






Les diagrammes de flux de données (DFD) servent de plan directeur pour les systèmes d’information. Ils cartographient le déplacement des données entre les processus, les entrepôts de données, les entités externes et les données elles-mêmes. Un diagramme bien conçu fait plus que montrer où vont les données ; il révèle la logique, l’intégrité et la sécurité de l’architecture du système. Cet article examine trois scénarios distincts pour illustrer comment une modélisation rigoureuse conduit à des systèmes stables et maintenables.
🗺️ Comprendre les composants fondamentaux
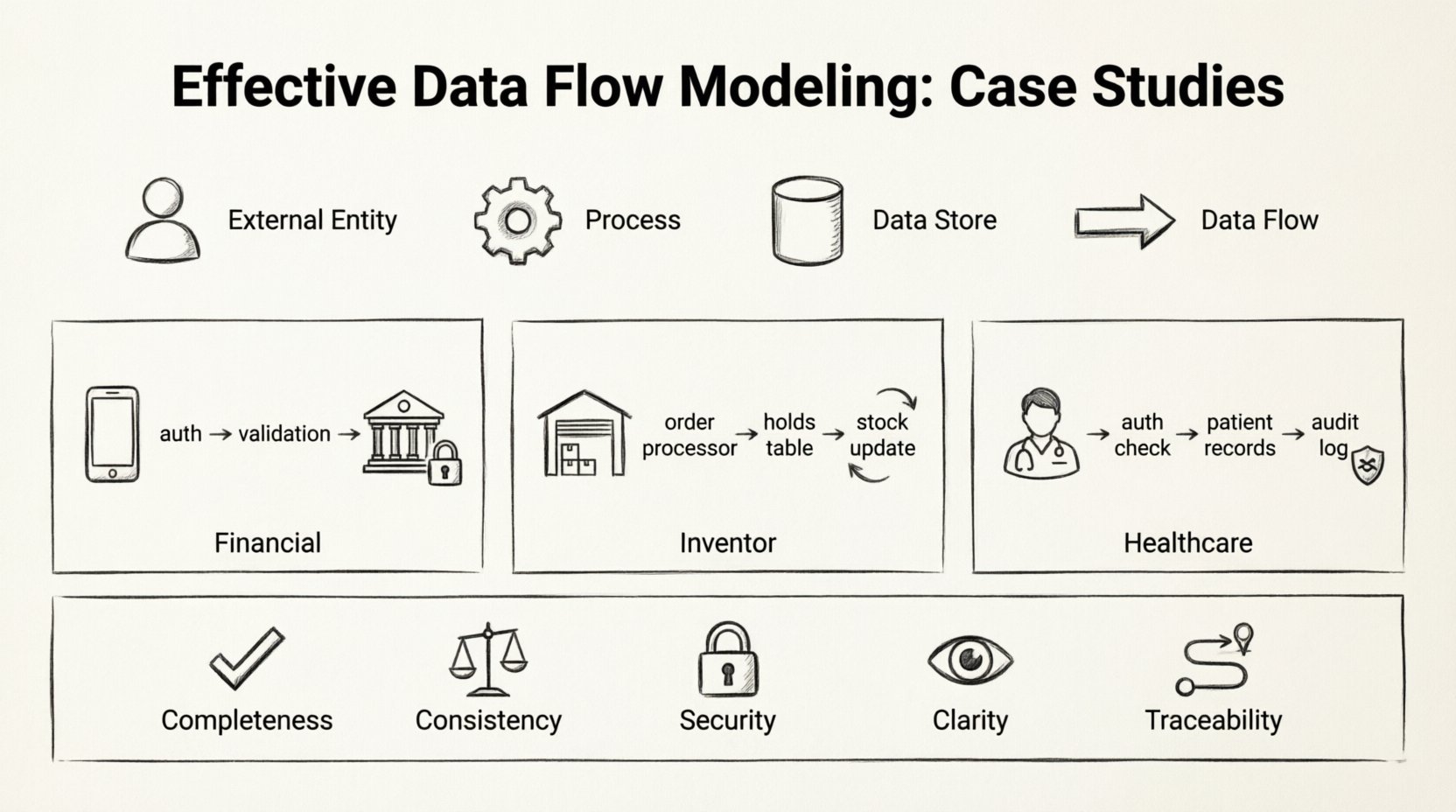
Avant de s’immerger dans des implémentations spécifiques, il est essentiel de définir les éléments standards impliqués dans tout modèle de flux de données. Ces composants restent constants, quelle que soit l’industrie ou la complexité du système.
- Entités externes :Sources ou destinations de données situées en dehors de la frontière du système. Il peut s’agir d’utilisateurs, d’autres systèmes ou d’organismes régulateurs.
- Processus :Transformations qui convertissent les données d’entrée en données de sortie. Chaque processus doit avoir au moins une entrée et une sortie.
- Entrepôts de données :Emplacements où les données sont conservées pour une utilisation ultérieure. Cela inclut les bases de données, les systèmes de fichiers ou les archives physiques.
- Flux de données :Les flèches reliant les composants, indiquant la direction et le contenu du déplacement des données.
La précision dans la représentation de ces éléments est cruciale. Une étiquette erronée, par exemple, d’un entrepôt de données comme un processus, peut entraîner une confusion quant à l’emplacement où les données sont persistées par rapport à celui où elles sont transformées.
🏦 Étude de cas 1 : Traitement des transactions financières
Le secteur financier exige une grande précision concernant l’intégrité et la sécurité des données. Dans ce scénario, nous examinons un système conçu pour traiter les demandes de paiement provenant d’une application mobile vers un noyau bancaire.
🔍 Contexte du système
L’objectif principal est de garantir que l’argent ne circule que lorsque des conditions spécifiques sont remplies. Le système doit valider les fonds, vérifier l’identité de l’utilisateur et enregistrer la transaction à des fins d’audit.
🔄 Découpage du flux de données
Le processus de modélisation a commencé par un diagramme de niveau 0, offrant une vue d’ensemble du système. Celui-ci a révélé trois processus principaux :Authentification, Validation :, et Enregistrement.
- Authentification :Lorsqu’un utilisateur initie un transfert, ses identifiants sont envoyés au service de sécurité. Le système vérifie l’état de l’utilisateur par rapport à l’entrepôt Utilisateurs actifsd’entrepôt de données.
- Validation : Une fois authentifié, la requête passe au processus de validation. Ici, le système vérifie le Soldes des comptes magasin pour s’assurer de fonds suffisants. Il vérifie également le Limites des transactions tableau.
- Enregistrement : Si la validation réussit, la transaction est enregistrée dans le Journal des transactions magasin de données. Les Soldes des comptes sont mis à jour, et un signal de confirmation est renvoyé à l’utilisateur.
Une décision cruciale dans ce modèle était la séparation du processus de Validation et Enregistrement processus. Les fusionner créerait un point de défaillance unique. En les maintenant distincts, le système peut annuler l’état de validation sans corrompre le journal permanent en cas d’interruption réseau.
📊 Cartographie des composants
| Composant | Type | Rôle dans le système |
|---|---|---|
| Application mobile | Entité externe | Initie la requête et reçoit la confirmation. |
| Service de sécurité | Processus | Vérifie les identifiants par rapport au hachage stocké. |
| Soldes des comptes | Magasin de données | Lit les fonds actuels et écrit les nouveaux totaux. |
| Journal des transactions | Magasin de données | Enregistrement immuable de tous les mouvements. |
📦 Étude de cas 2 : Système de gestion des stocks
Les systèmes de gestion des stocks nécessitent une synchronisation entre plusieurs emplacements. Le défi ici ne consiste pas seulement à déplacer les données, mais à garantir que la représentation du stock physique corresponde au registre numérique en temps réel.
🔍 Contexte du système
Ce système relie un terminal de gestion de stock à un portail de vente en ligne. Les données circulent dans les deux sens : les ventes réduisent le stock, et les livraisons entrantes l’augmentent. Le modèle doit gérer la concurrence afin d’éviter les ventes excessives.
🔄 Découpage du flux de données
Le diagramme de niveau 1 a révélé un réseau complexe d’interactions impliquant le Processus de commande et le Contrôleur de stock.
Lorsqu’une commande est passée :
- Le Processus de commande vérifie le Base de données des stocks.
- Si le stock est disponible, un Jetons de réservation est créé et stocké dans une table temporaire Table des réservations.
- La commande est confirmée au client.
- Un processus distinct, Réconciliation des stocks, s’exécute périodiquement pour supprimer les réservations expirées et mettre à jour la Base de données des stocks.
Cette approche empêche le système de verrouiller toute la base de données à chaque clic. L’utilisation d’une table temporaire Table des réservations permet au système de gérer les conflits sans bloquer les autres utilisateurs dans leur visualisation des niveaux de stock.
📊 Gestion de la concurrence
| Scénario | Action du flux de données | Résultat |
|---|---|---|
| Utilisateur unique | Vérifier le stock → Réserver → Confirmer | Succès |
| Deux utilisateurs (même article) | Utilisateur A réserve → Utilisateur B vérifie (stock faible) | L’utilisateur B voit le comptage mis à jour |
| Délai d’attente de réservation | Table des réservations → Processus de nettoyage | Le stock est retourné au pool |
Le modèle met en évidence l’importance du Processus de nettoyage. Sans cela, le Table des réservations croîtrait indéfiniment, consommant de la mémoire et ralentissant les requêtes.
🏥 Étude de cas 3 : Dossiers patients en santé
La modélisation des données de santé privilégie la confidentialité et le contrôle d’accès. Le flux d’information doit être strictement régulé en fonction du rôle de l’utilisateur et de la sensibilité des données.
🔍 Contexte du système
Ce système gère l’historique des patients pour un réseau de cliniques. Les données incluent l’identification personnelle, l’historique médical et les résultats d’analyses. Le modèle doit garantir que seules les personnes autorisées peuvent consulter des dossiers spécifiques.
🔄 Découpage du flux de données
Le diagramme de flux de données de ce système introduit le concept de Contrôle d’accès comme une couche de processus distincte. Les données ne circulent pas directement du dossier du patient à l’écran du médecin.
- Demande : Le médecin sélectionne un identifiant de patient.
- Autorisation : Le système vérifie le Autorisations utilisateur magasin pour voir si le médecin a accès aux données de ce cabinet spécifique.
- Récupération : Si autorisé, le Moteur de requête récupère les données du Dossiers des patients magasin.
- Journalisation : Un enregistrement de l’événement d’accès est écrit dans le Journal d’audit avant que les données ne soient affichées.
Cette séparation garantit que même si le magasin de données est compromis, les journaux d’accès fournissent une trace de qui a demandé quelles données. Le Journal d’audit est un magasin de données critique dans ce modèle, souvent traité avec un niveau de sécurité supérieur à celui des dossiers médicaux eux-mêmes.
📊 Niveaux de confidentialité
| Rôle | Accès aux données | Chemin du flux de données |
|---|---|---|
| Réceptionniste | Planning uniquement | Magasin du planning → Affichage |
| Infirmier | Signes vitaux et médicaments | Magasin médical → Vérification d’autorisation → Affichage |
| Spécialiste | Historique complet | Magasin médical → Vérification d’autorisation → Affichage |
Le diagramme distingue clairement entre le Réceptionniste et le Spécialistechemins. Même s’ils accèdent tous deux à un patient, les flux de données sont filtrés différemment. Cette granularité est essentielle pour respecter les réglementations en matière de protection des données.
🛠️ Méthodologie pour une modélisation efficace
Une modélisation réussie exige une approche rigoureuse. Ce n’est pas seulement une question de dessiner des boîtes et des flèches ; il s’agit de comprendre la logique métier et de la traduire en une représentation technique.
1. Définir clairement le périmètre
Commencez par déterminer la frontière du système. Qu’est-ce qui est interne, et qu’est-ce qui est externe ? Dans l’étude de cas financière, le cœur bancaire était une entité externe par rapport à la couche de l’application mobile. Clarifier cela évite l’élargissement du périmètre pendant le développement.
2. Décomposer progressivement
Commencez par un diagramme de contexte de haut niveau. Ensuite, développez chaque processus en un diagramme de niveau 1. Continuez à décomposer jusqu’à ce que les processus soient suffisamment simples pour être codés directement. Cette approche hiérarchique maintient le modèle lisible.
3. Valider les magasins de données
Chaque magasin de données doit avoir un objectif clair. Posez-vous la question : pourquoi ces données sont-elles sauvegardées ? Sont-elles nécessaires à un processus futur ? Si un magasin de données n’a ni flux entrants ni sortants, il s’agit d’un fardeau inutile. Dans le cas de l’inventaire, le Table de stockage était justifié par le besoin de contrôle de concurrence.
4. Vérifier la cohérence
Assurez-vous que les données entrant dans un processus correspondent aux données attendues par le processus suivant. Les formats incompatibles ou les champs manquants sont des sources fréquentes d’erreurs système. Les vérifications de cohérence doivent être documentées dans les étiquettes des flux de données.
🔄 Maintenance et évolution
Les systèmes évoluent, et les modèles de flux de données doivent évoluer avec eux. Un diagramme statique devient obsolète dès que les exigences métiers changent.
Lors de l’introduction d’une nouvelle fonctionnalité, cartographiez les nouveaux flux de données par rapport au diagramme existant. Recherchez les conflits. Par exemple, ajouter une fonctionnalité de notification au système financier pourrait nécessiter un nouveau processus pour gérer l’envoi par courriel et un nouveau magasin de données pour les modèles de messages.
Des audits réguliers du DFD sont recommandés. Comparez les journaux système réels aux flux de données prévus. Les écarts indiquent soit une déviation dans l’implémentation, soit un modèle obsolète. La mise à jour du modèle garantit que les nouveaux développeurs peuvent comprendre l’architecture sans avoir à reverse-engineérer le code.
📋 Résumé des considérations clés
La liste suivante garantit que les modèles de flux de données restent efficaces et précis tout au long du cycle de vie du projet.
- Complétude : Chaque processus dispose-t-il d’entrées et de sorties ?
- Cohérence : Les flux de données sont-ils cohérents en format et en type entre les processus ?
- Sécurité : Les flux de données sensibles sont-ils protégés par des processus d’autorisation ?
- Clarté :Les étiquettes sont-elles descriptives et sans ambiguïté ?
- Traçabilité :Peut-on remonter chaque morceau de données à sa source et à sa destination ?
En s’attachant à ces principes, les organisations peuvent construire des systèmes robustes, sécurisés et faciles à maintenir. L’effort investi dans une modélisation détaillée rapporte des bénéfices lors des phases de test et de déploiement, réduisant ainsi la probabilité de défaillances critiques.
La modélisation du flux de données est une compétence fondamentale pour les architectes système. Elle comble le fossé entre les exigences abstraites et la mise en œuvre concrète. Que l’on gère des transactions financières, des niveaux de stock ou des dossiers de patients, la logique reste la même : les données doivent être capturées, transformées, stockées et récupérées avec précision. Suivre les modèles établis dans ces études de cas fournit un cadre fiable pour concevoir des systèmes d’information complexes.
🚀 Réflexions finales sur l’architecture
La qualité d’un système est souvent déterminée avant qu’une seule ligne de code ne soit écrite. Les diagrammes créés pendant la phase de planification dictent les performances et la fiabilité du produit final. En se concentrant sur le déplacement des données plutôt que seulement sur leur stockage, les architectes peuvent identifier les goulets d’étranglement et les failles de sécurité dès le début.
Souvenez-vous qu’un modèle est un outil de communication tout autant qu’une spécification technique. Il permet aux parties prenantes de visualiser le comportement du système. Lorsque le diagramme est clair, le code suit naturellement. Lorsque le diagramme est flou, le code devient un cauchemar de maintenance.
Appliquez ces principes à votre prochain projet. Commencez par le contexte, décomposez les processus et vérifiez les magasins de données. Une approche disciplinée de la modélisation du flux de données est le signe distinctif d’une pratique d’ingénierie mûre.