











Les systèmes distribués sont intrinsèquement complexes. Ils impliquent plusieurs composants indépendants qui doivent s’organiser pour atteindre un objectif commun. Visualiser cette coordination est essentiel pour les architectes comme pour les développeurs. Les diagrammes de communication constituent un outil puissant pour cartographier ces interactions. Contrairement aux diagrammes de séquence qui se concentrent sur le temps, les diagrammes de communication mettent l’accent sur les relations structurelles entre les objets et les messages échangés entre eux. Cette distinction est cruciale lorsqu’on traite des microservices, des architectures orientées événements ou des réseaux backend complexes.
Créer un diagramme à la fois précis et lisible exige une discipline rigoureuse. Il ne suffit pas de relier simplement des boîtes et des flèches. Le diagramme doit transmettre l’intention, les contraintes et les modes de défaillance. Ce guide présente les pratiques essentielles pour produire des diagrammes de communication de haute fidélité, capables de résister au fil du temps et à l’échelle.
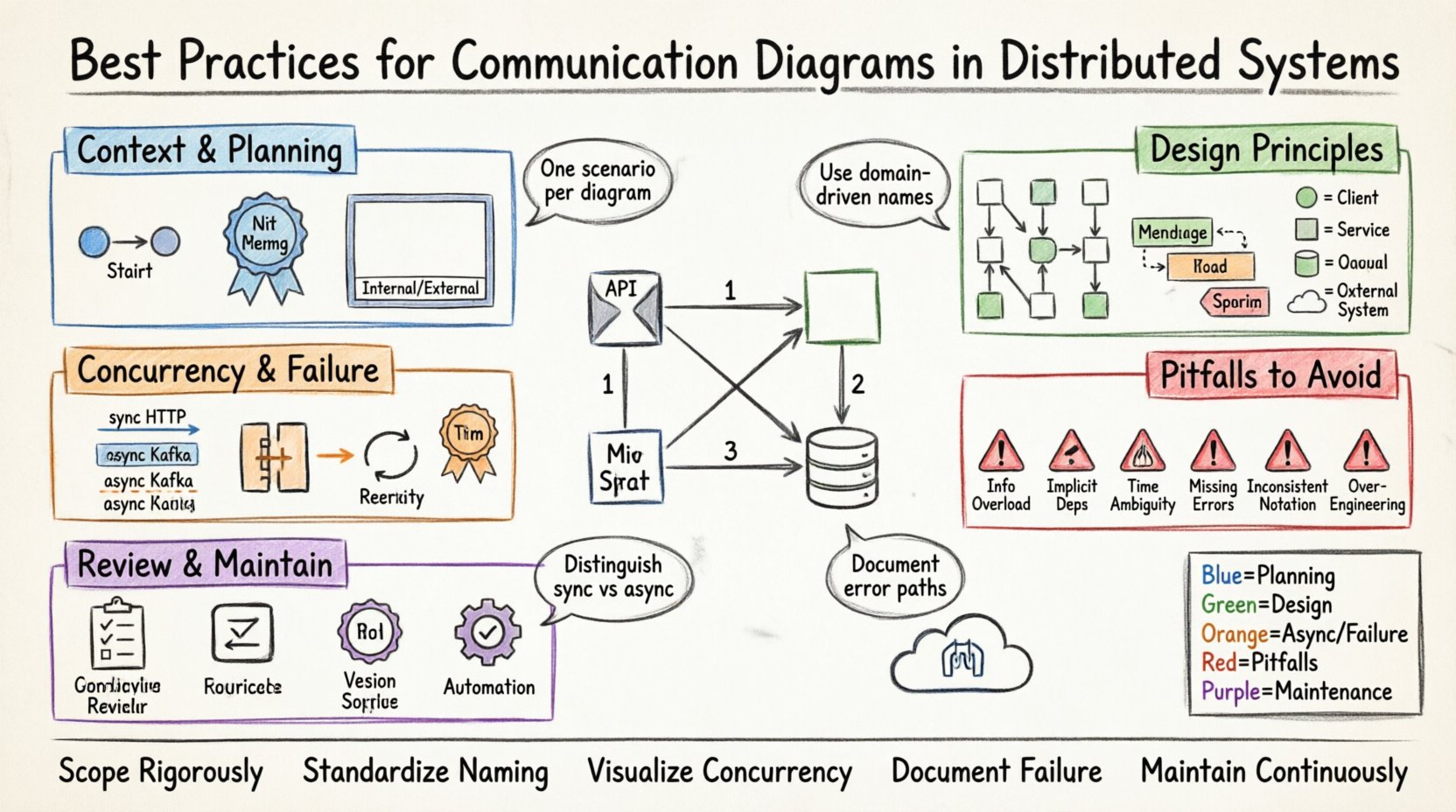
🧩 Comprendre le contexte du diagramme de communication
Avant de tracer une seule ligne, il est nécessaire de comprendre l’utilité spécifique d’un diagramme de communication. Dans le contexte des systèmes distribués, ces diagrammes représentent le flux logique de contrôle et de données à travers les frontières des services. Ils sont particulièrement utiles pour comprendre comment une requête client se propage à travers le système.
- Focus structurel : Le diagramme montre la structure statique du système (objets, services, nœuds) et la manière dont ils sont connectés.
- Focus sur l’interaction : Il met en évidence le comportement dynamique (messages, appels, événements) sans le calendrier linéaire strict d’un diagramme de séquence.
- Frontières réseau : Il représente explicitement les sauts réseau, qui sont critiques dans les environnements distribués.
Lorsque vous tracez un diagramme de communication pour un système distribué, vous documentez le contrat entre les services. Cette documentation devient une source de vérité pour les tests d’intégration et la planification de capacité.
🏗️ Pré-planification et définition du contexte
La clarté commence avant même l’ouverture de l’outil de dessin. Vous devez définir le périmètre du diagramme. Un diagramme qui tente de représenter l’ensemble de l’architecture d’entreprise sera illisible. Concentrez-vous sur un cas d’utilisation ou un flux de transaction spécifique.
1. Définir le périmètre
Identifiez le point de départ et le point d’arrivée de l’interaction. Traquez-vous un flux de connexion utilisateur ? Un processus de synchronisation de données ? Un règlement de paiement ? Restez sur un seul scénario par diagramme.
- Nœud de départ : Marquez clairement le point d’entrée, tel qu’une passerelle API ou une interface utilisateur.
- Nœud de fin : Définissez l’état de terminaison, tel qu’un commit de base de données ou une réponse envoyée au client.
- Frontière : Décidez ce qui est interne au système et ce qui est externe. Les entités externes, telles que les API tierces, doivent être clairement distinguées des microservices internes.
2. Établir des conventions de nommage
La cohérence est essentielle pour la lisibilité. Si vous nommez un service OrderService sur un diagramme, il ne doit pas être OrderManager sur un autre. Adoptez une convention de nommage standard pour tous les nœuds.
- Noms des services : Utilisez des noms orientés domaine (par exemple, “
ServiceInventaire) plutôt que des noms techniques (par exemple,API-01). - Noms des messages : Utilisez des verbes orientés vers l’action pour les messages (par exemple,
réserverInventaire,notifierPaiement). - Étiquettes de retour : Indiquez clairement les états de succès ou d’échec sur les chemins de retour.
🎨 Principes de conception pour la clarté
La disposition visuelle du diagramme influence directement la rapidité avec laquelle un intervenant peut comprendre le système. Un diagramme encombré conduit à des interprétations erronées. Suivez ces principes de conception pour préserver l’intégrité visuelle.
1. Minimisez les lignes croisées
Les lignes croisées créent une charge cognitive. Elles obligent l’œil à sauter par-dessus d’autres éléments pour suivre une connexion. Disposez les nœuds de manière à ce que les connexions s’organisent logiquement, idéalement de gauche à droite ou du haut vers le bas.
- Regroupez les nœuds connexes : Placez les services qui interagissent fréquemment les uns près des autres.
- Utilisez un routage orthogonal : Si l’outil le permet, faites passer les lignes à angle droit plutôt que selon des diagonales, afin de réduire le bruit visuel.
- Empilement : Placez les couches clients en haut ou à gauche, et les couches de données en bas ou à droite.
2. Utilisez des formes et des couleurs distinctes
Les indices visuels aident à distinguer les types de nœuds sans avoir à lire les étiquettes. Bien que la couleur ne devrait pas être le seul critère de distinction, elle accélère la compréhension.
- Nœuds clients : Utilisez une forme ou un style de bordure spécifique pour indiquer les clients externes.
- Services internes : Utilisez une forme de boîte standard.
- Systèmes externes : Utilisez une icône ou une forme différente pour indiquer les dépendances tierces (par exemple, une base de données ou un système hérité).
- Files d’attente asynchrones :Représentez les files de messages par un cylindre ou une forme de file distincte.
3. Étiquetage efficace des messages
Une étiquette de message doit contenir suffisamment d’informations pour comprendre l’échange de données sans avoir à consulter le code.
- Nom de la méthode :Incluez l’endpoint API ou le nom de la fonction.
- Charge utile des données :Mentionnez brièvement l’objet de données principal (par exemple,
OrderDTO). - Contraintes de temporisation :Indiquez les délais d’expiration s’ils sont critiques (par exemple,
timeout : 5s). - Idempotence :Indiquez si l’appel est idempotent, car cela affecte la conception de la logique de réessai.
⚡ Gestion de la concurrence et de la distribution
Les systèmes distribués introduisent une latence et des points de défaillance qui n’existent pas dans les applications monolithiques. Vos diagrammes doivent refléter ces réalités. Les ignorer crée un faux sentiment de sécurité.
1. Représentez clairement les appels asynchrones
Toute communication n’est pas synchrone. De nombreux systèmes distribués reposent sur la messagerie asynchrone pour découpler les services. Différenciez-les des appels directs.
- Synchrones :Utilisez des lignes pleines avec des flèches ouvertes pour représenter les appels bloquants (par exemple, HTTP/REST).
- Asynchrones :Utilisez des lignes pointillées ou des flèches distinctes pour représenter les messages « envoyer et oublier » (par exemple, événements Kafka, messages RabbitMQ).
- Chemins de retour :Les appels asynchrones n’ont souvent pas de chemins de retour immédiats. Ne dessinez pas une flèche de retour sauf si un rappel est impliqué.
2. Visualisez les modes de défaillance
Un diagramme ne montrant que les parcours heureux est incomplet. Il doit indiquer où les choses peuvent mal tourner.
- Propagation des erreurs :Montrez comment les erreurs remontent depuis un service en aval jusqu’au client.
- Délais d’attente :Marquez les lignes qui impliquent une latence réseau là où des délais d’attente sont probables.
- Disjoncteurs de circuit :Si un disjoncteur de circuit est en place, étiquetez la connexion pour indiquer ce mécanisme de protection.
- Logique de réessai :Indiquez si un nœud tentera de réessayer une connexion échouée.
3. Gérer la complexité grâce à l’abstraction
À mesure que les systèmes grandissent, un seul diagramme devient trop volumineux. Utilisez l’abstraction pour gérer la complexité.
- Niveaux de zoom :Créez un diagramme de vue d’ensemble de haut niveau et des sous-diagrammes détaillés pour les services complexes.
- Boîte noire :Si un service effectue une logique complexe, représentez-le par un seul nœud dans le diagramme de haut niveau.
- Références :Liez à la documentation externe pour la logique interne détaillée d’un service spécifique.
🚫 Pièges courants et anti-modèles
Éviter les erreurs est tout aussi important que suivre les bonnes pratiques. Le tableau suivant décrit les erreurs courantes dans la conception des diagrammes de communication et comment les corriger.
| Anti-modèle | Pourquoi cela échoue | Stratégie de correction |
|---|---|---|
| Surcharge d’information | Trop de messages encombrent le diagramme, le rendant illisible. | Concentrez-vous sur le flux principal. Déplacez les flux secondaires vers des sous-diagrammes. |
| Dépendances implicites | Suppose que le lecteur sait qu’un service existe sans le montrer. | Rendez chaque nœud explicite. Si un service est impliqué, il doit être dessiné. |
| Ambiguïté temporelle | Les diagrammes de communication ne montrent pas bien le temps, ce qui entraîne une confusion sur l’ordre. | Utilisez des messages numérotés (1, 2, 3) pour indiquer un ordre strict lorsque nécessaire. |
| Absence de chemins d’erreur | Montre uniquement le succès, en ignorant les scénarios d’échec essentiels à la fiabilité. | Inclure des lignes pointillées pour la gestion des erreurs et les mécanismes de secours. |
| Notation incohérente | Utiliser des symboles différents pour le même type de nœud cause de la confusion. | Établir un guide de style et s’y tenir sur l’ensemble des diagrammes. |
| Surconception | Essayer de représenter chaque cas limite possible dans une seule vue. | Représentez principalement le parcours normal. Documentez les exceptions séparément. |
🔍 Revue et validation
Une fois le diagramme esquissé, il doit subir un processus de revue. Un diagramme est un contrat entre les équipes. S’il est erroné, l’implémentation le sera aussi.
- Revue par les pairs : Faites lire le diagramme par un collègue qui n’est pas impliqué dans la conception. Si cette personne ne comprend pas le flux, le diagramme doit être simplifié.
- Passage en revue du code : Comparez le diagramme avec le code ou la configuration réels. Assurez-vous que le diagramme correspond à la réalité du déploiement.
- Approbation des parties prenantes : Assurez-vous que les parties prenantes métier comprennent le flux de données représenté. Elles ne s’intéressent peut-être pas à l’implémentation technique, mais doivent comprendre le processus métier.
🔄 Maintenance et évolution
Le logiciel n’est jamais statique. Les systèmes distribués évoluent fréquemment. Un diagramme exact aujourd’hui peut devenir obsolète demain. Traitez les diagrammes comme des documents vivants.
1. Contrôle de version des diagrammes
Tout comme le code, les diagrammes doivent être versionnés. Stockez-les dans le même dépôt que le code source si possible. Cela garantit que la documentation correspond à la version de la base de code.
- Messages de validation : Lors de la mise à jour d’un diagramme, utilisez des messages de validation clairs expliquant le changement.
- Journal des modifications : Maintenez un journal des modifications architecturales importantes reflétées dans les diagrammes.
2. Automatisez autant que possible
Le dessin manuel est sujet aux erreurs humaines et devient rapidement obsolète. Si votre organisation utilise la génération de code ou l’infrastructure comme code, envisagez de générer les diagrammes à partir du code.
- Analyse statique : Utilisez des outils qui analysent la base de code pour générer automatiquement des graphes d’interaction.
- Spécifications d’API : Générez des diagrammes à partir des définitions OpenAPI ou gRPC pour garantir une précision avec les contrats d’API.
- Fichiers de configuration :Mettez les configurations du service mesh directement en correspondance avec des nœuds visuels.
📝 Résumé des points clés à retenir
Créer des diagrammes de communication clairs pour les systèmes distribués est une compétence qui allie précision technique et conception visuelle. En suivant des pratiques structurées, vous réduisez l’ambiguïté et améliorez l’alignement de l’équipe.
- Délimitez rigoureusement :Limitez le diagramme à une transaction ou un flux spécifique.
- Standardisez les noms :Assurez une cohérence sur tous les nœuds et messages.
- Visualisez la concurrence :Distinguez clairement les flux synchrones et asynchrones.
- Documentez les défaillances :Incluez les chemins d’erreur et les mécanismes de réessai dans la conception.
- Maintenez continuellement :Traitez les diagrammes comme une documentation vivante liée à la base de code.
Lorsque ces pratiques sont appliquées de manière cohérente, les diagrammes deviennent des actifs précieux. Ils servent de référence pour intégrer de nouveaux développeurs, de guide pour diagnostiquer les problèmes en production, et de plan directeur pour les évolutions futures de l’architecture. L’effort investi dans la création de diagrammes clairs rapporte des bénéfices en réduisant la charge cognitive et les erreurs d’intégration.
🛠️ Liste de contrôle pour la mise en œuvre pratique
Avant de finaliser un diagramme, passez en revue cette liste de contrôle pour garantir la qualité.
- [ ] Toutes les dépendances externes sont-elles clairement indiquées ?
- [ ] Le point d’entrée est-il évident ?
- [ ] Les valeurs de retour sont-elles étiquetées ?
- [ ] Les messages asynchrones sont-ils distincts des appels synchrones ?
- [ ] Le diagramme est-il lisible d’un coup d’œil sans zoomer ?
- [ ] Tous les acronymes sont-ils définis ou auto-explicatifs ?
- [ ] Le diagramme correspond-il à la version actuelle du code ?
- [ ] Les scénarios d’erreur ont-ils été pris en compte ?
Adopter cette liste de contrôle garantit que chaque diagramme répond à un haut niveau de qualité. Elle déplace l’accent de la simple création d’un dessin vers la création d’un modèle précis du comportement du système. C’est cette précision qui permet aux systèmes distribués de fonctionner de manière fiable à grande échelle.