











Projektowanie wytrzymałe maszyny stanów jest jednym z najważniejszych zadań w architekturze systemu. Poprawnie zaimplementowane diagramy stanów zapewniają przejrzystość, przewidywalność i łatwość utrzymania. Jednakże, gdy logika jest błędna, system może wejść w stan, z którego nie jest możliwe dalsze postępowanie. Jest to znane jako zakleszczenie. W diagramie maszyny stanów zakleszczenie występuje, gdy system osiąga stan, z którego nie istnieje żadna poprawna przejście, co powoduje nieustanne zatrzymanie wykonywania. ⏸️
Ten przewodnik omawia mechanizmy projektowania maszyny stanów, skupiając się szczególnie na identyfikacji i zapobieganiu zakleszczeniom. Omówimy strażniki przejść, akcje wejścia i wyjścia, obszary współbieżne oraz strategie weryfikacji. Przestrzegając tych zorganizowanych podejść, możesz zapewnić, że Twoje diagramy stanów będą wytrzymałe w różnych warunkach. 🔒
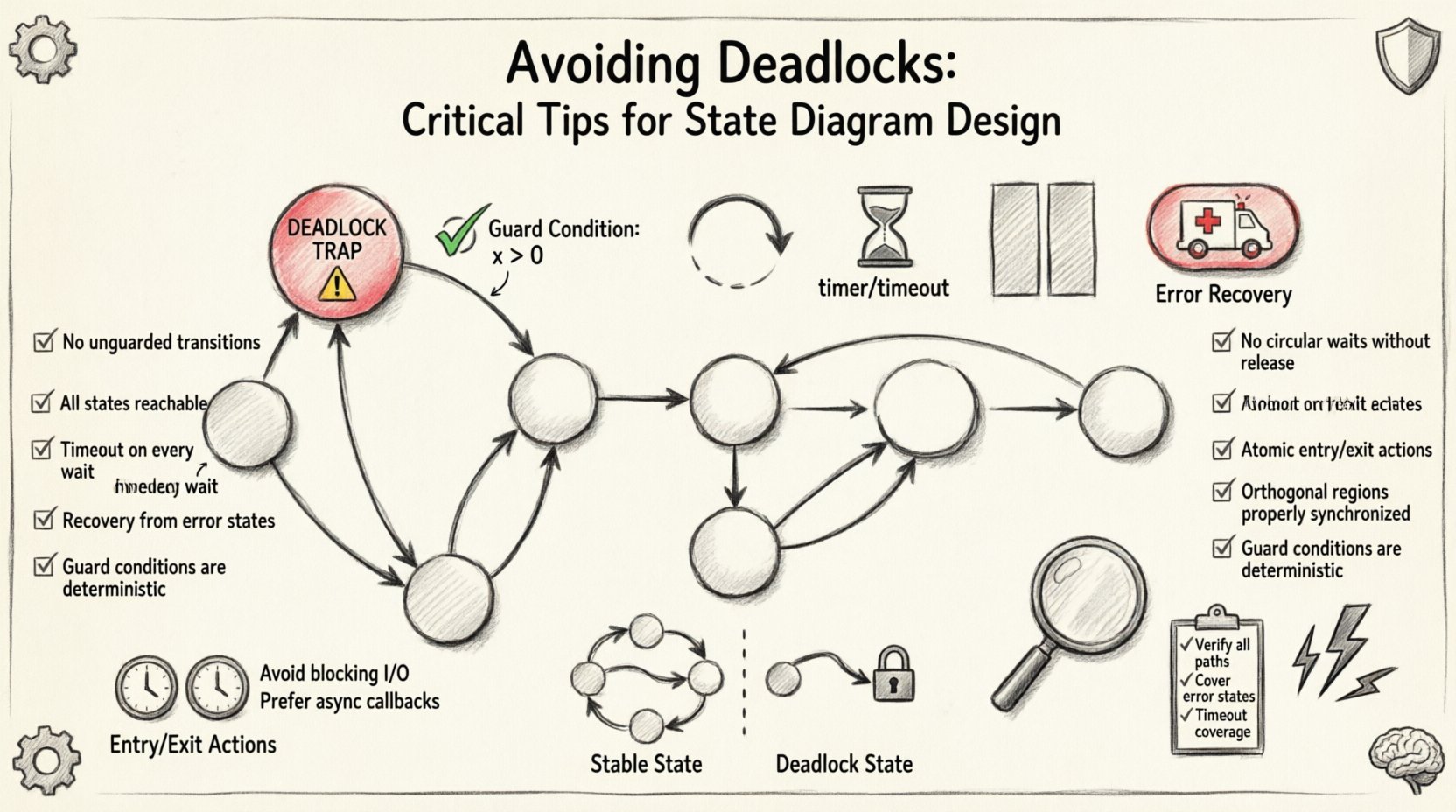
🧠 Zrozumienie zakleszczeń maszyny stanów
Zakleszczenie w skończonej maszynie stanów (FSM) oznacza zatrzymanie logiczne. W przeciwieństwie do błędu czasu wykonania, który może spowodować awarię aplikacji, zakleszczenie często powoduje, że system wydaje się zamarł, mimo że nadal działa. Silnik jest aktywny, ale nie może wykonać żadnych poleceń, ponieważ bieżący stan nie ma wychodzących przejść spełniających warunki wyzwalające. 🔍
Aby projektować skutecznie, należy zrozumieć anatomię scenariusza zakleszczenia. Zazwyczaj nie jest spowodowane jedną brakującą linią kodu. Zamiast tego, często wynika z złożonych interakcji między wieloma stanami, strażnikami i zdarzeniami zewnętrznymi. Poniżej przedstawiono podstawowe cechy stanu zakleszczenia:
- Brak wychodzących przejść: Stan nie ma strzałek wychodzących z niego.
- Nieosiągalne przejścia: Wszystkie wychodzące strzałki mają warunki strażnicze, które nigdy nie mogą być prawdziwe przy bieżących danych.
- Brak domyślnych ścieżek: Nie ma przejścia zapasowego do obsługi nieoczekiwanych danych wejściowych.
- Zachowanie zasobów: System trzyma zasób (np. blokadę lub połączenie), ale czeka na inną warunkę, która nigdy nie zajdzie.
Zapobieganie tym scenariuszom wymaga filozofii projektowania proaktywnego, a nie reaktywnego debugowania. Przeanalizujmy przyczyny głębiej. 📉
⚠️ Powszechne przyczyny zakleszczeń w projektowaniu stanów
Zakleszczenia nie są przypadkowymi wypadkami; są przewidywalnymi skutkami konkretnych wyborów projektowych. Zrozumienie tych wzorców pomaga uniknąć ich przed ich wpływu na środowisko produkcyjne. Oto główne przyczyny zatrzymania maszyny stanów.
1. Brak strażników przejść
Podczas projektowania przejść każda strzałka wychodząca ze stanu reprezentuje możliwy kierunek postępu. Jeśli stan ma wiele możliwych wejść (zdarzeń), ale tylko niektóre są przypisane do przejść, system zatrzymuje się, gdy występuje nieprzypisane zdarzenie. Jest to często nazywane stanem „pułapki”. ❌
- Problem: Maszyna stanów oczekuje określonych wyzwalaczy. Jeśli przychodzi nieoczekiwany wyzwalacz, a żadne przejście go nie obsługuje, system pozostaje w miejscu.
- Rozwiązanie: Upewnij się, że każdy stan uwzględnia wszystkie zdefiniowane zdarzenia, albo zaimplementuj globalny obsługę domyślną, aby przechwycić nieoczekiwane dane wejściowe.
2. Konfliktujące warunki strażnicze
Warunki strażnicze to wyrażenia logiczne, które muszą być prawdziwe, aby przejście mogło się wydarzyć. Powszechnym błędem jest sytuacja, gdy dwa przejścia dzielą ten sam stan źródłowy i zdarzenie, ale ich warunki strażnicze są wzajemnie wykluczające się lub nie pokrywają żadnego możliwego scenariusza. 🧩
- Problem: Definiujesz przejście A (jeśli wynik > 10) i przejście B (jeśli wynik < 5). Co się stanie, jeśli wynik wynosi dokładnie 10? Jeśli logika jest ściśle określona, może nie powieść ani jednego.
- Rozwiązanie: Przejrzyj warunki strażnicze pod kątem przypadków brzegowych. Upewnij się, że suma wszystkich warunków strażniczych dla danego zdarzenia obejmuje całą dziedzinę wejściową.
3. Zależności cykliczne
W złożonych systemach stany mogą zależeć od stanu innych stanów lub zewnętrznych procesów. Jeśli stan A oczekuje na zakończenie stanu B, a stan B oczekuje na potwierdzenie stanu A, żaden z nich się nie rusza. Jest to klasyczny problem zablokowania synchronizacji. ⏳
- Problem:Logika jest tak splątana, że wymaga wzajemnego potwierdzenia przed kontynuacją.
- Rozwiązanie:Przerwij cykl wprowadzając limity czasowe lub pozwalając jednemu procesowi kontynuować bez natychmiastowego potwierdzenia drugiego.
4. Nieprawidłowe obsługiwania stanów historii
Stany historii pozwalają systemowi pamiętać swój poprzedni stan przy ponownym wejściu. Jeśli nie są poprawnie zaimplementowane, stan historii może wskazywać na stan, który już nie jest ważny lub został usunięty. 🔄
- Problem:Maszyna próbuje przejść do stanu historycznego, który już nie istnieje lub jest niedostępny.
- Rozwiązanie:Upewnij się, że cele historyczne są nadal aktywne, gdy maszyna restartuje się lub resetuje.
🛡️ Wzorce projektowe zapobiegające zawieszeniu
Kiedy zrozumiesz ryzyka, możesz zastosować konkretne wzorce, aby je ograniczyć. Te wzorce nie są specyficzne dla oprogramowania; stosują się do dowolnego języka modelowania lub frameworku implementacji. 🛠️
1. Wzorzec stanu domyślnego
Każdy automat stanów powinien mieć zdefiniowany punkt wejścia. Zazwyczaj jest to stan początkowy. Jednak poza stanem początkowym, każdy inny stan powinien mieć idealnie zdefiniowaną ścieżkę domyślną. Jeśli zdarzenie nie spełnia określonego warunku, system powinien przejść do bezpiecznego zachowania domyślnego. 📍
- Wdrożenie:Utwórz przejście „ogólne” dla każdego stanu, które bezpiecznie obsługuje nieznane zdarzenia.
- Zalety:Zapobiega wejściu systemu do niezdefiniowanego stanu w przypadku nieoczekiwanego wejścia.
2. Wzorzec strażnika z limitem czasu
Czasem stan musi czekać na zdarzenie zewnętrzne, które może nigdy nie nastąpić. Aby zapobiec nieokreślonej czekaniu, możesz wprowadzić timer. Jeśli zdarzenie nie nastąpi w określonym czasie, wyzwolone zostanie przejście z timeoutem. ⏱️
- Wdrożenie:Dodaj przejście wyzwolone zdarzeniem opartym na czasie (np. „Timer wygasł”).
- Zalety:Gwarantuje, że system zawsze postępuje dalej, nawet jeśli nie jest spełniony główny warunek.
3. Wzorzec stanu równoległego
W złożonych przepływach pracy pojedynczy stan nie może uchwycić wszystkich aktywności równoległych. Regiony ortogonalne pozwalają podzielić stan na wiele niezależnych podstanów. Zmniejsza to złożoność warunków przejść. ⚡
- Wdrożenie:Użyj stanów złożonych z wieloma regionami działającymi równolegle.
- Zalety: Uproszczenie logiki poprzez rozdzielenie odpowiedzialności. Jeśli jedna część zablokowana, druga może nadal działać lub zgłosić błąd.
4. Stan odzyskiwania po błędzie
Zaprojektuj specjalny stan poświęcony obsłudze błędów. Jeśli system wykryje anomalie, natychmiast przechodzi do tego stanu. Stamtąd może spróbować zresetować, ponowić próbę lub ostrzec operatora. 🚑
- Realizacja: Dodaj dedykowany stan „Błąd” lub „Odzyskiwanie”, dostępny z wielu punktów.
- Zalety: Izoluje awarię i zapewnia jasny sposób odzyskania, zamiast pozostawiać system w uszkodzonym stanie.
📊 Porównanie: Zawieszenie vs. Stabilny stan
Aby wizualnie przedstawić różnicę między zdrowym stanem a zawieszeniem, rozważ następującą tabelę porównawczą. Pokazuje ona strukturalne różnice w projektowaniu.
| Cecha | Stabilny stan | Stan zawieszenia |
|---|---|---|
| Przejścia | Istnieje co najmniej jedno poprawne wyjściowe przejście. | Żadne wyjściowe przejście nie spełnia obecnych warunków. |
| Logika warunków | Warunki obejmują wszystkie istotne scenariusze wejściowe. | Warunki są wzajemnie wykluczające się lub niekompletne. |
| Obsługa zdarzeń | Zdarzenia wywołują oczekiwane działania. | Zdarzenia są ignorowane lub powodują zatrzymanie. |
| Odzyskiwanie | System samodzielnie koryguje błąd lub przechodzi do następnej fazy. | System wymaga interwencji zewnętrznej, aby się ponownie uruchomić. |
🧪 Strategie weryfikacji i testowania
Projektowanie to tylko połowa walki. Musisz zweryfikować schemat, aby upewnić się, że wytrzyma obciążenie. Testowanie maszyn stanów wymaga innego podejścia niż testowanie standardowych funkcji. 🧪
1. Sprawdzanie modelu
Sprawdzanie modelu to metoda formalnej weryfikacji. Matematycznie dowodzi, że maszyna stanów spełnia określone własności, takie jak „nie istnieje żaden osiągalny stan, w którym występuje zawieszenie”. Jest to bardzo skuteczne dla systemów krytycznych. 🔢
- Technika: Użyj narzędzi metod formalnych, aby przejść przez całą przestrzeń stanów.
- Wynik: Matematyczna gwarancja, że system nie może wejść w stan zawieszenia.
2. Test pokrycia stanów
Upewnij się, że każdy stan i każdy przejście są testowane co najmniej raz. To nazywane jest pokryciem stanów. Jeśli stan nie jest testowany, nie możesz wiedzieć, czy nie zawiera ukrytego warunku zawieszenia. 🎯
- Technika: Napisz przypadki testowe, które zmuszają system do wejścia w każdy zdefiniowany stan.
- Wynik:Weryfikacja, czy przejścia poprawnie uruchamiają się z każdego punktu wejścia.
3. Testowanie wpływu obciążeń na wejścia
Wyślij nieprawidłowe, puste lub nieoczekiwane dane do systemu. Niezawodna maszyna stanów nie powinna się zawieszać ani awariować przy otrzymaniu złych danych. Powinna albo odrzucić dane wejściowe, albo przejść do bezpiecznego stanu. 🌪️
- Technika: Generuj losowe lub graniczne dane wejściowe i obserwuj zachowanie.
- Wynik:Identyfikacja przypadków krawędziowych prowadzących do zawieszeń.
4. Analiza statyczna
Zanim uruchomisz kod, przeanalizuj strukturę diagramu. Szukaj stanów bez wychodzących strzałek. Szukaj pętli, które nigdy się nie kończą. Narzędzia często mogą automatycznie wykrywać te wzorce. 🔎
- Technika: Uruchom skrypty sprawdzające kod lub analizy statyczne na plikach definicji stanów.
- Wynik:Wczesne wykrycie błędów strukturalnych.
🔄 Obsługa współbieżności i stanów równoległych
Współbieżność zwiększa złożoność. Gdy wiele regionów działa jednocześnie, zawieszenia mogą wynikać z problemów synchronizacji. Musisz upewnić się, że równoległe ścieżki nie blokują się wzajemnie. 🏗️
1. Niezależne regiony
Upewnij się, że stany równoległe są naprawdę niezależne. Jeśli stan A w Region 1 potrzebuje danych ze stanu B w Region 2, wprowadzasz zależność. Ta zależność może stać się węzłem szybkości. 🚧
- Najlepsza praktyka:Minimalizuj współdzielenie danych między ortogonalnymi regionami.
- Alternatywa: Użyj szyny zdarzeń do komunikacji między regionami bez bezpośredniego blokowania.
2. Punkty synchronizacji
Czasem stany muszą być zsynchronizowane. Na przykład region A musi zakończyć działanie przed rozpoczęciem regionu B. Jeśli zaimplementujesz to ręcznie, ryzykujesz zawieszenie. Użyj wbudowanych konstrukcji synchronizacji dostarczanych przez twój framework. ⚙️
- Najlepsze praktyki: Unikaj ręcznych mechanizmów blokowania, chyba że jest to absolutnie konieczne.
- Alternatywa: Użyj stanów połączenia oczekujących na naturalne zakończenie wszystkich przychodzących ścieżek.
⚙️ Działania wejścia i wyjścia
Działania wejścia i wyjścia to fragmenty kodu uruchamiane podczas wejścia do stanu lub jego opuszczenia. Są one częstym źródłem subtelnych zakleszczeń. ⚠️
1. Blokujące działania wejścia
Jeśli działanie wejścia wykonuje długotrwałą operację (np. żądanie sieciowe) bez limitu czasu, system nie może opuścić tego stanu, dopóki operacja nie zostanie zakończona. Jeśli operacja zawiesi się, maszyna stanów również się zawiesi. 🕸️
- Najlepsze praktyki: Zachowaj działania wejścia lekkie i nieblokujące.
- Alternatywa: Przenieś ciężkie zadania do tła i przejdź do stanu „Przetwarzanie”.
2. Nieskończone pętle w działaniach wyjścia
Działanie wyjścia nigdy nie powinno wyzwalać przejścia prowadzącego natychmiast do tego samego stanu. Powoduje to pętlę, która zużywa zasoby bez postępu. 🔄
- Najlepsze praktyki: Upewnij się, że działania wyjścia nie wywołują ponownie tego samego przejścia stanu.
- Alternatywa: Użyj flag, aby zapobiec rekurencyjnemu wywołaniu działań.
📝 Lista kontrolna do przeglądu schematów stanów
Zanim wdrożysz maszynę stanów, przejdź przez tę listę kontrolną. Obejmuje ona kluczowe obszary, w których zakleszczenia najczęściej się ukrywają. ✅
| Punkt sprawdzania | Zdane / Niezdane | Uwagi |
|---|---|---|
| Czy wszystkie stany są osiągalne ze stanu początkowego? | ||
| Czy każdy stan ma co najmniej jedno wyjście? | ||
| Czy wszystkie warunki zabezpieczające są logicznie poprawne (brak luk)? | ||
| Czy istnieją mechanizmy limitu czasu dla stanów oczekiwania? | ||
| Czy regiony równoległe unikają bezpośrednich zależności danych? | ||
| Czy istnieje globalny stan odzyskiwania po błędzie? | ||
| Czy działania wejścia zostały przetestowane pod kątem zachowania blokującego? |
🔍 Głęboka analiza: scenariusze przypadków krawędziowych
Nawet przy dobrym projekcie przypadki krawędziowe mogą się prześlizgnąć. Oto konkretne scenariusze, w których zakleszczenia często pojawiają się w środowiskach produkcyjnych. 🌐
1. Pułapka warunku wyścigu
Gdy dwa zdarzenia zachodzą jednocześnie, kolejność przetwarzania ma znaczenie. Jeśli masz stan przetwarza zdarzenie A przed zdarzeniem B, może się zdarzyć, że wejdzie w ścieżkę prowadzącą do zakleszczenia. Jeśli przetwarza B przed A, może się powieść. ⚡
- Zapobieganie:Kolejkuj zdarzenia i przetwarzaj je sekwencyjnie. Upewnij się, że kolejność zdarzeń nie wpływa na poprawność końcowego stanu.
2. Pułapka wyczerpania zasobów
Stan może czekać na zasób (np. połączenie z bazą danych). Jeśli pulę zasobów wyczerpano, oczekiwanie jest nieskończone. Wygląda to jak zakleszczenie, ale w rzeczywistości jest to problem zasobów. 💾
- Zapobieganie:Zaimplementuj limity czasu połączeń oraz stany alternatywne, które pozwolą na stopniowe zmniejszenie funkcjonalności.
3. Pułapka rozbieżności konfiguracji
Diagram może być zaprojektowany dla stanu A, ale plik konfiguracyjny określa stan B. Jeśli logika przejścia opiera się na wartościach konfiguracyjnych, które brakują, system zatrzymuje się. 📄
- Zapobieganie:Weryfikuj konfigurację względem schematu diagramu stanów podczas uruchamiania.
🚀 Ostateczne rozważania dotyczące solidnego projektowania
Tworzenie maszyny stanów odpornych na zakleszczenia to kwestia dyscypliny. Wymaga przewidywania trybów awarii i projektowania ścieżek obejmujących je. Skupiając się na jasnych przejściach, kompleksowej logice warunków i solidnym obsługiwaniu błędów, tworzysz systemy odpornych na zmiany. 🛡️
Pamiętaj, że diagramy stanów to dokumenty żywe. W miarę zmian wymagań diagram musi się rozwijać. Regularne refaktoryzacje i sesje przeglądu zapewniają, że nowe funkcje nie wprowadzają starych błędów. Zachowaj model prosty, zachowaj logikę jasną i utrzymaj ścieżki odzyskiwania przejrzyste. 🔄
Gdy w fazie projektowania stawiasz na stabilność zamiast na szybkość, oszczędzasz znaczną ilość czasu w późniejszej fazie utrzymania. Dobrze zaprojektowana maszyna stanów to fundament niezawodnego działania oprogramowania. Inwestuj w projektowanie, a system będzie działał spójnie. 📈