











Bei der Modellierung komplexer Systeme ist Klarheit das primäre Ziel. Datenflussdiagramme (DFDs) dienen als grundlegendes Werkzeug zur Visualisierung der Bewegung von Informationen innerhalb eines Systems. In diesem Rahmen dominieren zwei Symbole das Bild: das Prozess und das Datenbank. Obwohl sie häufig interagieren, repräsentieren sie grundlegend unterschiedliche Konzepte hinsichtlich Transformation und Persistenz. Das Verständnis dieses Unterschieds ist entscheidend für eine genaue Systemanalyse und -gestaltung.
Dieser Leitfaden untersucht die funktionalen Rollen, visuellen Darstellungen und logischen Implikationen dieser Elemente. Durch die Unterscheidung zwischen Aktion und Speicherung können Analysten Diagramme erstellen, die das Systemverhalten ohne Mehrdeutigkeit vermitteln.
🔄 Definition des Prozesses
Ein Prozess stellt eine Arbeitseinheit oder Transformation dar. Hier verändert sich die Datenform, werden Berechnungen durchgeführt oder Daten gefiltert. Stellen Sie sich einen Prozess als schwarzes Kästchen vor. Sie wissen, was hineingeht und was herauskommt, aber der interne Mechanismus wird durch die Transformationslogik selbst definiert, nicht durch die Speicherung dieser Informationen.
🔹 Kernmerkmale
- Transformation: Die primäre Funktion besteht darin, Daten zu verändern. Eingabedaten treten ein, Regeln oder Logik werden angewendet, und Ausgabedaten verlassen den Prozess.
- Zeitliche Natur: Prozesse sind nur aktiv, wenn sie ausgelöst werden. Sie behalten Daten zwischen Ausführungen nicht bei.
- Richtungsabhängigkeit: Daten fließen in einen Prozess hinein und aus ihm heraus. Ein Prozess ohne Eingabe oder Ausgabe ist logisch ungültig im Kontext eines DFD.
- Verbenbenennung: Prozesse werden typischerweise mit Verben oder Verbenphrasen benannt (z. B. Steuer berechnen, Benutzer validieren, Bericht generieren).
🔹 Das Konzept des schwarzen Kastens
Bei der hochstufigen Modellierung ist ein Prozess ein schwarzes Kästchen. Der Fokus liegt auf waspassiert mit den Daten, nicht auf wie es technisch geschieht. Zum Beispiel nimmt ein Prozess namens „Auftrag verarbeiten“ Auftragsdetails entgegen und erstellt einen Transaktionsdatensatz. Es wird nicht spezifiziert, ob die Berechnung im Speicher, auf einer Festplatte oder über eine externe API erfolgt. Diese Abstraktion ermöglicht es den Beteiligten, sich auf die Geschäftslogik zu konzentrieren, anstatt sich mit der technischen Umsetzung zu beschäftigen.
Allerdings wird die interne Logik, je weiter Diagramme auf niedrigeren Ebenen aufgelöst werden, detaillierter. Trotzdem bleibt der Prozess eine aktive Transformationsmaschine. Er verbraucht Eingaben, führt Arbeit aus und erzeugt Ausgaben. Er dient nicht als Puffer für diese Informationen.
🗄️ Definition der Datenbank
Ein Datenspeicher stellt ein Repository dar, in dem Informationen gespeichert sind. Im Gegensatz zu einem Prozess transformiert ein Datenspeicher keine Daten. Er wartet. Er hält Daten in einem dauerhaften Zustand, bis ein Prozess sie abruft oder ein Prozess sie dort ablegt.
🔹 Kernmerkmale
- Dauerhaftigkeit:Daten bleiben auch dann im Speicher, wenn keine Prozesse aktiv sind. Dies ist der entscheidende Unterschied zu Speicherpuffern oder temporären Variablen.
- Passives Wesen:Datenspeicher initiieren keine Aktionen. Sie erfordern einen Prozess, um Daten daraus zu lesen oder hineinzuschreiben.
- Nomen-Namensgebung:Speicher werden typischerweise mit Substantiven benannt (z. B. Kunden-Datenbank, Bestell-Datei, Lager-Protokoll).
- Offen-ended:Datenströme können in einen Speicher eintreten und ihn verlassen. Ein Speicher kann jedoch nicht direkt mit einem anderen Speicher verbunden sein. Daten müssen über einen Prozess fließen, um zwischen Repositorien zu wechseln.
🔹 Das Repository-Konzept
Stellen Sie sich eine Bibliothek vor. Die Bücher sind die Daten. Die Regale sind die Datenspeicher. Ein Bibliothekar ist der Prozess. Der Bibliothekar erstellt die Bücher nicht; er ordnet sie. Die Regale bewegen die Bücher nicht selbst; sie halten sie an Ort und Stelle. Wenn ein Besucher ein Buch anfordert, holt der Bibliothekar es ab (Lesevorgang). Wenn ein neues Buch eintrifft, legt der Bibliothekar es auf das Regal (Schreibvorgang).
In der Systemarchitektur kann ein Datenspeicher eine Datenbanktabelle, eine flache Datei, eine Warteschlange oder einen Cloud-Container darstellen. Das DFD-Symbol abstrahiert die Technologie. Ob es sich um eine SQL-Tabelle oder eine einfache Textdatei handelt, die logische Rolle bleibt identisch: Es ist ein Ort, an dem Informationen gespeichert werden.
⚡ Interaktion und Datenfluss
Die Beziehung zwischen einem Prozess und einem Datenspeicher wird strengen Regeln des Datenflusses unterworfen. Pfeile in einem DFD stellen die Bewegung von Daten dar. Diese Pfeile bestimmen die Richtung des Informationsaustauschs.
🔹 Der Lese-Schreib-Zyklus
Wenn ein Prozess Informationen benötigt, zeichnet er einen Pfeil von einem Datenspeicher zum Prozess. Dies deutet auf einen Lesevorgang hin. Der Prozess extrahiert Daten, um sie in seiner Transformationslogik zu verwenden. Umgekehrt zeichnet ein Prozess, wenn er neue Informationen erzeugt, einen Pfeil vom Prozess zu einem Datenspeicher. Dies deutet auf einen Schreibvorgang hin. Die Daten sind nun für die zukünftige Verwendung gespeichert.
Wichtig ist, dass ein Datenfluss zwei Datenspeicher nicht direkt verbinden kann. Informationen können nicht von einem Repository in ein anderes migrieren, ohne verarbeitet zu werden. Diese Regel stellt sicher, dass jeder Datenfluss immer mit einem gewissen Maß an Logik oder Kontrolle einhergeht, auch wenn es sich nur um eine einfache Kopieroperation handelt.
🔹 Externe Entitäten
Externe Entitäten (Quellen oder Senken) interagieren mit Prozessen, nicht direkt mit Datenspeichern. Eine externe Entität kann ein menschlicher Benutzer, eine Drittanbieter-API oder ein anderes System sein. Sie senden Daten an einen Prozess oder empfangen Daten von einem Prozess. Der Prozess entscheidet dann, ob die Daten in einem Repository gespeichert oder verworfen werden.
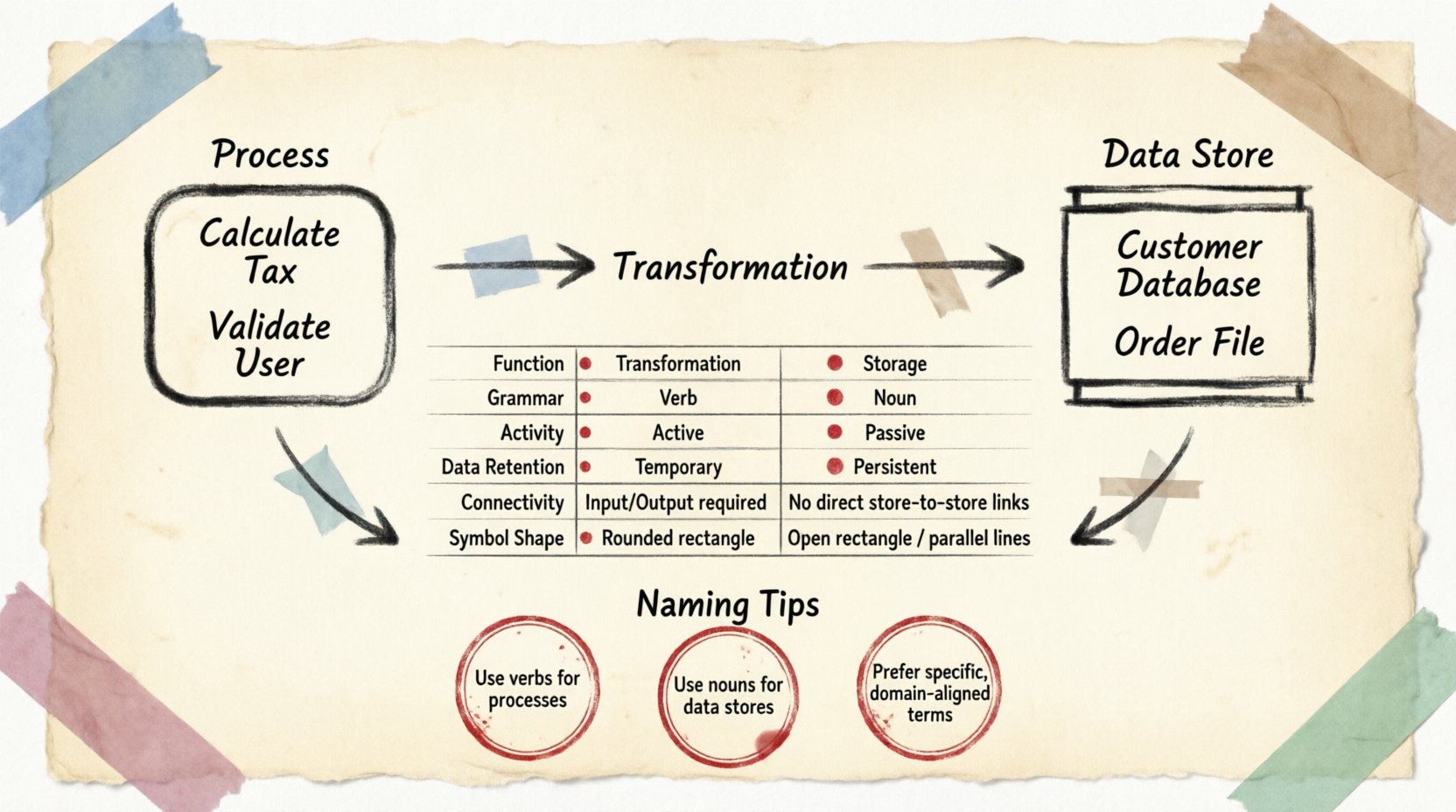
📋 Vergleichstabelle
Zusammenfassend die strukturellen Unterschiede, betrachten Sie die folgende Aufteilung der Attribute.
| Attribut | Prozess | Datenspeicher |
|---|---|---|
| Funktion | Transformation / Aktion | Speicher / Speicher |
| Grammatik | Verb (z. B. Aktualisieren) | Substantiv (z. B. Benutzertabelle) |
| Aktivität | Aktiv (Läuft bei Auslösung) | Passiv (Bleibt bis zum Zugriff unverändert) |
| Datenhaltung | Temporär (Während der Ausführung) | Persistent (Langfristig) |
| Konnektivität | Verbindet sich mit Entitäten, Speichern und anderen Prozessen | Verbindet sich nur mit Prozessen |
| Symbolform | Abgerundetes Rechteck oder Kreis | Offenes Rechteck oder parallele Linien |
🧩 Namenskonventionen
Konsistenz bei der Benennung verhindert Verwirrung während der Überprüfungs- und Implementierungsphasen. Mehrdeutigkeit entsteht oft, wenn der gleiche Begriff sowohl für Speicher als auch für Aktionen verwendet wird.
🔹 Prozessbenennung
Namensbezeichnungen sollten die durchgeführte Aktion an den Daten beschreiben. Vermeiden Sie generische Namen wie „Mach es“ oder „Behandle“. Stattdessen verwenden Sie spezifische Beschreibungen. Zum Beispiel ist „Anmeldeinformationen überprüfen“ besser als „Anmeldung prüfen“. Diese Klarheit hilft Entwicklern, die erwarteten Eingabe- und Ausgabeanforderungen sofort zu verstehen.
🔹 Datenspeicherbenennung
Namensbezeichnungen sollten den Inhalt widerspiegeln. Verwenden Sie Pluralformen oder klare Kennzeichnungen. „Bestellungen“ deutet auf eine Sammlung von Bestellprotokollen hin. „Bestellung“ könnte auf eine einzelne Transaktionsinstanz hindeuten. Obwohl der Kontext wichtig ist, deuten Pluralformen im Allgemeinen auf eine Sammlung mehrerer Datensätze hin.
Bei der Benennung von Datenspeichern sollten Sie die Reichweite berücksichtigen. Ein Speicher mit dem Namen „Datenbank“ ist zu ungenau. „Kunden-Datenbank“ oder „Transaktionsprotokoll“ geben die notwendige Kontextinformation. Diese Detaillierung unterstützt später die Zuordnung des Diagramms zu physischen Speicherstrukturen.
🧪 Zerlegung und Ebenen
DFDs sind hierarchisch aufgebaut. Ein Diagramm auf hoher Ebene (Kontextdiagramm) zeigt das System als einen einzigen Prozess. Wenn Sie dieses Diagramm in niedrigere Ebenen zerlegen, wird der Unterschied zwischen Prozess und Speicher zunehmend entscheidend.
🔹 Ebene 0 vs. Ebene 1
Im Kontextdiagramm ist das gesamte System ein einziger Prozess. In Ebene 0 wird dieser Prozess in Hauptunterprozesse zerlegt. Datenspeicher werden hier eingeführt, um anzuzeigen, wo die wichtigsten Datenkomponenten gespeichert sind. In Ebene 1 und darüber hinaus werden die Prozesse weiter verfeinert.
Bei der Zerlegung stellen Sie sicher, dass Datenspeicher nicht unnötig dupliziert werden. Wenn ein Speicher in Ebene 0 existiert, sollte er im Allgemeinen bis zur Ebene 1 erhalten bleiben, es sei denn, ein spezifischer Unterprozess benötigt einen temporären Cache (der dann ein anderer Speicher wäre). Konsistenz über die Ebenen hinweg gewährleistet die Rückverfolgbarkeit.
🔹 Ausgewogenheit
Eine entscheidende Regel bei der Zerlegung ist die „Ausgewogenheit“. Die Eingaben und Ausgaben eines übergeordneten Prozesses müssen mit den Eingaben und Ausgaben der untergeordneten Prozesse im niedrigeren Diagramm übereinstimmen. Auch die Datenspeicher müssen abgestimmt sein. Wenn ein Speicher im übergeordneten Diagramm erscheint, muss das untergeordnete Diagramm die Datenflüsse korrekt berücksichtigen. Wenn ein Prozess aufgeteilt wird, muss der Datenfluss zum Speicher über die Aufteilung hinweg erhalten bleiben.
⚠️ Logische Fehler, die vermieden werden sollten
Bestimmte strukturelle Fehler können ein Diagramm ungültig machen. Die frühzeitige Erkennung dieser Fehler spart Zeit während der Entwicklungsphase.
- Geisterdatenflüsse: Ein Pfeil, der einen Prozess verlässt, ohne einen eingehenden Datenfluss zu haben, ist unmöglich. Ein Prozess kann keine Ausgabe aus dem Nichts erzeugen. Jede Ausgabe muss aus einer Eingabe oder gespeicherten Daten abgeleitet werden.
- Direkte Speicherverbindungen: Wie erwähnt, kann ein Speicher nicht direkt mit einem anderen Speicher verbunden werden. Daten müssen durch einen Prozess laufen. Dies stellt sicher, dass alle Datenbewegungen bewusst und verarbeitet werden.
- Nicht angeschlossene Prozesse: Ein Prozess, der weder eingehende noch ausgehende Datenflüsse hat, ist isoliert. Er interagiert nicht mit dem System und erfüllt in der DFD keine Funktion.
- Verwechslung von Entitäten und Speichern: Externe Entitäten liegen außerhalb der Systemgrenze. Datenspeicher liegen innerhalb. Plazieren Sie kein Symbol für eine externe Entität innerhalb der Systemgrenze, als ob es eine Datenbank wäre.
🛠️ Implikationen für die Umsetzung
Der Unterschied zwischen Prozess und Speicher beeinflusst, wie das System aufgebaut wird. Prozesse entsprechen Funktionen, Methoden oder Mikrodiensten. Datenspeicher entsprechen Tabellen, Dateien oder Objektspeicher.
🔹 Datenbankgestaltung
Beim Entwurf einer Datenbank werden die Datenspeicher in der DFD zum Schema-Entwurf. Die Attribute innerhalb der Datenfluss-Pfeile definieren die Spalten. Die Beziehungen zwischen Speichern (vermittelt durch Prozesse) definieren Fremdschlüssel oder transaktionale Verbindungen.
🔹 Workflow-Automatisierung
Für Workflow-Engines stellen Prozesse die Schritte in einer Pipeline dar. Datenspeicher repräsentieren den Zustand des Workflows. Ein Prozess könnte den Zustand im Speicher aktualisieren, um eine Aufgabe als abgeschlossen zu markieren. Das Verständnis der passiven Natur des Speichers stellt sicher, dass der Workflow-Engine wartet, bis der korrekte Zustand erreicht ist, bevor sie fortfährt.
🔍 Standards für die visuelle Darstellung
Verschiedene Methodologien verwenden leicht unterschiedliche Symbole, aber die Logik bleibt konsistent.
- DeMarco & Yourdon: Verwendet abgerundete Rechtecke für Prozesse und offene Rechtecke für Datenspeicher.
- Gane & Sarson: Verwendet abgerundete Rechtecke für Prozesse und parallele Linien für Datenspeicher.
Unabhängig von der gewählten Notation ist die semantische Bedeutung identisch. Ein Prozess handelt; ein Speicher hält. Konsistenz innerhalb der Projekt-Dokumentation ist wichtiger als die strikte Einhaltung eines bestimmten Standards, solange das Team die gewählte Konvention versteht.
🎯 Zusammenfassung der Rollen
Der Aufbau eines robusten Systemmodells erfordert Disziplin bei der Zuweisung von Rollen. Der Prozess ist der Akteur. Er führt die Arbeit aus. Der Datenspeicher ist die Bühne. Er hält die Requisiten. Ohne den Akteur ist die Bühne leer. Ohne die Bühne hat der Akteur keinen Ort, um seine Ergebnisse abzulegen.
Durch die klare Trennung zwischen Transformation und Speicherung erstellen Analysten Diagramme, die nicht nur optisch ansprechend, sondern auch logisch schlüssig sind. Diese Diagramme dienen als Vertrag zwischen Geschäftssachverständigen und technischen Teams. Sie definieren die Grenzen der Verantwortung und den Fluss von Wert.
Beim Überprüfen einer DFD sollten Sie für jedes Symbol zwei Fragen stellen: „Tut dies die Arbeit?“ (Prozess) oder „Hält dies Informationen?“ (Speicher). Wenn die Antwort unklar ist, verfeinern Sie die Bezeichnung oder die Verbindung. Klarheit ist das endgültige Ziel der Systemmodellierung.
Die Einhaltung dieser Prinzipien stellt sicher, dass die resultierende Architektur wartbar, skalierbar und verständlich ist. Der Unterschied ist einfach, doch seine Auswirkung auf die Systemintegrität ist tiefgreifend.