature cohérente et de granularité appropriée, les équipes peuvent tirer parti de ces diagrammes pour réduire l’ambiguïté, aligner les attentes et construire des systèmes robustes. Que vous soyez en train de documenter une application héritée ou de concevoir une nouvelle architecture, maîtriser la distinction entre ces niveaux garantit une communication claire et un modélisation efficace des systèmes.