











在现代信息架构中,数据完整性是可靠系统行为的基础。当数据进入处理环境时,可能携带潜在风险,这些风险会干扰操作、损害安全或破坏下游输出。验证系统输入不仅仅是安全检查,更是系统设计中嵌入的基本逻辑要求。通过在数据流图(DFD)中使用流逻辑,工程师可以精确地描绘出验证发生的位置、错误如何处理,以及数据如何在架构中流转。这种方法确保了进入系统的每一条信息在影响业务逻辑之前都满足必要的标准。
本文将从流逻辑的角度探讨输入验证的机制。我们将研究如何以可视化方式表示验证规则,如何为数据接受设置决策点,以及如何在不中断流程的情况下管理错误状态。理解这些机制,使架构师能够构建出能够抵御错误数据和外部威胁的系统。
理解验证中的数据流图 📊
数据流图提供了信息在系统中流动方式的可视化表示。它们描绘了处理过程、数据存储、外部实体以及数据本身。在验证的背景下,DFD成为信任的路线图。它展示了数据在何处被接收、在何处被检查,以及在何处被存储或丢弃。
一个标准的DFD包含四个主要元素:
- 处理过程: 数据的转换。验证逻辑通常位于此处。
- 数据存储: 数据保存的仓库。在数据进入存储之前必须进行验证。
- 外部实体: 系统边界之外的数据源或目标。输入由此产生。
- 数据流: 元素之间数据的流动。验证检查沿这些路径进行。
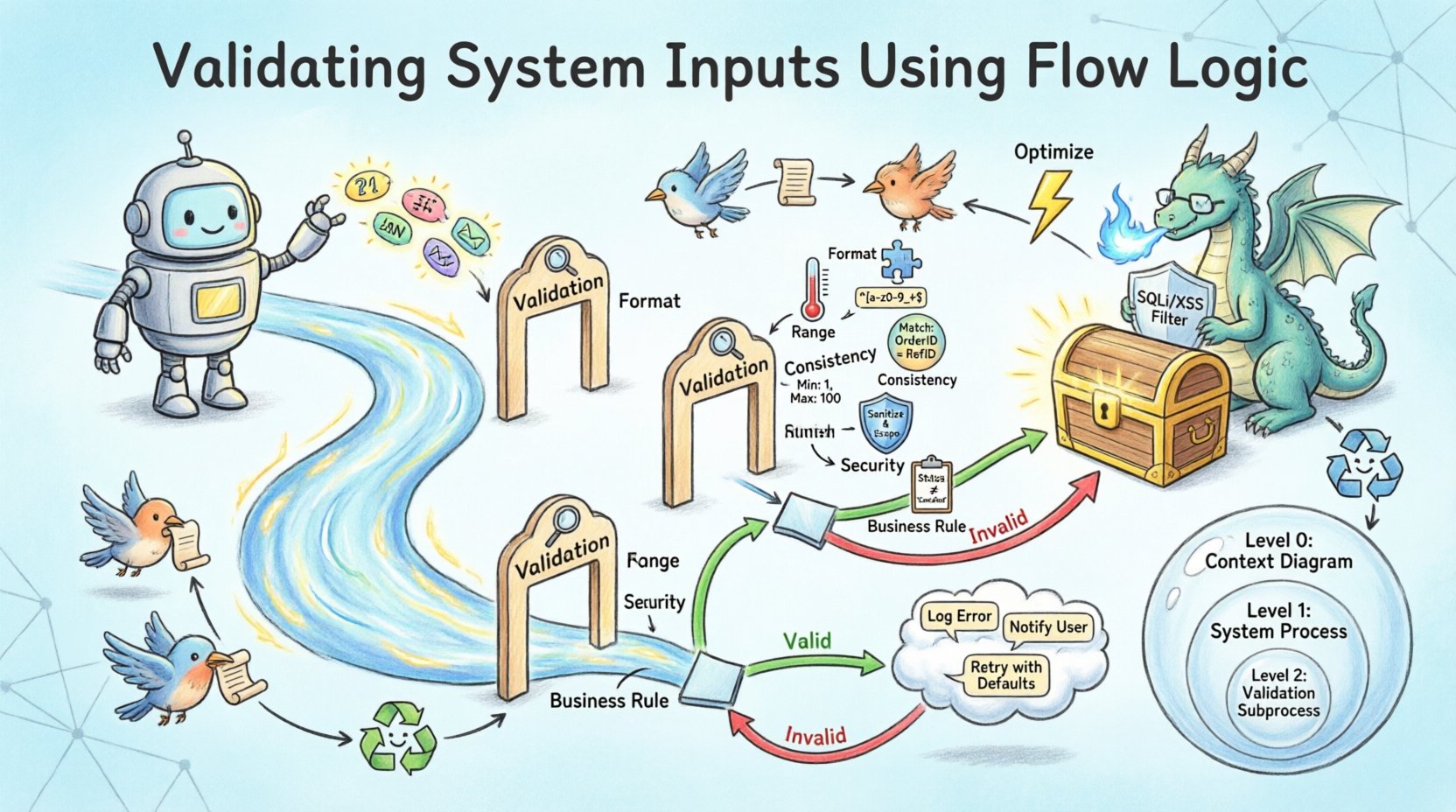
在设计验证时,处理过程元素变得至关重要。仅仅将数据从A点移动到B点是不够的。处理过程必须根据一组规则评估数据。在图中,这通常通过一个标记为“验证”或“净化”的特定子过程来表示。这一视觉提示提醒开发人员此处存在用于过滤输入的逻辑。
将验证逻辑映射到流结构 🧠
流逻辑指的是决定数据路径的一系列操作。在验证中,这种逻辑决定了数据是继续进入下一阶段,还是被引导至错误处理程序。实现这一点需要对决策点有清晰的理解。
考虑一个收集用户信息的数据输入表单。流逻辑必须验证以下属性:
- 存在性: 字段是否已填写?
- 类型: 输入是否为正确的数据类型(例如,整数与字符串)?
- 范围: 数值是否在可接受范围内?
- 格式: 字符串是否符合所需模式(例如,电子邮件地址)?
在DFD中,这些检查会形成分支。如果数据通过所有检查,流程将向前推进到主处理过程。如果失败,流程将转向错误处理过程。这种分支对于稳健的架构至关重要。如果没有它,无效数据可能会无声传播,导致计算错误或安全漏洞。
决策点机制
决策点是流程分叉的位置。在流逻辑图中,这通常以菱形形状或特定的处理节点表示,其输出两条不同的数据流:一条标记为“有效”,另一条标记为“无效”。“有效”流继续进入主处理管道。“无效”流则触发错误响应或纠正循环。
在图中区分客户端验证和服务器端验证非常重要。虽然客户端验证能提升用户体验,但服务器端验证才是真正的守门人。在DFD中,服务器端检查应是数据到达数据存储前的最后一道屏障。这确保即使接口被绕过,核心系统依然受到保护。
输入验证规则的类型 🛡️
验证并非单一概念。它包含多个层次的审查。每一层都有不同的目的,并在流逻辑中需要不同的实现策略。
| 验证类型 | 目的 | 示例逻辑 |
|---|---|---|
| 格式验证 | 确保数据符合预期结构 | 使用正则表达式匹配电话号码 |
| 范围验证 | 确保数据在数值范围内 | 年龄必须在18到120之间 |
| 一致性验证 | 确保数据与其他输入一致 | 结束日期必须晚于开始日期 |
| 安全验证 | 防止恶意代码注入 | 清理文本字段中的HTML标签 |
| 业务规则验证 | 确保数据符合操作约束 | 折扣不得超过50% |
将这些规则整合到流程逻辑中需要仔细的顺序安排。安全验证通常应在流程早期进行,以防止对恶意数据包进行昂贵的处理。格式验证通常是第一步,以确保在进行逻辑比较之前数据类型正确。业务规则验证通常在最后进行,因为它可能依赖于已经标准化的数据。
处理错误流程和反馈回路 🔄
一个健壮的系统不仅会拒绝无效数据,还会优雅地处理拒绝。这就是流程逻辑中的“无效”分支发挥作用的地方。错误流程必须导向一个机制,向用户或系统管理员通报问题,而不会暴露敏感的内部信息。
在数据流图中,错误处理过程应包括:
- 日志记录: 记录错误详情以供调试。此流程流向审计日志数据存储。
- 通知: 提醒用户。此流程流向外部实体(用户界面)。
- 更正: 提供一个修复数据的机制。这会形成一个反馈回路,使数据返回到输入阶段。
反馈回路对可用性至关重要。如果用户提交了包含无效电子邮件地址的表单,系统应允许他们立即进行更正。从流程角度来看,数据不会永久离开输入阶段。它会不断根据验证逻辑重新评估,直到通过验证或用户取消操作为止。这可以避免用户旅程中的死胡同。
错误日志和审计追踪
安全和合规性通常要求记录验证失败的情况。即使输入被拒绝,尝试本身也可能是攻击的迹象。因此,应从验证过程到审计日志存在一个独立的数据流。该流程会捕获时间戳、源IP地址和失败的性质。它独立于主数据流运行,以确保日志记录失败不会阻塞合法的处理流程。
将验证集成到流程层级 🏗️
数据流图通常存在于不同抽象层次上。第0层提供高层次概览,而第1层和第2层则分解具体流程。验证逻辑必须在这些层级之间保持一致。
第0层:系统边界
在最高层级上,验证被表示为一个门禁。外部实体发送数据,系统选择接受或拒绝。DFD展示了输入和输出的边界。在此阶段未能通过验证的数据永远不会进入内部系统。
第1层:过程分解
在分解系统时,特定过程会接收验证的子流程。例如,“用户注册”过程可能被拆分为“身份核验”、“密码验证”和“联系信息验证”。每个子过程都有其独立的流程逻辑。该层级的DFD展示了执行这些检查所需的内部数据流动。
第2层:详细逻辑
在最低层级,逻辑被完全定义。这是从图表中推导出实际代码结构的地方。此处的流程逻辑指定了操作的确切顺序。例如,检查用户名是否存在于数据库中,必须在检查其格式是否有效之前完成,以避免泄露关于已有用户的信息。
验证过程中的性能优化 ⚡
验证逻辑会增加计算开销。每次检查都需要处理时间。在高吞吐量系统中,过度的验证可能成为瓶颈。DFD有助于识别需要优化的位置。
优化策略包括:
- 提前退出: 如果基础检查失败(例如字段为空),立即停止处理。不要执行复杂逻辑。
- 缓存: 如果验证依赖于外部数据(例如,将用户ID与被封禁账户列表进行比对),则缓存该数据以减少数据库调用次数。
- 异步处理: 对于非关键性验证,将检查移至后台队列中执行。这能保持主数据流的快速运行。
在DFD中表示这些优化时,应为同步和异步任务使用不同的数据流。这能明确区分哪些验证会阻塞用户,哪些在后台运行。同时,也有助于在负载测试场景中理解系统在压力下的行为。
流程逻辑的安全影响 🔒
无效输入是SQL注入、跨站脚本攻击和缓冲区溢出等攻击的主要途径。为验证设计的流程逻辑充当防火墙。然而,设计必须正确。
设计中的一个常见挑战是假设输入来自可信源。在DFD中,应将每个外部实体视为潜在的敌对方。验证过程必须在数据与数据库或命令行交互前进行清理。这种清理是图表中的一个特定处理节点。
此外,流程逻辑必须防止信息泄露。如果验证错误透露了用户名存在,攻击者可利用此信息枚举账户。错误流应提供通用消息(例如,“凭据无效”),而非具体原因(例如,“用户名未找到”)。这一细微差别应在错误处理过程的描述中体现。
验证流程的测试与验证 ✅
一旦流程逻辑设计完成,就必须进行验证。测试包括通过DFD路径发送数据,以确保逻辑正确。这通常通过针对单个验证规则的单元测试以及针对整个流程的集成测试来完成。
测试用例应涵盖:
- 正常路径: 有效数据通过所有检查并到达数据存储区。
- 边界情况: 处于范围边界的数据(例如,最小值和最大值)。
- 格式错误的数据: 类型错误或包含意外字符的数据。
- 缺失数据: 必填字段缺失的数据。
如果DFD准确,测试结果应与可视化流程一致。如果某个测试用例的失败情况未被图表预测,就必须更新DFD。这一迭代过程确保文档始终真实反映系统行为。
关于结构化验证的结论 📝
使用流程逻辑验证系统输入,可将安全需求转化为架构中的结构性组件。通过在数据流图中映射验证规则,团队能够直观地看到数据在何处被检查、错误如何处理,以及信息如何在系统中流动。这种清晰性减少了歧义,提升了设计师与开发者之间的沟通效率,最终带来更稳定的软件。决策点、错误流与安全检查的整合,确保系统能够抵御外部世界不可避免的干扰。
随着系统复杂性的增加,对结构化流程逻辑的依赖变得愈发关键。它为长期维护数据完整性提供了蓝图。遵循本文所述原则,架构师可以构建出‘不信任任何内容,验证一切’的流水线,从而确保数据生态系统的长期稳定与可靠。