











Integralność danych opiera się na przejrzystości. Bez jasnego mapowania ruchu informacji przez system organizacje działają w ciemności. Śledzenie pochodzenia danych dostarcza takie mapowanie, dokumentując podróż danych od źródła po ich wykorzystanie. Schematy przepływu danych są podstawowym językiem wizualnym do tego zadania. Przekładają skomplikowane procesy techniczne na zrozumiałe struktury, pozwalając zespołom śledzić przekształcenia i zależności z precyzją. Ten podejście zapewnia, że każdy fragment danych może być zidentyfikowany, wspierając zgodność z przepisami, debugowanie oraz podejmowanie strategicznych decyzji.
Proces obejmuje więcej niż tylko rysowanie linii między pudełkami. Wymaga głębokiego zrozumienia architektury podstawowej, logiki napędzającej przekształcenia oraz mechanizmów przechowywania danych. Wykorzystując standardowe techniki rysowania schematów, zespoły techniczne mogą tworzyć żywe dokumenty, które ewoluują wraz z infrastrukturą. Niniejszy dokument przedstawia metodologię implementacji śledzenia pochodzenia danych za pomocą schematów przepływu, skupiając się na przejrzystości, dokładności i długoterminowej utrzymalności.
Zrozumienie pochodzenia danych 🧬
Pochodzenie danych odnosi się do historii danych. Zbiera informacje o pochodzeniu, ruchu i przekształceniach, jakie dane przebywają w całym cyklu życia. Wyobraź sobie kroplę wody wchodzącej do systemu rzecznych; pochodzenie śledzi, skąd pochodzi, przez które dopływy przepłynęła i gdzie w końcu wypływa. W kontekście cyfrowym oznacza to wiedzieć, która tabela bazy danych wygenerowała rekord, który skrypt go przetworzył i na którym panelu wyświetlony jest ostateczny metryka.
Ustanowienie pochodzenia danych jest kluczowe z kilku powodów. Po pierwsze, ułatwia rozwiązywanie problemów. Gdy liczba w raporcie wydaje się niepoprawna, pochodzenie pozwala inżynierom śledzić wartość wstecz, aby zidentyfikować, gdzie wystąpiła różnica. Po drugie, wspiera zgodność z przepisami. Przepisy dotyczące prywatności danych często wymagają, by organizacje dokładnie wiedziały, gdzie znajdują się dane osobowe i jak są wykorzystywane. Na koniec, buduje zaufanie. Stakeholderzy są bardziej skłonni polegać na analizach, gdy rozumieją źródło i logikę przetwarzania danych.
Pochodzenie danych można podzielić na dwa główne typy: logiczne i fizyczne. Pochodzenie logiczne opisuje koncepcyjny ruch danych, np. „ID klienta przechodzi z działu sprzedaży do rozliczeń”. Pochodzenie fizyczne szczegółowo opisuje konkretne kroki techniczne, np. „Kolumna 5 z tabeli A jest wyodrębniana za pomocą zapytania SQL B do kolumny 3 tabeli C”. Schematy przepływu skutecznie łączą te dwa aspekty, zapewniając wizualne przedstawienie, które spełnia zarówno stakeholderów biznesowych, jak i inżynierów technicznych.
Rola schematów przepływu danych 📊
Schematy przepływu danych (DFD) to graficzne przedstawienie ruchu danych przez system. W przeciwieństwie do diagramów encji-związków, które skupiają się na statycznych relacjach między obiektami danych, DFDy podkreślają dynamiczny przepływ i przetwarzanie informacji. Rozbijają skomplikowane systemy na zarządzalne elementy, co czyni je idealnym narzędziem do mapowania pochodzenia danych.
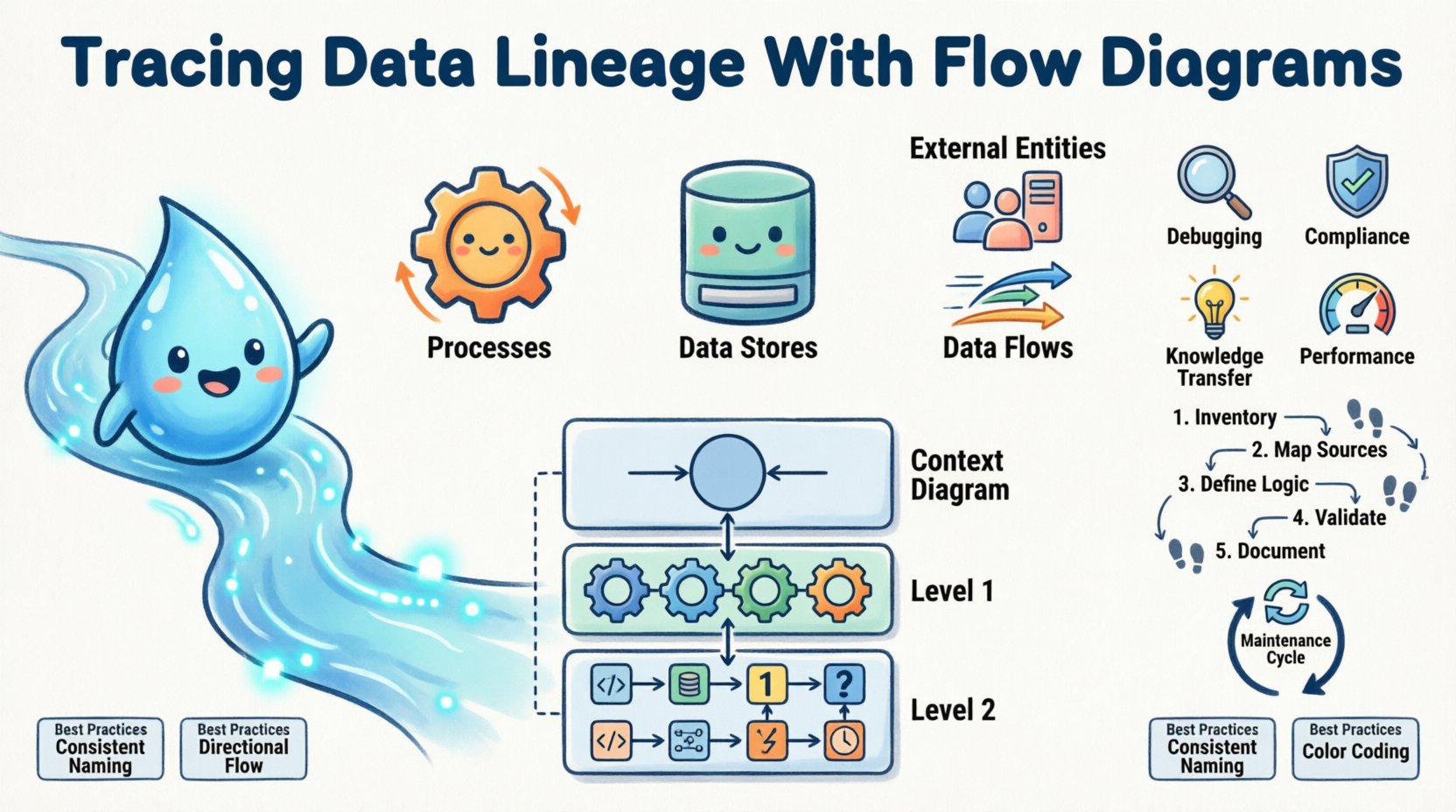
Standardowy DFD składa się z czterech podstawowych elementów:
- Procesy: Działania, które przekształcają dane. Zazwyczaj przedstawiane są jako okręgi lub prostokąty z zaokrąglonymi rogami. Przykłady to „Oblicz podatek” lub „Zsumuj dane sprzedaży”.
- Magazyny danych: Miejsca, gdzie dane są przechowywane. Są to prostokąty otwarte, które reprezentują bazy danych, pliki lub kolejki.
- Zewnętrzne jednostki: Źródła lub miejsca docelowe poza granicami systemu. Użytkownicy, inne systemy lub organy nadzoru często należą do tej kategorii.
- Przepływy danych: Strzałki łączące elementy, wskazujące kierunek i zawartość przepływu danych.
Podczas stosowania do śledzenia pochodzenia danych, te elementy stają się węzłami większego grafu. Połączenia ujawniają ścieżkę. Przestrzeganie standardów DFD zapewnia spójność. Proces w jednym schemacie podlega tym samym zasadom wizualnym co proces w innym, co zmniejsza obciążenie poznawcze dla każdego, kto przegląda dokumentację.
Poziomy szczegółowości schematu 🛠️
Aby zarządzać złożonością, DFDy często tworzy się na różnych poziomach abstrakcji. Ta hierarchia pozwala stakeholderom przybliżać się do konkretnych obszarów, nie zostając przytłoczonym całą architekturą systemu. Standardowy podejście obejmuje trzy poziomy głębi.
| Poziom | Opis | Przypadek użycia |
|---|---|---|
| Diagram kontekstowy (poziom 0) | Przegląd najwyższego poziomu pokazujący system jako pojedynczy proces i jego interakcje z jednostkami zewnętrznymi. | Podsumowania dla kierownictwa i planowanie architektury najwyższego poziomu. |
| Schemat poziomu 1 | Rozdziela główny proces na główne podprocesy i magazyny danych. | Projektowanie systemu i identyfikacja kluczowych punktów dotyku danych. |
| Schemat poziomu 2 | Dalsze rozkładanie konkretnych procesów z poziomu 1 na szczegółowe kroki. | Wdrożenie techniczne, przegląd kodu i szczegółowa audytoria. |
Takie hierarchiczne podejście zapobiega nieczytelności schematu. Strona pokazująca każdy pojedynczy JOIN SQL i wywołanie API byłaby chaotyczna. Zamiast tego, diagram kontekstowy zapewnia ogólny obraz, podczas gdy schematy poziomu 2 oferują szczegółowość potrzebną do zadań inżynierskich. Podczas śledzenia pochodzenia często konieczne jest odwoływanie się do różnych poziomów. Zapytanie w schemacie poziomu 2 może być podsumowane jako pojedynczy proces w schemacie poziomu 1.
Kroki wdrożenia śledzenia pochodzenia 📝
Stworzenie dokładnej mapy pochodzenia wymaga systematycznego podejścia. Nieplanowane rysowanie prowadzi do niezgodności i brakujących połączeń. Poniższe kroki przedstawiają solidny przepływ pracy do tworzenia i utrzymywania schematów przepływu danych w kontekście pochodzenia danych.
1. Zestawienie istniejących zasobów
Zanim zaczniesz rysować, musisz wiedzieć, co istnieje. Zbierz listę wszystkich baz danych, magazynów danych, serwerów aplikacji i narzędzi raportujących. Zidentyfikuj główne źródła danych, takie jak systemy transakcyjne lub zewnętrzne interfejsy API. To zestawienie tworzy granice Twojego schematu. Bez kompletnego wykazu pochodzenie danych będzie miało luki, co prowadzi do nieprzewidywalnych obszarów w zarządzaniu.
2. Mapowanie źródeł danych na miejsca docelowe
Zacznij od źródła. Zidentyfikuj początkowy punkt wejścia danych. Śledź je dalej do pierwszego kroku przetwarzania. Dokumentuj logikę przekształceń. Czy skrypt czyści dane? Czy widok filtruje konkretne wiersze? Zapisz to na poziomie procesu. Kontynuuj śledzenie, aż osiągniesz ostateczne miejsce docelowe, takie jak pulpity BI lub system archiwalny.
3. Zdefiniuj logikę przekształceń
Dane rzadko pozostają stałe. Są agregowane, łączone lub obliczane. Te przekształcenia są kluczowymi punktami w pochodzeniu danych. Dokumentuj konkretne zastosowane zasady. Na przykład: „Wartości null w kolumnie X są zastępowane zerami” lub „Zegary czasu są konwertowane z UTC na czas lokalny”. Taka szczegółowość jest niezbędna do debugowania. Jeśli raport w systemie dolnym pokazuje nieoczekiwane wartości, znając regułę przekształcenia, możesz odtworzyć błąd w środowisku testowym.
4. Weryfikacja z zespołami technicznymi
Schemat narysowany samodzielnie jest podatny na błędy. Przejrzyj szkic z inżynierami, którzy zbudowali potoki danych, oraz analitykami, którzy korzystają z danych. Mogą one zidentyfikować brakujące kroki lub błędne założenia. Ta współpraca zapewnia, że schemat odzwierciedla rzeczywistość, a nie tylko teoretyczny projekt. Weryfikacja jest kluczowym krokiem w utrzymaniu integralności dokumentacji pochodzenia danych.
5. Dokumentuj metadane
Przypisz metadane do elementów schematu. Obejmują one numery wersji, imiona właścicieli i daty utworzenia. Przepływy danych zmieniają się z czasem. Proces może zostać przeprojektowany w kolejnym kwartale. Metadane pozwalają śledzić historię samego schematu, zapewniając, że wiesz, jaka wersja mapy pochodzenia była aktywna w określonym okresie audytu.
Zalety zorganizowanego pochodzenia danych 🏗️
Inwestowanie czasu w szczegółowe schematy przepływu daje rzeczywiste korzyści na całym obszarze organizacji. Korzyści przekraczają proste dokumentowanie.
- Zmniejszony czas debugowania: Gdy występują błędy, inżynierowie spędzają mniej czasu na poszukiwaniu przyczyny. Schemat działa jak przewodnik, wskazując bezpośrednio na prawdopodobny obszar awarii.
- Ulepszona analiza wpływu: Jeśli zaproponowana jest zmiana, np. zmiana nazwy kolumny, mapa pochodzenia pokazuje dokładnie, które raporty i procesy dolnego poziomu zostaną uszkodzone. To zapobiega przypadkowym awariom.
- Zgodność z przepisami: Audytorzy wymagają dowodu obsługi danych. Schematy przepływu zapewniają jasny, wizualny ślad audytowy, który spełnia wymagania dotyczące prywatności i bezpieczeństwa danych.
- Przekazywanie wiedzy: Nowi członkowie zespołu mogą szybko zrozumieć architekturę systemu. Zamiast polegać na wiedzy „plemiennej”, mogą analizować schematy, aby zrozumieć, jak dane przepływają przez organizację.
- Optymalizacja wydajności: Analiza przepływu często ujawnia węzły zatrzasku. Jeśli dane długo czekają w konkretnym magazynie lub procesie, schemat wskazuje, gdzie należy skupić wysiłki na optymalizacji.
Utrzymanie schematów 🔄
Mapa pochodzenia nie jest jednorazowym zadaniem. Systemy ewoluują. Dodawane są nowe źródła danych, a stare procesy są wycofywane. Jeśli schematy nie są aktualizowane, stają się mylące. Utrzymanie dokładności wymaga dyscyplinowanego podejścia do zarządzania zmianami.
Każdorazowo, gdy zmieni się potok danych, schemat powinien zostać przejrzany. Powinno to być częścią listy kontrolnej wdrażania. Jeśli zintegrowano nowe API, należy dodać zewnętrzny element i przepływ danych. Jeśli zmieni się logika przekształceń, opis pola procesu musi zostać uaktualniony. Traktowanie schematu jak kodu zapewnia, że pozostaje wiarygodnym zasobem.
Automatyzacja może wspomagać utrzymanie. Niektóre platformy pozwalają na generowanie schematów na podstawie repozytoriów metadanych. Choć przeglądu ręcznego nadal potrzeba, automatyzacja zmniejsza obciążenie związane z utrzymaniem wizualnej reprezentacji w synchronizacji z rzeczywistością techniczną. Jednak poleganie wyłącznie na automatyzacji może pominąć kontekst biznesowy, dlatego nadzór ludzki nadal jest niezbędny.
Radzenie sobie ze skomplikowaniem ⚖️
Duże przedsiębiorstwa często mają do czynienia z złożonymi ekosystemami danych. Tysiące tabel i setki procesów mogą sprawić, że pojedynczy schemat jest przesadnie złożony. W takich przypadkach kluczowe jest podział na moduły. Podziel pochodzenie na logiczne domeny. Stwórz osobne schematy dla danych sprzedaży, danych klientów i danych finansowych. Połącz je tam, gdzie się przecinają, ale utrzymaj główne widoki skupione.
Innym wyzwaniem jest obsługa systemów dziedzicznych. Starsze systemy mogą nie mieć metadanych potrzebnych do automatycznego śledzenia. W takich przypadkach konieczna jest rekonstrukcja ręczna. Rozmawiaj z pierwotnymi deweloperami lub przejrzyj stare dokumenty, aby wnioskować o przepływie. Być przejrzystym wobec tych luk. Zaznacz obszary niepewności na schemacie, aby wskazać, gdzie potrzebna jest dalsza analiza.
Najlepsze praktyki dla przejrzystości 🚀
Aby zapewnić, że schematy spełniają swoje zadanie, postępuj zgodnie z tymi wytycznymi dotyczącymi projektowania i prezentacji.
- Spójne nazewnictwo: Używaj standardowych nazw dla procesów i magazynów danych we wszystkich diagramach. Unikaj skrótów, które mogą zmylić odbiorców.
- Kierunek przepływu: Ustaw diagramy tak, aby przepływ był logiczny od lewej do prawej lub od góry do dołu. Zgodność z naturalnymi wzorcami czytania.
- Kodowanie kolorami: Używaj kolorów do oznaczania stanu. Na przykład zielony dla aktywnych procesów, czerwony dla przestarzałych i żółty dla tych wymagających przeglądu.
- Warstwowanie: Oddziel widok ogólny od szczegółowego. Nie zatruwaj głównego diagramu każdym pojedynczym mapowaniem pól.
- Kontrola dostępu: Upewnij się, że diagramy są dostępne dla tych, którzy ich potrzebują. Zespół bezpieczeństwa może potrzebować zobaczyć przepływy danych zawierające poufne informacje, podczas gdy deweloperzy muszą zobaczyć implementację techniczną.
Ostateczne rozważania 🔍
Śledzenie pochodzenia danych za pomocą diagramów przepływu to dziedzina łącząca precyzję techniczną z jasną komunikacją. Przekształca abstrakcyjne ruchy danych w konkretne modele wizualne. Przestrzeganie ustalonych standardów i utrzymywanie rygorystycznego cyklu aktualizacji pozwala organizacjom osiągnąć wysoki poziom przejrzystości danych. Ta przejrzystość jest fundamentem nowoczesnego zarządzania danymi.
Wkład potrzebny do tworzenia i utrzymywania tych diagramów przynosi korzyści w postaci zmniejszenia ryzyka i zwiększenia efektywności. Wraz ze wzrostem objętości danych i nasilaniem regulacji, zdolność śledzenia pochodzenia i przebiegu danych stanie się jeszcze bardziej krytyczna. Inwestowanie w jasne i dokładne diagramy przepływu dziś przygotowuje organizację na wyzwania jutra. Celem nie jest tylko dokumentowanie systemu, ale głębokie zrozumienie, by ciągle go poprawiać.